

The enterprise AI agent market is moving fast. Forty percent of enterprise applications will be integrated with task-specific AI agents by the end of 2026, up from less than 5% today, according to Gartner. That adoption curve is compressing years of infrastructure maturity decisions into a window of months. And the tool most engineering teams reach for first — a self-hosted AI agent docker stack built around n8n and Ollama — is the same tool that will quietly fail them when regulated workloads, compliance audits, and production SLAs come calling.
This post is for the teams who have already built something with a hobbyist-grade self-hosted stack, hit real walls, and started asking harder questions. What does "self-hosted" actually need to mean at enterprise scale? And why does the cheapest-looking path so often end up being the most expensive decision?
The appeal is genuine. Tools like n8n offer a capable visual orchestration layer with native LangChain integration, and with over 70 AI and LangChain nodes, native support for OpenAI, Anthropic, Google Gemini, and open-source models through Ollama, n8n lets you build multi-step AI agent workflows that rival custom Python scripts — without writing code for orchestration, error handling, or API retry logic. Pair that with Ollama for local model inference, drop it all into a Docker Compose file, and you have something that looks — on a demo screen, at least — like a production-grade self-hosted AI agent platform.
For individual developers and small teams experimenting with automation, that's a legitimate win. The problems begin the moment you try to take that stack into a regulated enterprise environment.
The first fracture line is structured output reliability. Developers building production agentic workflows quickly discover that local models running through Ollama produce inconsistent results in ways that are incompatible with enterprise automation. After attempting to build with open-source models through Ollama, one developer's results were "all over the map." Outputs were "always unpredictable: sometimes partial JSON, sometimes extra text around the JSON. Sometimes fields would be missing. Sometimes it would just refuse to stick to the structure I asked for." This isn't an isolated edge case. Ollama models have recurring issues handling structured output, especially when used with frameworks like LangChain. Many users report failures to generate valid JSON, model hallucination of format elements, and inconsistent response content — problems stemming from compatibility gaps and incomplete enforcement of output schemas.
For a personal project, you iterate and work around it. For a healthcare workflow processing patient records or a financial agent executing compliance checks, unpredictable output isn't a nuisance — it's a disqualifier. If you're navigating these exact reliability and compliance pressures, our guide to deploying AI agents in production for regulated industries covers the architectural decisions that separate pilots from production-ready systems.
The second fracture line is data sovereignty. This one is more insidious because it's easy to overlook. Self-hosting does not solve data sovereignty for the LLM inference itself. When your n8n workflow calls OpenAI's API, the prompt — including any customer data embedded in it — is sent to OpenAI's US-based infrastructure. Many teams assume that running n8n inside their cloud VPC makes their AI workflows compliant. It does not. The boundary that matters for GDPR, HIPAA, and emerging regulations is where inference happens — not where orchestration runs.
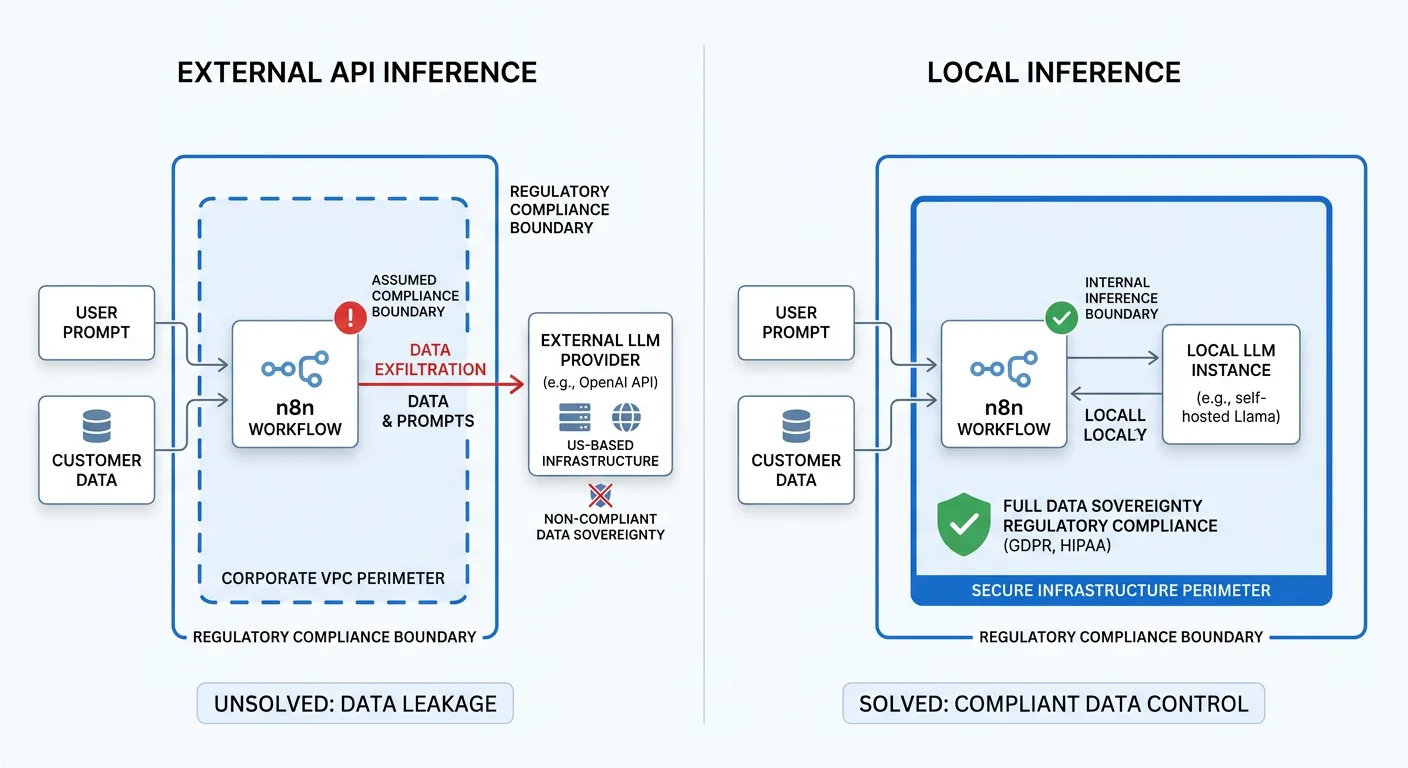
Third: compliance infrastructure simply doesn't exist in these stacks out of the box. n8n and Ollama ship without built-in RBAC, identity-linked audit logging, PII stripping, or documented data governance frameworks. For a developer running personal automation, that's irrelevant. For a hospital, a bank, or a government contractor preparing for audit, those aren't nice-to-haves. Our deep-dive on how to secure n8n workflows for enterprise auditability illustrates just how much bespoke engineering is required to close these gaps in a stack that wasn't designed for them.
The governance gap in DIY AI agent stacks is about to become a legal exposure, not just an engineering concern.
For enterprises operating in or serving the European market, the August 2026 deadline for high-risk AI systems marks the transition from preparation to enforcement — and this includes AI used in employment, credit decisions, education, and law enforcement contexts. Non-compliance with prohibited AI practices can result in fines of up to 35 million EUR or 7% of worldwide turnover — exceeding even GDPR penalty levels.
Compliance requires integrating AI risk into enterprise GRC frameworks, establishing cross-functional governance structures, and implementing technical controls that weren't necessary when AI operated in a regulatory vacuum. A self-hosted AI docker stack with no audit trail, no access controls, and no documented data handling cannot satisfy these requirements. The audit documentation alone — what the EU AI Act calls "design history" — requires systematic, automated logging that typical DIY stacks don't generate.
Analysis of organizational readiness suggests most enterprises face significant compliance gaps as the 2026 deadline approaches. Over half of organizations lack systematic inventories of AI systems currently in production or development — making risk classification and compliance planning impossible. Building a DIY stack deepens this inventory problem rather than solving it.
The compliance risk compounds a broader execution risk. Over 40% of agentic AI projects will be canceled by the end of 2027, due to escalating costs, unclear business value, or inadequate risk controls, according to Gartner. "Most agentic AI projects right now are early stage experiments or proof of concepts that are mostly driven by hype," the firm notes. "This can blind organizations to the real cost and complexity of deploying AI agents at scale."
This isn't a theoretical risk for self-hosted stacks — it's a description of what happens when teams discover that their clever Docker Compose setup has no observability layer, no rollback mechanism, no approval workflow for high-stakes agent actions, and no path to SOC 2 certification. Governance, performance SLAs, and auditability will become mandatory for agentic tools. Infrastructure and operations leaders will need orchestration platforms that connect agents to real execution across enterprise systems.
The irony is that teams reach for DIY stacks to avoid vendor lock-in and preserve flexibility. What they often get instead is invisible lock-in through brittle custom integrations, and "flexibility" that means re-engineering the stack every time a dependency changes or a new model ships.
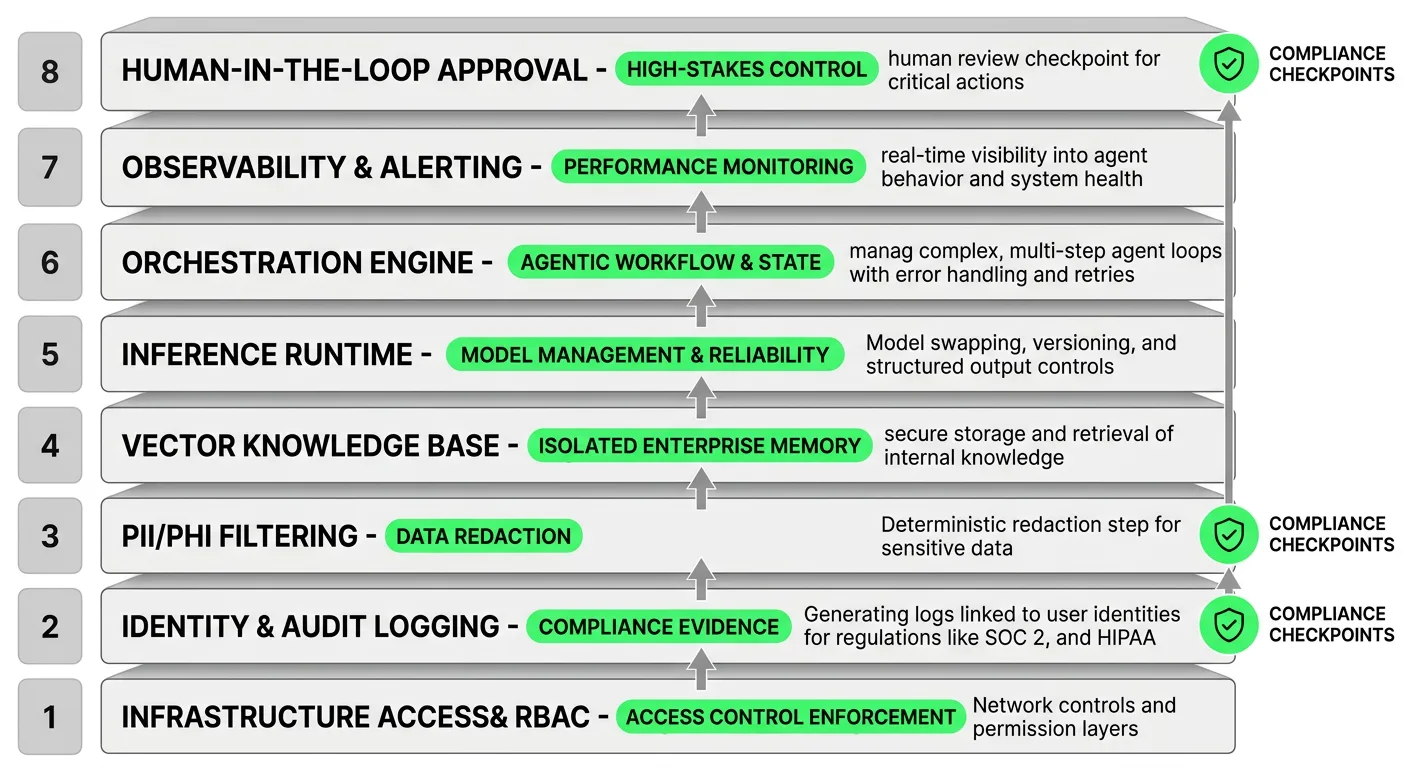
Building a production-ready self-hosted AI agent platform from components requires assembling and maintaining every layer of a complex stack. Consider what actually needs to be in place:
Each of these layers requires engineering expertise and ongoing maintenance. Architecting them from scratch translates to deployment cycles measured in months, not days. For most regulated enterprises, this timeline eliminates the competitive advantage that motivated the self-hosting decision in the first place.
The gap between developer-grade and enterprise-grade self-hosted AI infrastructure shows up most sharply in regulated industries.
In healthcare, every patient data point that enters an AI agent workflow is potentially PHI. A misconfigured Ollama instance calling an external LLM API — even once — can constitute a HIPAA breach with significant legal consequences. Healthcare organizations need PII stripping that happens deterministically at the infrastructure layer, not through prompt engineering.
In financial services, high-risk AI systems in the financial sector must comply with specific EU AI Act requirements by August 2, 2026. Credit scoring algorithms, fraud detection workflows, and customer-facing AI agents all require documented bias assessments, auditability, and explainability that a self-hosted AI agent docker environment cannot provide without substantial bespoke engineering.
In government contracting, data residency isn't a preference — it's a contractual obligation. The requirement is often not just that data stays in a given country, but that it stays on specified infrastructure with documented access controls. The global reach of the EU AI Act means that AI providers and financial institutions operating in or interacting with users in the EU must comply with its requirements, regardless of where they are incorporated or established.
The sticker price of a self-hosted AI agent builder built on open-source tools is low. The total cost of ownership is not.
Consider the engineering hours required to build and maintain each of the stack layers described above. Add the cost of security incidents when controls are missing or misconfigured. Factor in compliance audit costs when documentation doesn't exist. Include the opportunity cost of a 3-6 month deployment cycle that delays production rollout. And consider the organizational risk when Gartner warns that "most agentic AI propositions lack significant value or ROI, as current models don't have the maturity and agency to autonomously achieve complex business goals" — a risk that compounds when governance scaffolding is absent.
DIY makes sense when experimentation is the goal. It stops making sense when the goal is production workloads in regulated environments with real SLAs.
Shakudo was designed specifically for enterprises that have outgrown hobbyist-grade self-hosted tools but cannot accept the data sovereignty and control trade-offs of SaaS AI platforms.
Shakudo deploys entirely within an organization's own cloud VPC — AWS, Azure, GCP, or on-premise — providing the secure, sovereign foundation on which AI agents operate. All data, prompts, and institutional knowledge stay within the customer's perimeter. External LLMs can be used with zero-retention and zero-training guarantees.
Kaji, Shakudo's enterprise AI agent, operates within that already-deployed environment and is built for the exact requirements that DIY stacks leave unmet. Kaji works where teams already collaborate — Slack, Teams, Mattermost — with 200+ prebuilt connections to data, engineering, and business tools, so enterprises aren't rebuilding integrations from scratch. Critically, Kaji is human-in-the-loop by design: it pauses and requests approval before high-stakes or irreversible actions, directly addressing the governance concern that Gartner identifies as the primary cause of agentic AI project cancellation.
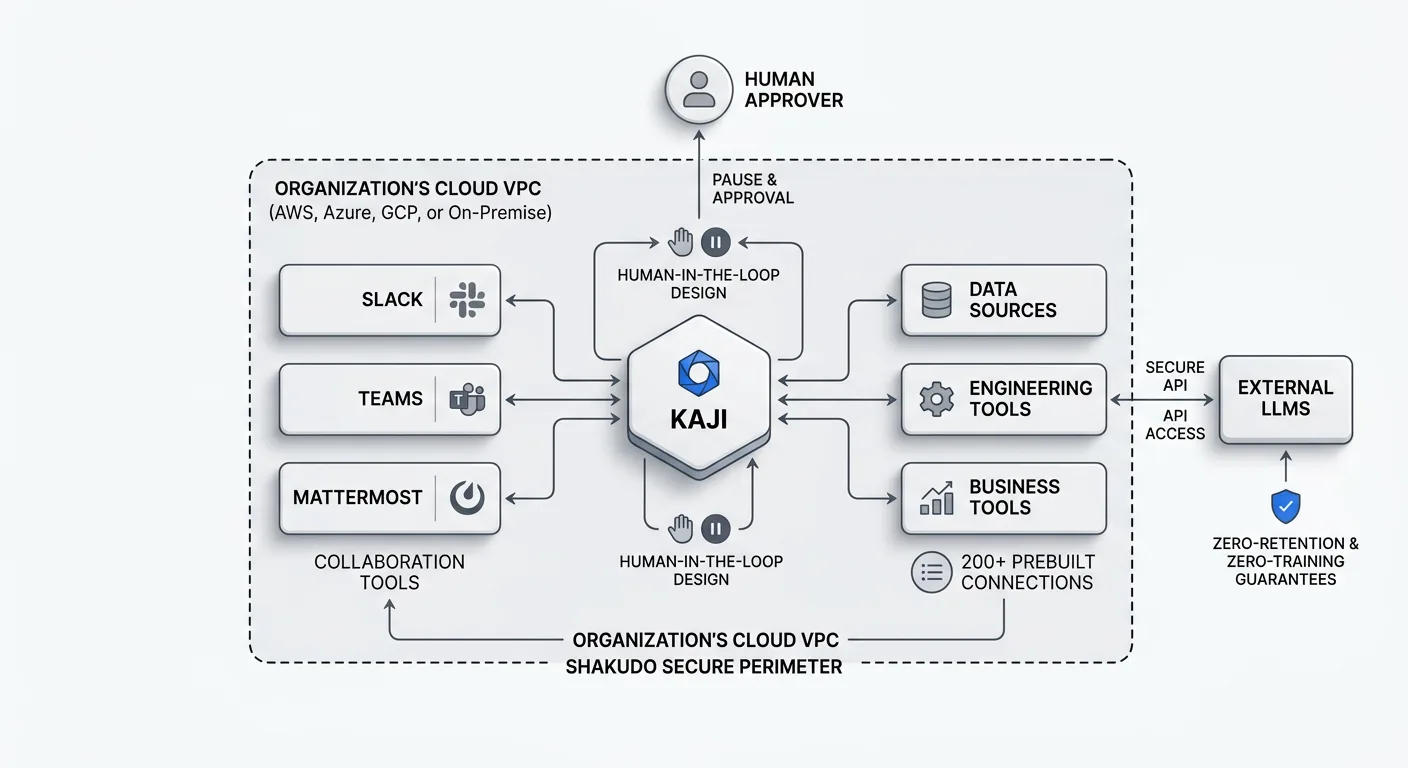
The Shakudo AI Gateway adds the control plane layer that compliance-driven deployments require: deterministic PII/PHI stripping before data reaches external LLMs, identity-linked audit trails for SOC 2 and HIPAA, and organization-wide parameter enforcement baked into the infrastructure rather than bolted on afterward.
For teams evaluating a self-hosted AI agent platform against the realities of regulated production deployment, the question isn't whether to self-host — it's whether the self-hosting approach you choose can actually satisfy the compliance, auditability, and reliability requirements your organization faces.
If you're currently running an n8n and Ollama stack in a development or pilot capacity, here is a practical way to assess your readiness gap:
Self-hosted AI agents are absolutely the right strategic direction for enterprises that need data sovereignty and regulatory control. The question is whether the stack you're building can survive first contact with your compliance team — and with the EU AI Act enforcement deadline that is now months away, not years.
The answer, for most DIY stacks, is no. The answer for a purpose-built enterprise AI infrastructure is different. If you're ready to explore what production-grade sovereign AI deployment actually looks like, Kaji is worth a closer look.




















