

Note: This article is a followup to our previous post on using Milvus for knowledge base management. We recommend that you read that post first if you would like to implement the chatbot described here.
Chatbots have improved by leaps and bounds in the past few years thanks to the advent of easily accessible LLMs. General LLM-based chatbots can be quite entertaining in their own right, but with proper tuning, they can also be a way to significantly improve productivity.
Why read web articles all day to parse through endless fluff in order to find the tiny nuggets of information that make all the difference? Instead, let the LLM summarize what’s new and guide you to find what you’re looking for.
Or how about parsing through the last decade’s worth of internal business documents to identify patterns, like which sectors will most be affected by ongoing weather events based on a collection of document sources, or recall details, such as who logged into the admin database at around 3 AM last December, without having to guess at which keywords will turn out the best results, or risk missing critical details?
Perhaps you have a collection of complicated texts from which you need a simple answer: Based on the National Bank of Canada’s last 12 quarters of financial documents, is their revenue increasing or decreasing?
Modern chatbots can do all that when leveraging retrieval-augmented generation. In this blog post, we will build such a system, using Llama2 to generate our answers, Milvus to store our documents and perform quick vector searches to identify relevant documents, and Shakudo to bind it all together without having to endure complicated setup or rely on expert IT skills.
Retrieval-augmented generation, or RAG, is the task of generating text (generation) based on a document related to the query or search context (retrieval-augmented). There are many ways to architect a RAG system. Here, we will stick to a straightforward method based on prompt injection, discussed later in this post.
Our system will have the following features:
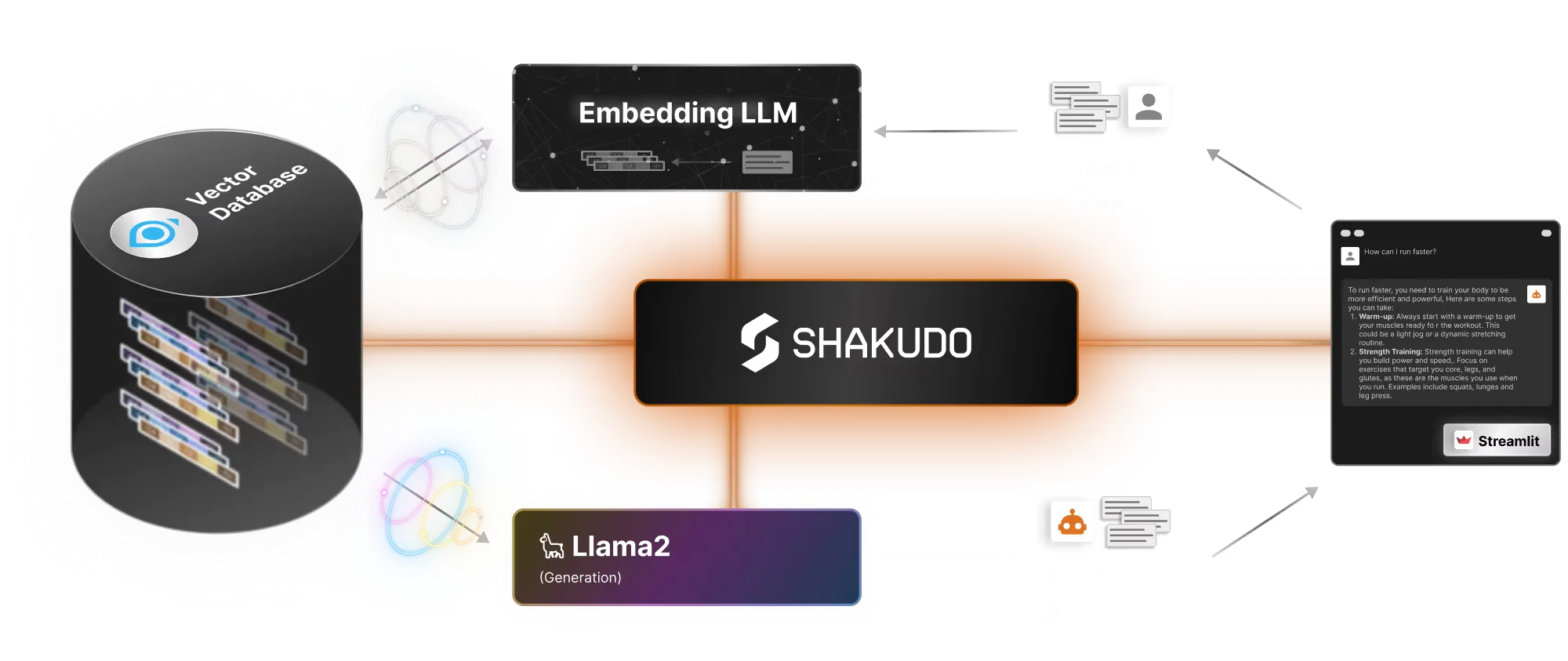
To achieve semantically relevant search results and a pleasant chat experience with limited response delays, we will leverage Milvus’s highly efficient vector search capabilities. Since running everything we need (Llama2, Milvus, and our frontend) on one computer is rather difficult, and since setting up everything on a few devices could be the subject of its own blog post, we will leverage Shakudo to effortlessly access everything we need instead. As a bonus, our chatbot will scale seamlessly when we are ready to deploy it.
We will be using the same database that was setup in our previous post on Milvus for this demo, with the WikiHow dataset. Our chatbot will be able to give us tips on how to run faster or how to handle spicy food better. In addition, we will have access to the source document from which our Llama2 generated its answer, allowing users to double check anything interesting they may discover through our chatbot.
Since we have already covered how to insert our data into Milvus, we’ll assume the database of interest is ready for further operations. We simply have to create the collection and load the collection, as before:
With this, our data is ready to be searched against, no additional setup required. As a reminder, we use the alias of ‘default’ because this saves us some typing, as this is the default connection reference name for other pymilvus functions.
We can test that we get reasonable results by doing a simple search against the database, as we did in our previous post, by defining our embeddings to match those we used when uploading data to Milvus like this:
And then performing the search proper:
Let’s see the result!
As expected of Milvus, blazing fast response and pretty great results!
Now that we can retrieve useful documents from our knowledge base, let’s hook the retrieved results into our generation system. First, we need a running instance. On Shakudo, this is just a question of launching a service:
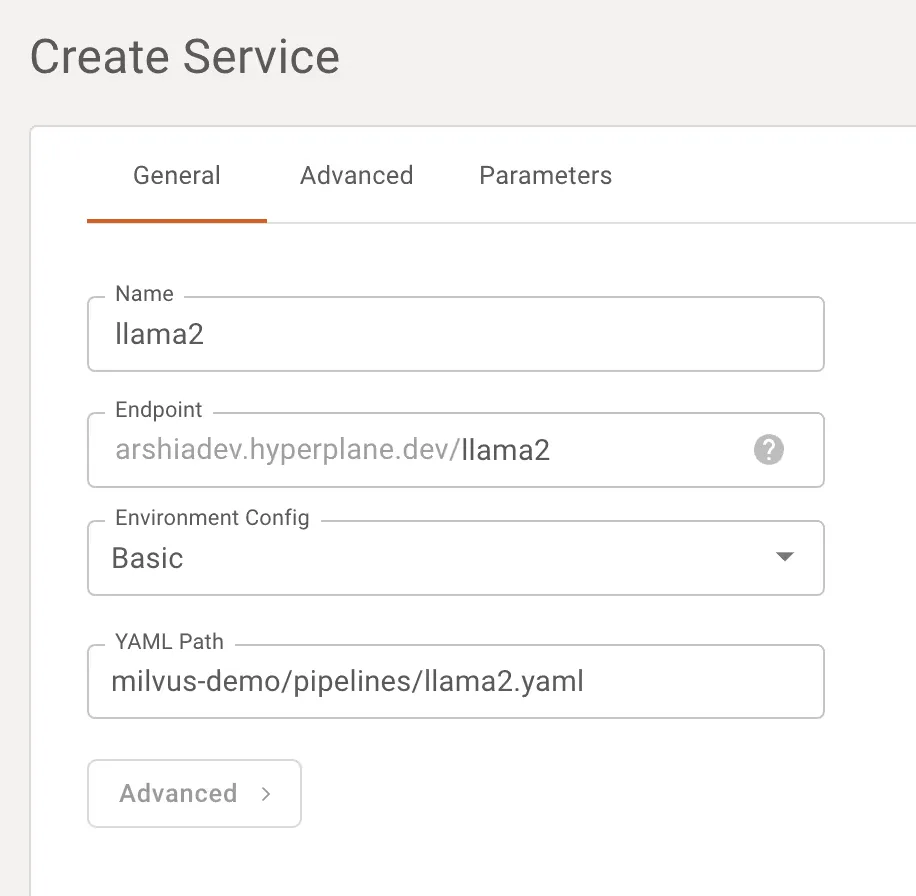
Let’s connect to our LLM endpoint and make sure everything is up and running:
You may notice that we don’t simply use the query as prompt, but have to perform mild prompt engineering. That is because GPTs like Llama2 are trained with text completion objectives, not as dialogue systems. Therefore, it is important to ensure the prompt format matches the dialogue text corpora the model will have seen during training. Variations are acceptable as long as the basic format is followed (so for example, results may be a little worse, but will still resemble dialogue if using ROBOT: instead of ASSISTANT:, and so on).
Trying out this query returns us an interesting response, although probably not what we had in mind when asking the question:
There are several solutions to fix generations like these, including using a larger model, modifying the prompt format used, or performing sampling and optimizing generation parameters to achieve the desired results.
All these methods are compatible with knowledge grounding, as we’ll do in this post, though they fall outside our scope this time. Additionally, knowledge grounding is very effective and far cheaper to implement than finetuning, which requires ready access to GPUs even with modern, parameter efficient techniques like LoRA QLoRA. It also doesn’t require additional effort when modifying knowledge base data.
We will have to prepare a prompt template to insert previous user turns and the document from the knowledge base that is most relevant to the input query:
While a discussion of the pros and cons of various models is not in scope for this post, it’s worth experimenting a bit to find what works best for your use case. For this demo, we found that Llama2-7b provided lukewarm results, but at 13 billion parameters, responses became quite natural in a lot of cases. In addition, finetuned models can provide better results, though as a rule of thumb, finetuning reduces general performance while improving task-specific performance.
Without further ado, let’s tie everything up and try our previous query again:
Much better! This is the kind of response we would have liked the first time around.
The generation function to obtain this response looks like this:
This will be a very short step since we’re using Shakudo and Streamlit. All we have to do, in essence, is copy our notebook into a python file and wrap it in Streamlit UI elements. The full code can be found here The configuration and run script are fully reproduced here since they’re so tiny.
To deploy our RAG on Shakudo, we first create the following files:
run.sh:
pipeline.yaml:
Then we simply create a service on Shakudo, pointing to the yaml we use for this task:
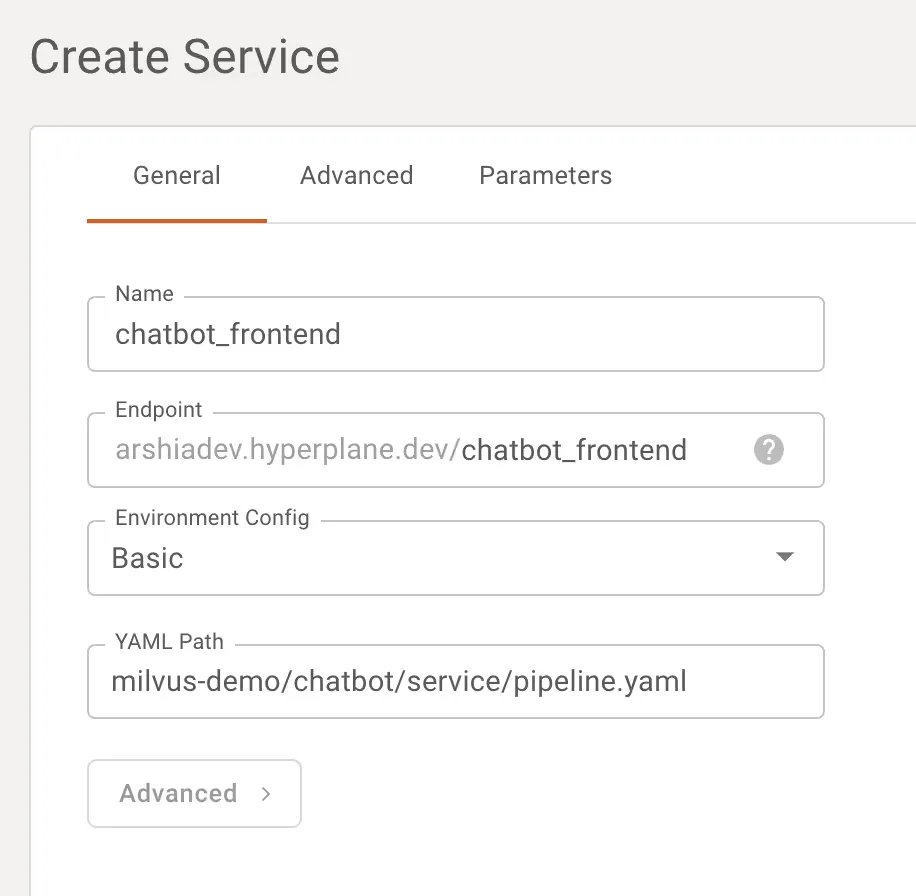
When the service is ready, we simply have to click the link that appears in the service section, and land on our user-friendly RAG:
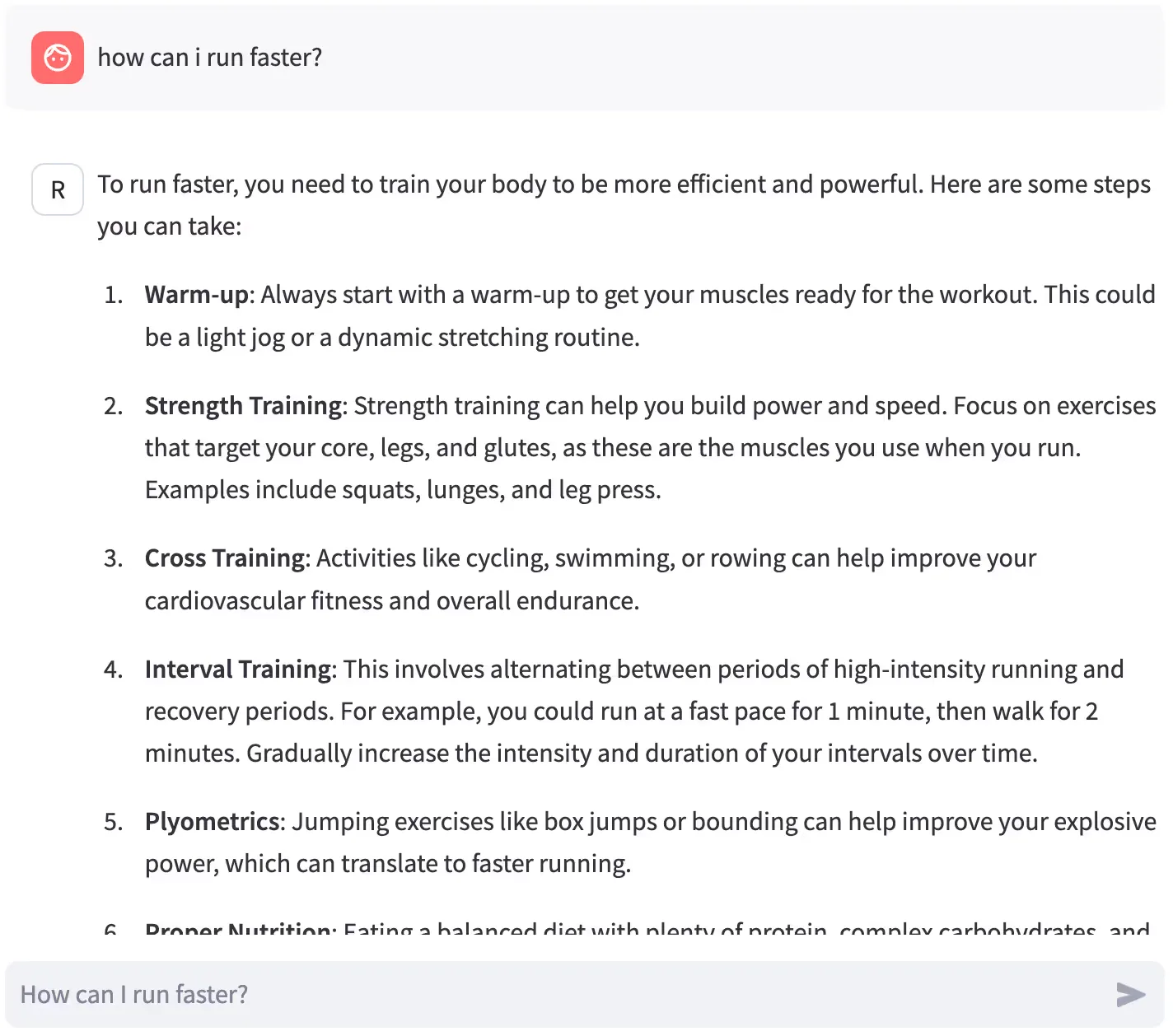
That’s it! If you enjoy a good laugh, you are cordially invited to visit the Streamlit documentation on deploying with Kubernetes. Feel free to compare the configuration above with the proposed configuration in the official document. Shakudo makes a world of difference in this, and in all other configuration and management tasks for LLM use cases.
If you would like to toy with our RAG yourself, you can find the notebook and service files at this link.
Armed with the information in this post, you are now ready to prototype your own LLM-powered question-answering system leveraging your own private business data, without having to worry about your documents reaching third party servers as would be a concern when using third party hosted LLMs.
A lot of work remains to finetune the method and interface to achieve the answers you would like with your own branding at the scale that matters to you, but this is where Shakudo comes in: Shakudo allows you to deploy services that automatically scale up and down with usage, and takes care of all the configuration work required to interoperate the many moving pieces involved in creating robust RAGs. Focus on developing business value, not on tool, environment, and configuration management!




















