

The enterprise AI race has quietly shifted from a model problem to an infrastructure problem. Organizations that had GPT-4 access a year ago are not meaningfully ahead of organizations that have it today. What separates the 2% of enterprises running agents at full production scale from the 98% still experimenting is the stack underneath the agent — and most technical leaders have not yet mapped it clearly.
Forty percent of enterprise applications will be integrated with task-specific AI agents by the end of 2026, up from less than 5% today, according to Gartner. That is an eight-fold expansion in twelve months, and Gartner's best-case scenario projects that agentic AI could drive approximately 30% of enterprise application software revenue by 2035, surpassing $450 billion, up from 2% in 2025. Yet the path from pilot to production is not paved with better prompts. It is paved with architectural decisions made — or not made — at each layer of the ai agent infrastructure stack.
Over 40% of agentic AI projects will be canceled by the end of 2027, due to escalating costs, unclear business value, or inadequate risk controls, according to Gartner. "Most agentic AI projects right now are early stage experiments or proof of concepts that are mostly driven by hype and are often misapplied," said Anushree Verma, Senior Director Analyst at Gartner.
The failure mode is usually not the AI model itself. One of the primary use cases for early agentic AI tools was plastering over the intrinsic limitations of LLMs in planning, context management, memory management, and orchestration — and until recently, this was largely done with "glue code," manual and brittle scripts used to wire different components together. Scaling brittle scripts is not a strategy. Building a proper ai agent infra stack is. The most common AI orchestration mistakes enterprises make are rarely about model selection — they are about the foundational layer decisions that compound into months of rework.
For regulated enterprises in healthcare, finance, and government, the stakes compound further. The EU AI Act's high-risk system rules take full effect in August 2026, requiring comprehensive logging, traceability, and policy enforcement at the infrastructure layer. Stack design is no longer a technical preference — it is a compliance mandate.
The enterprise AI agent infrastructure stack is not a single product you buy. It is a set of interdependent layers that must function coherently. Here is how practitioners should think about each tier.
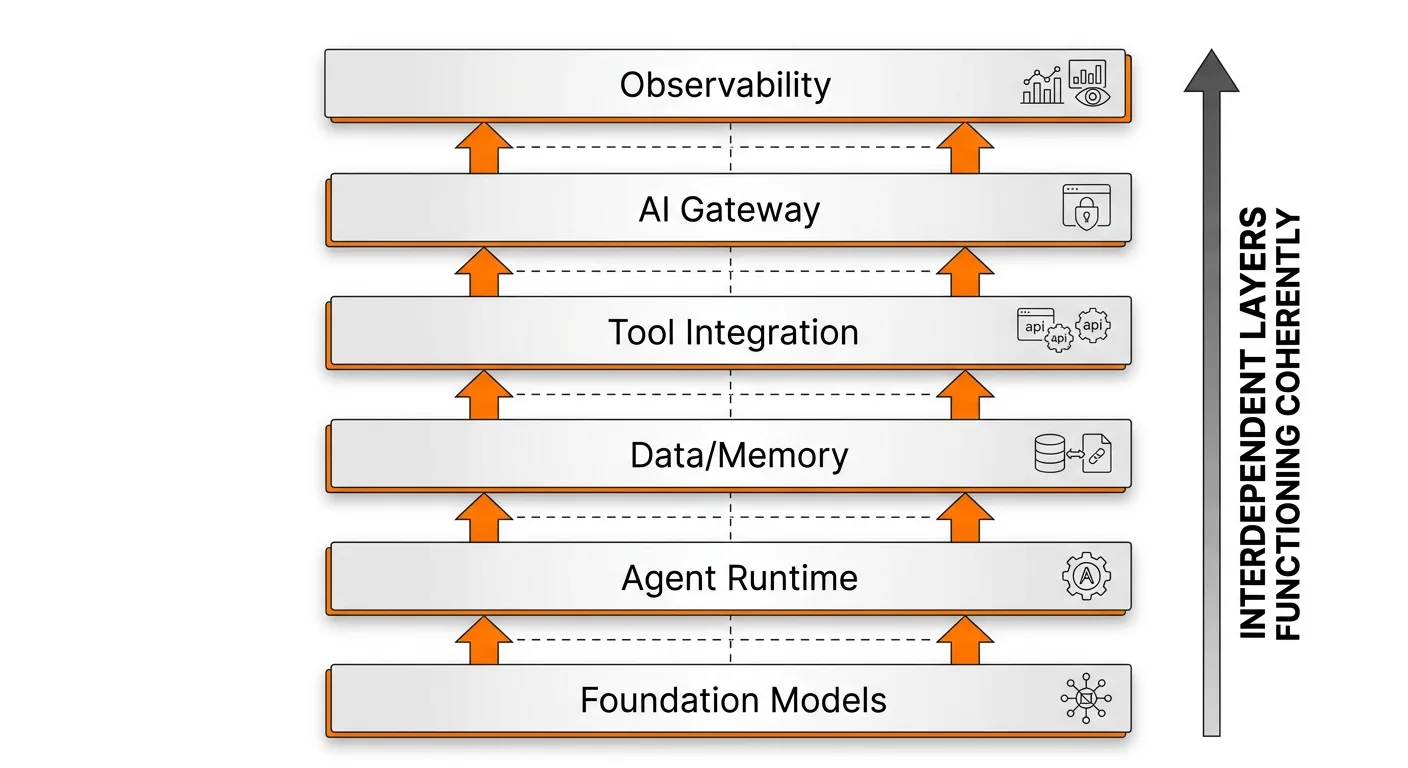
In 2026, foundation models are no longer standalone tools but function as interchangeable components within the enterprise AI stack. Organizations assess models based on workload alignment, latency, cost efficiency, compliance, and deployment flexibility. The model is increasingly a commodity input. Multi-model routing is standard in advanced AI platforms, optimizing performance and reducing vendor dependency.
The practical implication: architect your stack so the model layer is swappable. The relative technical ease of switching between LLM vendors creates a false sense of security, but the battle is shifting from models to ecosystems. Model providers are aggressively building proprietary platforms that provide agent frameworks, development tools, and data integration — and connecting enterprise data and building agents within their walls can leave organizations trapped. Once operational data and business context are deeply embedded in a vendor-specific ecosystem, migration costs become astronomical.
This is where the most consequential infrastructure decisions happen, and where most enterprises stall. Agents coordinate reasoning, tool execution, memory retrieval, and task delegation, introducing stateful logic into previously stateless environments. This agent layer transforms LLM capabilities into operational systems, enabling real-world execution instead of isolated outputs. By 2026, agent orchestration is a structural requirement for the enterprise AI stack.
The orchestration layer manages multi-step workflows, handles agent-to-agent communication, enforces retry logic, and routes tasks across specialized agents. Traditional pipeline-based architectures fail here because agentic systems demand shared memory, orchestration layers, and real-time context flow to scale effectively. Without a production-grade orchestration layer, every new agent added to an enterprise environment adds fragility rather than capability. Understanding how to deploy AI agents in production for regulated industries requires treating orchestration as a first-class infrastructure concern from day one.
Vector databases, structured data connectors, and graph-based relationships form the backbone of modern retrieval systems. Persistent memory layers enable agents to maintain continuity across workflows, supporting multi-step reasoning and long-term contextual awareness. In the modern enterprise AI stack, data architecture is as critical as model performance.
Dedicated agent memory layers are predicted to become standard infrastructure in 2026, much as vector databases became standard in 2024. Agents without persistent memory cannot maintain context across sessions, cannot accumulate institutional knowledge, and cannot build the organizational intelligence that compounds over time.
Data quality is not optional here. Data quality cannot be overstated, especially if the goal is to enable agents to make recommendations or decisions. "As we move toward ambient agents that are autonomous, this will introduce significant risk due to data quality leading to poor decisions," warned one enterprise AI architect.
AI agent tool integrations connect agents to external software — CRMs, HRIS platforms, ticketing systems — enabling real-world actions. An agent reasoning but unable to act is merely a chatbot. The tool integration layer transforms LLMs into systems that read CRMs, update tickets, and trigger workflows.
The Model Context Protocol (MCP) has emerged as the connective tissue for this layer. The Model Context Protocol is an open standard introduced by Anthropic in November 2024 to standardize the way AI systems like large language models integrate and share data with external tools, systems, and data sources. The adoption curve has been steep: with over 5,800 available servers, 97M+ monthly SDK downloads, and adoption by OpenAI, Google, and Microsoft, MCP has become the de facto industry standard for agentic AI integration in enterprise environments.
The practical benefit is architectural. Enterprise AI deployments previously faced what's called the "N times M problem." If you have N different AI models that need to connect with M different business systems, you theoretically need N times M custom integrations. Five AI platforms connecting to twenty enterprise tools means one hundred integration projects — making enterprise AI adoption expensive and slow. MCP collapses that burden considerably. A deeper look at how MCP works in enterprise environments illustrates why standardized tool connectivity has become a prerequisite for scalable agent deployment.
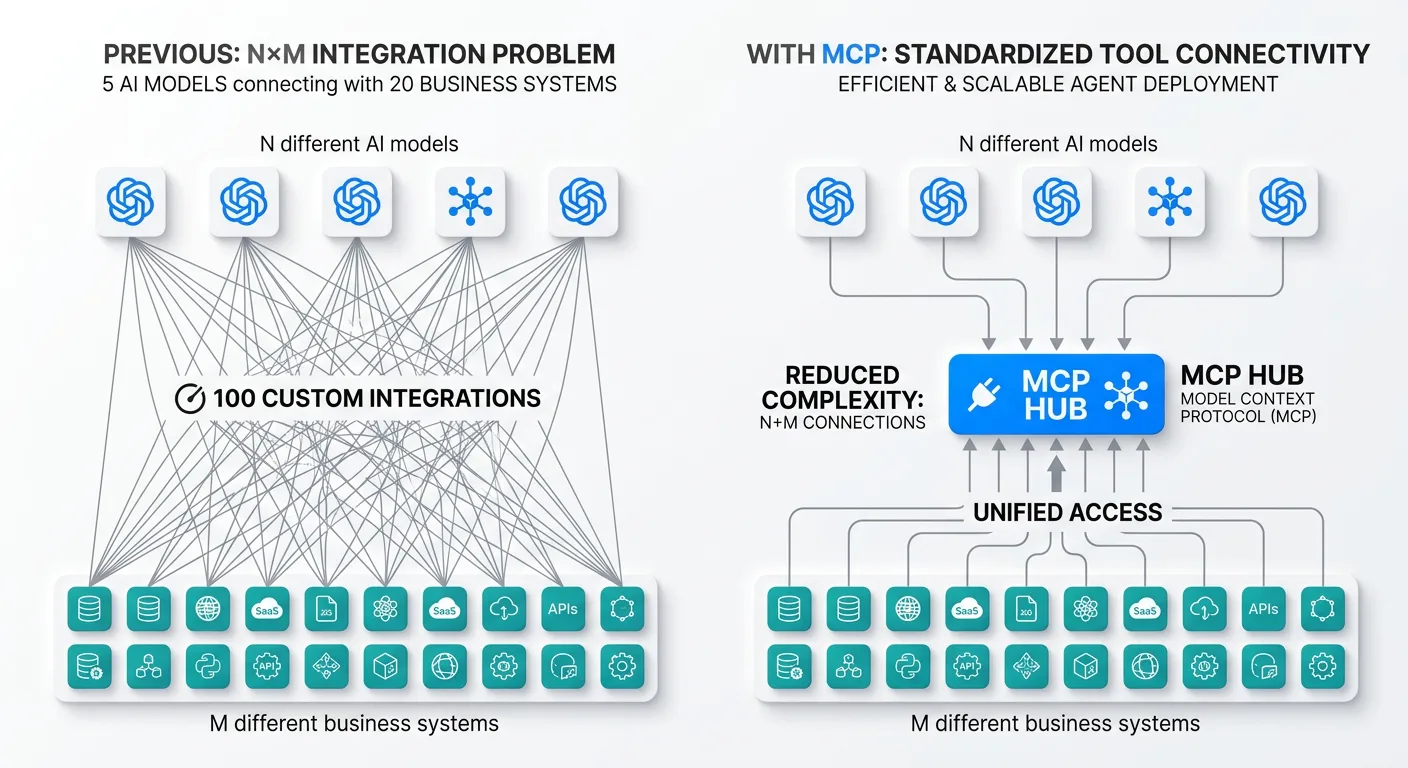
Early enterprise results are instructive. Block built an internal AI agent called Goose that uses MCP to connect across GitHub, Jira, Snowflake, and internal systems, with thousands of employees using it daily and reported time savings of 50–75% on common tasks. Bloomberg adopted MCP organization-wide and reported reducing time-to-production from days to minutes for new AI integrations.
As agent-to-system and agent-to-agent interactions multiply, a policy enforcement point sitting between agents and models becomes critical infrastructure. Engineering teams now juggle multiple LLM providers — OpenAI, Anthropic, Google Gemini, AWS Bedrock, Mistral — each with different API formats, authentication schemes, rate limits, and pricing models. Without a unified control plane, enterprises face vendor lock-in, unpredictable costs, zero failover coverage, and compliance blind spots across their AI stack.
The AI gateway layer solves this. It enforces organization-wide policies at the infrastructure level rather than inside individual agent codebases, handles PII and PHI stripping before sensitive data reaches external models, and maintains the audit trails that SOC2 and HIPAA compliance require. Enterprises need to verify that the right people and models can call the right tools with the right permissions. They must track which servers are running, what versions they use, and what actions they perform. They need automated scanning, signing, and certification to confirm each server is secure and compliant — and they must be able to observe and audit tool calls in real time.
By 2026, evaluation is embedded within the enterprise AI stack instead of being added after deployment. Tracing, benchmarking, regression testing, and real-time monitoring ensure reliability at scale. Observability frameworks enable teams to measure reasoning quality, latency, and failure patterns across agent workflows.
For regulated industries, governance is not a reporting afterthought. Enterprise deployment requires governance built into the architecture from day one, ensuring every agent action remains traceable, explainable, and aligned with business goals through comprehensive lifecycle management. Without full traceability, compliance teams cannot audit decisions, legal teams cannot defend outcomes, and security teams cannot detect anomalous agent behavior.
The stakes are asymmetric for healthcare, financial services, and government organizations. Some of the most useful data for enterprise workflows faces privacy and security concerns, and this is likely to drive investment in privacy-preserving techniques such as secure enclaves, federated learning, homomorphic encryption, and multiparty computation.
Sovereign deployment — where the entire agent infrastructure runs within an organization's own cloud VPC or on-premises environment — is increasingly the only viable option for these enterprises. Sending patient records, financial transactions, or classified government data through external public AI APIs is architecturally untenable under GDPR, HIPAA, and the EU AI Act.
This is not merely a compliance constraint. Smart companies will architect their AI stack to keep their data separate from AI tooling. This decoupling ensures data remains portable and allows organizations to switch AI vendors without a devastating divorce. Sovereignty and portability are the same design principle expressed at different timescales.
Across the layer analysis above, a pattern emerges. The enterprises that move from pilot to production share several infrastructure characteristics:
The stack is layered and interdependent: models provide capability, agents enable execution, data ensures contextual relevance, and infrastructure guarantees scale and governance. Weakness at any layer propagates upward.
The orchestration and deployment layer is precisely where most enterprises stall — and it is where Kaji, Shakudo's enterprise AI agent, operates.
Kaji runs within Shakudo's AI operating system, which deploys entirely within an organization's own cloud VPC (AWS, Azure, GCP) or on-premises infrastructure. All data, prompts, and institutional knowledge remain inside the enterprise perimeter. External LLMs can be used with zero-retention and zero-training guarantees, addressing the sovereignty constraint that regulated industries cannot compromise on.
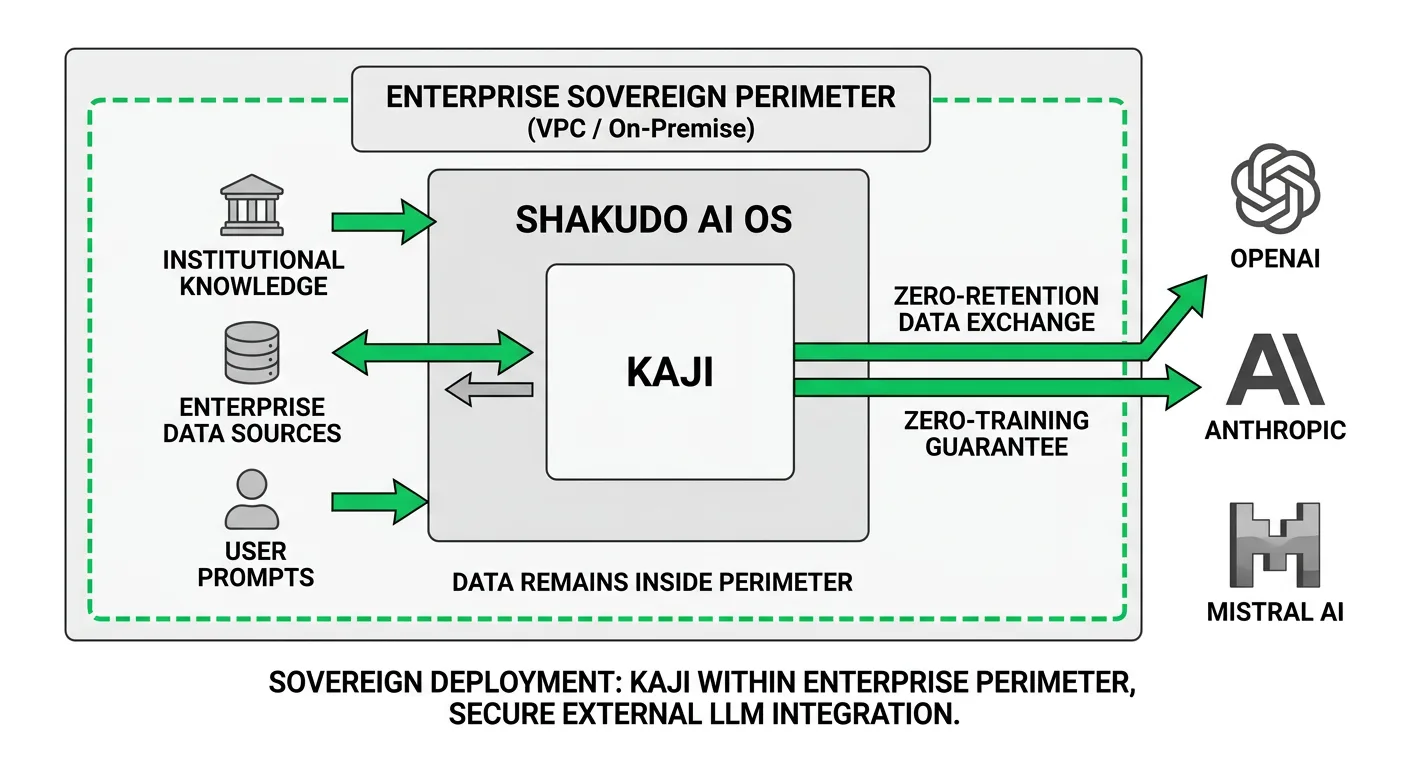
For the tool integration layer, Shakudo's AI Gateway aggregates all internal MCP tools into a single endpoint, hardcodes organization-wide policy parameters, strips PII and PHI from payloads before they reach external models, and maintains a permanent identity-linked audit trail for SOC2 and HIPAA compliance. Rather than scattering governance logic across individual agent codebases, the gateway enforces it as infrastructure.
Kaji itself brings 200+ prebuilt connections to data, engineering, and business tools — and operates where teams already work, in Slack, Teams, and Mattermost, with no new interface to learn. Human-in-the-loop controls are built in by design: Kaji pauses and requests approval before high-stakes or irreversible actions, which is the governance pattern that separates trustworthy production agents from unsanctioned automation.
For engineering and IT leaders mapping their ai agent infrastructure stack, the relevant question is not which individual components to evaluate — it is how quickly a pre-integrated platform can compress the distance between architecture decision and running agents. The difference is typically measured in months.
The infrastructure reckoning of 2026 is not a failure of AI — it is a sign of its progress. Production AI systems are finally demanding enough to expose the weaknesses in enterprise data foundations. The companies that invest now in protocols, governance, vendor independence, and scalable architectures will gain decisive advantages as AI moves from experiment to operational core.
The ai agent infrastructure stack is not a background concern that engineering teams address after the business case is proven. It is the business case. Organizations that get the stack right — sovereign, observable, governed, and properly orchestrated — will compound their lead as agent deployments scale. Organizations that defer the architecture work will find themselves rebuilding from a fragile foundation, measured in costly months and canceled pilots.
The stack will not simplify itself. But it can be built deliberately, one layer at a time, with the right infrastructure underneath it.




















