

42% of companies scrapped most AI initiatives in 2025, up from 17% in 2024, with nearly half of proof-of-concepts abandoned before production. Behind these failures lies a common culprit that few organizations anticipated: poor AI orchestration.
While companies obsess over model accuracy and data quality, they overlook the operational infrastructure that determines whether AI ever leaves the lab. Orchestration mistakes—from agent sprawl to infrastructure mismanagement—are quietly draining budgets, delaying deployments by months, and turning promising pilots into expensive write-offs.
AI transformation is only 10% technology and 20% data, but 70% change management, yet very few enterprises have industrialized delivery at scale with the operating model, data foundations, governance, and change management capabilities required to make AI durable.
The problem isn't that AI doesn't work. It's that organizations lack the connective tissue to move it from experiment to production reliably. Over 85% of AI projects fail due to a lack of operational infrastructure, which hinders the transition of models from experimentation to production, making models hard to scale, monitor, or manage.
Seven orchestration mistakes account for the majority of these failures. Each represents a predictable pattern that costs enterprises millions while extending time-to-value from weeks to quarters.
One of the biggest challenges of scaling AI at enterprises is the risk of agent sprawl, when enterprises end up producing dozens or hundreds of AI agents without a centralized way of organizing them.
Teams across departments build specialized agents independently. Marketing creates a customer outreach agent. Sales builds a lead qualification agent. Support develops a ticket routing agent. Each works in isolation, but nobody tracks what exists, what agents access, or how they interact.
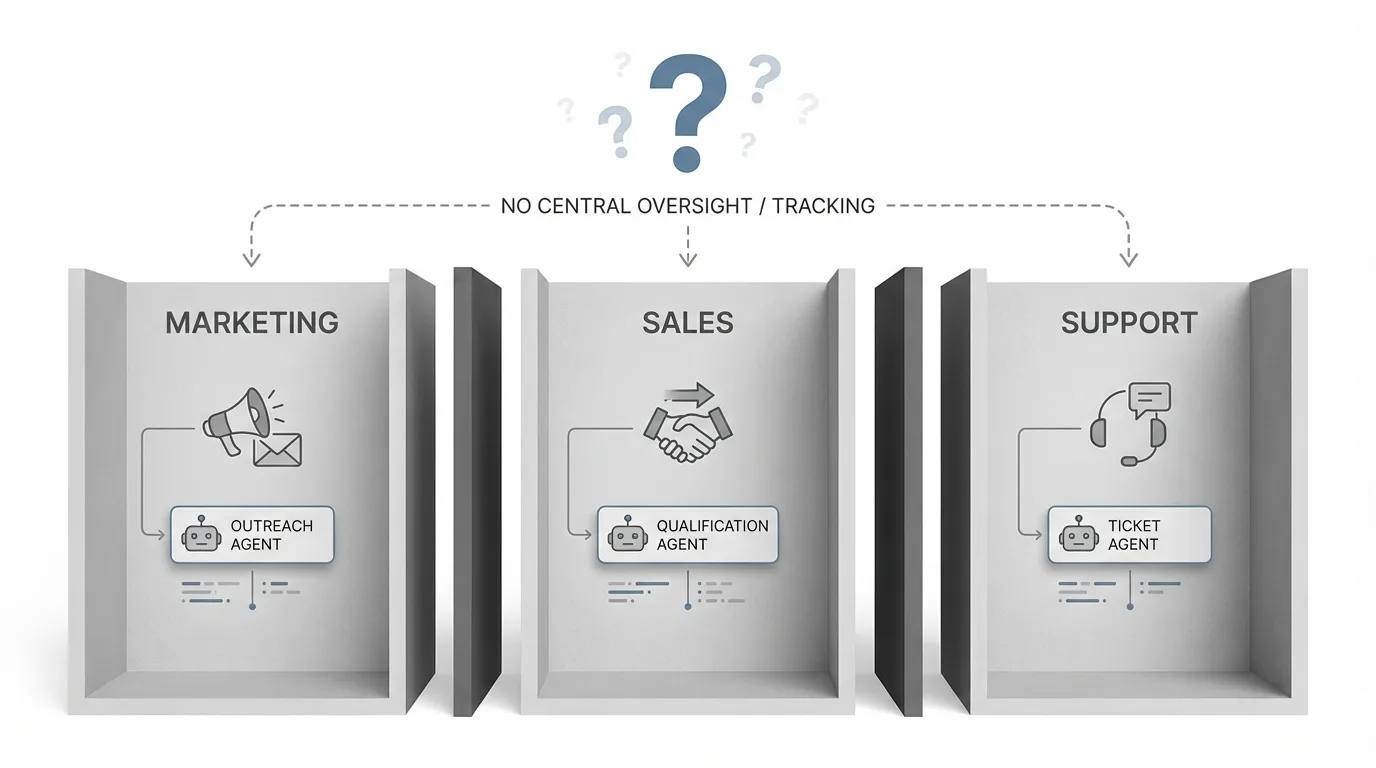
AI sprawl happens when organizations deploy agents in silos, with each agent connecting to a handful of apps creating fragmented pockets of automation, teams launching agents outside IT's purview with unknown prompts and data flows, and inconsistent access controls where some agents have admin rights with no consistent policy enforcement.
There's a real risk of agent sprawl, the uncontrolled proliferation of redundant, fragmented, and ungoverned agents across teams and functions, as low-code and no-code platforms make agent creation accessible to anyone, creating a new kind of shadow IT.
Organizations built horizontally when they needed vertical wins, with their instinct to platformize early with agents, frameworks, shared services, reuse, and extensibility. From an architecture perspective, this seems correct. From an enterprise change perspective, it dilutes perceived impact.
Executives don't fund infrastructure—they fund outcomes, responding to end-to-end stories showing that a class of cases is now resolved 30% faster with fewer escalations and higher satisfaction. Instead, they see slices: better logs, better suggestions, incremental improvements spread across workflows.
When AI teams spent 2025 building platforms, they delivered pieces of value distributed across many workflows, rather than concentrated, measurable impact in one critical area.
Successful orchestration requires the opposite approach. Start with one high-impact use case. Prove concrete ROI. Then scale the orchestration infrastructure that made it possible.
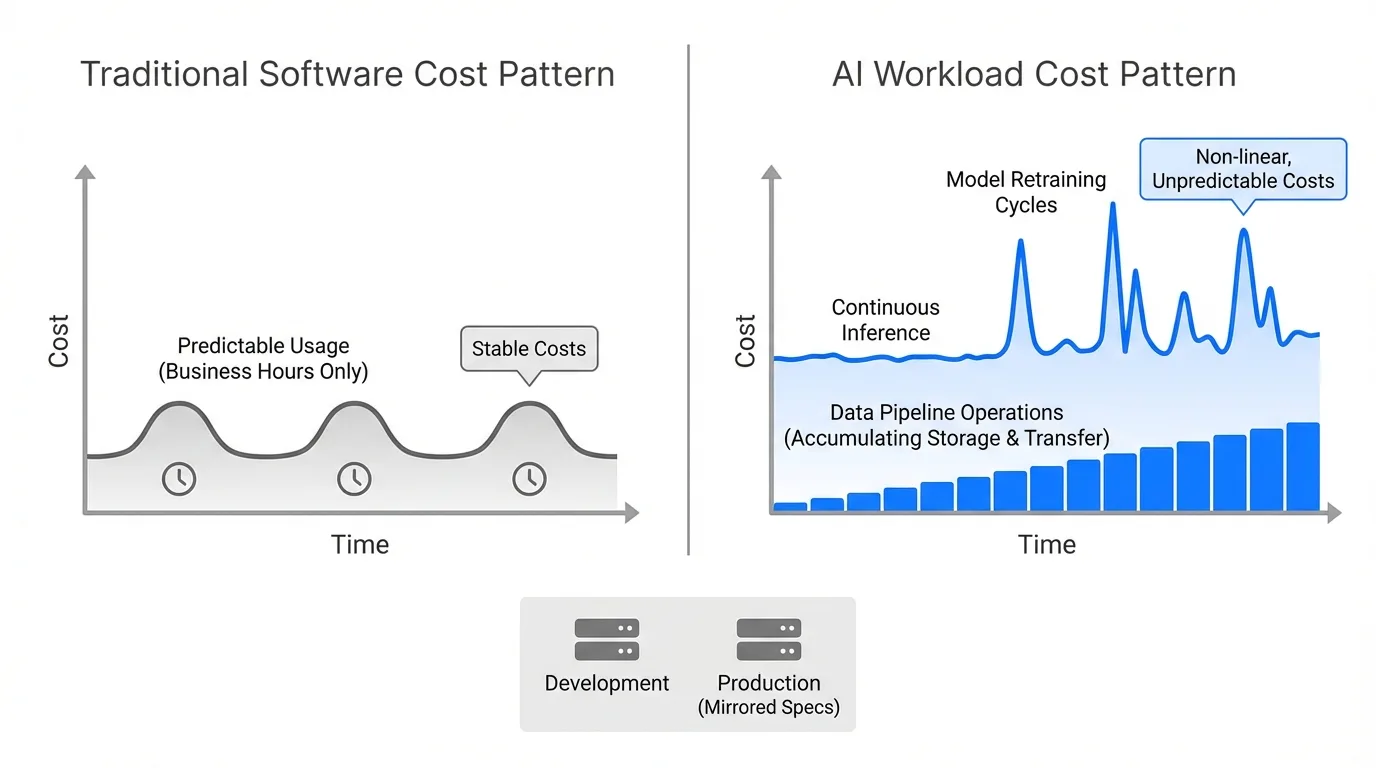
Most planning efforts focus too heavily on visible costs like GPU hours used for training or API calls for inference, but in production, hidden costs like storage sprawl, cross-region data transfers, idle compute, and continuous retraining often make up 60% to 80% of total spend.
Cloud infrastructure spending wastes approximately $44.5 billion annually (21% of total spend) on underutilized resources, and for AI workloads this waste is often higher because GPU instances run at $1.50 to $24 per hour while organizations leave powerful training infrastructure running around the clock.
The cost patterns differ fundamentally from traditional software:
Machine learning introduces non-linear cost behavior where a model that costs $50 per day to serve 1,000 predictions may not simply cost $5,000 to serve 100,000 but could cost far more due to bottlenecks in compute, memory, and I/O that trigger higher-tier resource provisioning.
Without orchestration that manages resource allocation dynamically, costs spiral while teams scramble to understand why their cloud bill exploded. Our guide on hidden AI costs and FinOps strategies details practical approaches for controlling these infrastructure expenses.
The most dangerous misconception about AI orchestration is that it's purely technical. It's not.
Leaders underestimated middle-layer drag, with their strategy engaging two extremes very well—senior leadership who loved the narrative and metrics, and individual engineers who loved the idea of AI assistance—but the weak link was the middle layer: frontline managers, escalation leaders, and process owners.
Orchestration succeeds or fails based on whether teams actually adopt it. That requires:
Leaders focused on model capability and scale whilst ignoring power dynamics: who controls the systems, who bears the risk, and who absorbs harm when things go wrong, resulting in illegitimate deployment.
Most leadership teams don't fail at AI because of bad models—they fail because the model works once and then quietly stops working when no one is watching, with accuracy dropping and results becoming unreliable.
Models degrade. Data drifts. Agents encounter edge cases. Without orchestration that includes comprehensive monitoring, these issues remain invisible until they cause customer-facing failures.
Agents benefit from production-grade telemetry, controls, and accountability, meaning logging tool calls, inputs, outputs, and decision paths, including using human-in-the-loop checkpoints for higher-impact actions, as well as applying budgets, rate limits, and safety pre-conditions at runtime.
Production orchestration must include:
Developers and users frequently cite the unreliability of AI agents as a barrier to production, as large language models make agents flexible and adaptable but this also leads to inconsistent outputs.
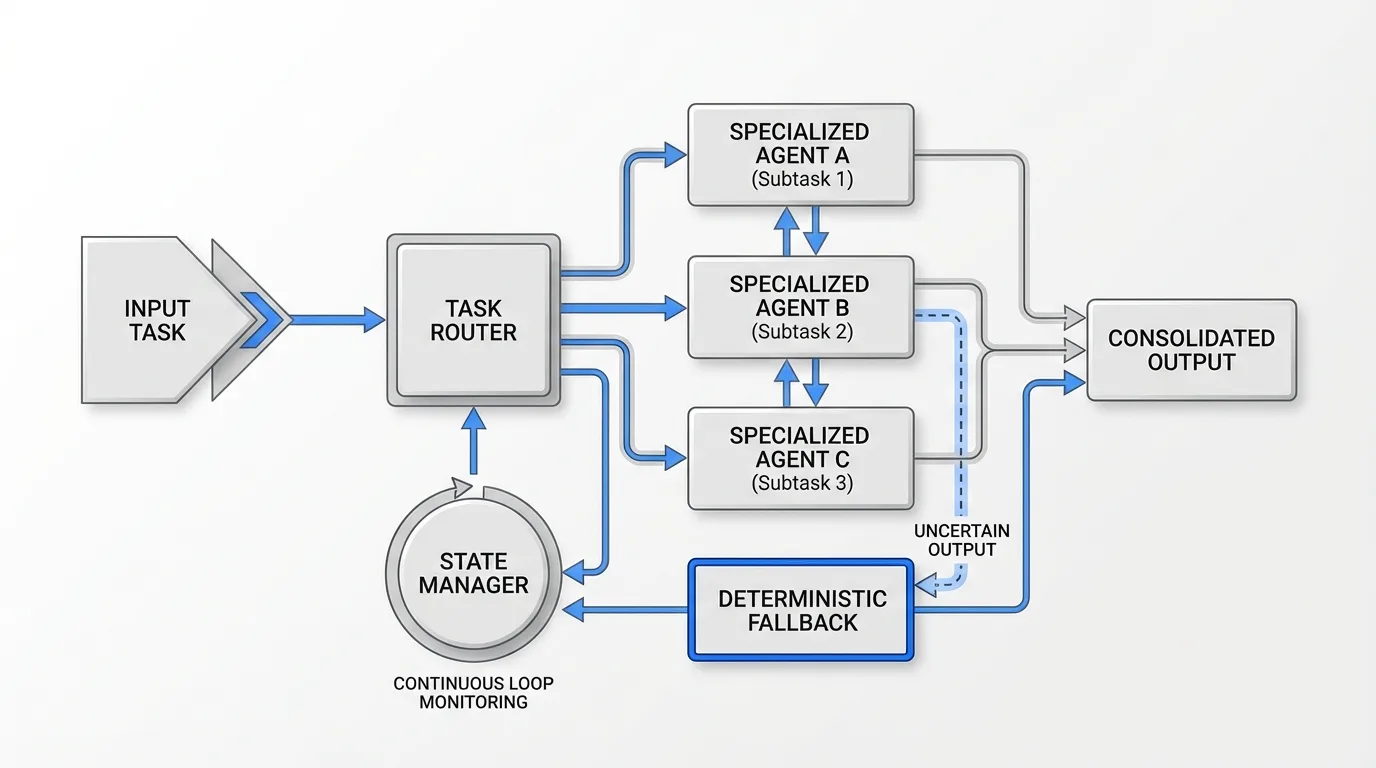
Single-agent systems are challenging. Multi-agent systems multiply that complexity exponentially. Agents must coordinate roles, manage shared state, and avoid conflicting with each other. These orchestration challenges mean teams often end up fixing one issue only for others to appear, with developers saying it sometimes feels like whack-a-mole where fixing one issue with prompt engineering creates three more.
By combining AI agents with deterministic automation scripts or rules, an orchestration layer ensures there's always a fallback path, for example if an AI agent's output doesn't meet a certain accuracy threshold, a predefined rule might handle that case, leveraging the creativity of AI but within guardrails.
Successful multi-agent orchestration requires:
For enterprises looking to implement these patterns effectively, our multi-agent orchestration guide for ops teams provides detailed frameworks for managing coordination complexity.
42% of enterprises need access to eight or more data sources to deploy AI agents successfully, and 86% require upgrades to their existing tech stack, with security emerging as the top challenge for 62% of practitioners.
Many organizations treat security as a deployment gate rather than an orchestration requirement. They build systems, then attempt to retrofit compliance controls. By then, agents access data across multiple systems, audit trails are incomplete, and governance frameworks must be reverse-engineered.
This huge governance gap introduces huge risk, as without proper governance, erratic AI agent actions could go undetected with potential implications for finance and operations, customer and partner relations, and public reputation.
For regulated enterprises in healthcare, finance, and government, security-first orchestration is non-negotiable:
The cost of orchestration mistakes is measurable. So is the value of avoiding them.
Organizations with mature MLOps capabilities typically see 30-50% reductions in model deployment times and improved model reliability that directly impacts revenue and customer satisfaction, with a McKinsey case study describing a large bank in Brazil that reduced the time to impact of ML use cases from 20 weeks down to 14 weeks by adopting MLOps and orchestration best practices.
MLOps tools automate deployment workflows, cutting launch times from 6 to 12 months down to 2 to 4 weeks, while also reducing infrastructure costs by up to 60% through intelligent scaling and minimizing manual rework by automating retraining, versioning, and monitoring.
Organizations with mature MLOps practices see 60-80% faster deployment cycles, which translates directly to faster time-to-market and revenue generation.
The difference between success and failure isn't the sophistication of your models. It's whether your orchestration infrastructure can reliably move them from development to production, monitor their performance, manage their costs, and ensure they deliver measurable business value.
Avoiding these seven mistakes demands orchestration infrastructure purpose-built for production AI:
Unified Agent Management: A single control plane providing visibility into all agents, their capabilities, access permissions, and performance metrics. Teams discover existing agents before building duplicates, coordinate multi-agent workflows, and enforce consistent governance policies.
Automated Resource Optimization: Intelligent workload scheduling that matches compute resources to actual needs, scales infrastructure dynamically based on demand, and eliminates idle resource waste that inflates cloud bills.
Built-in Governance and Compliance: Security controls integrated from day one, not retrofitted after deployment. This includes audit trails for regulatory compliance, role-based access control for data sovereignty, and policy enforcement preventing unauthorized actions.
Production Monitoring and Observability: Real-time visibility into model performance, agent behavior, and system health. Automated drift detection, performance degradation alerts, and rollback capabilities when deployments introduce issues.
Integrated Tool Ecosystem: Pre-integrated connections across the ML/AI stack, from data preparation through model training, deployment, and monitoring. Teams avoid the integration tax that delays projects by weeks or months. For companies looking to build an autonomous workforce with AI agents, this integrated approach becomes essential for coordinating complex agent interactions across enterprise systems.
Shakudo was built specifically to solve the orchestration challenges that derail enterprise AI initiatives.
Instead of fragmented tools creating the agent sprawl that plagues failed deployments, Shakudo provides a unified AI operating system with pre-integrated orchestration across 200+ ML/AI frameworks. Organizations deploy in days rather than the 20+ weeks that manual orchestration typically requires.
For regulated enterprises facing the security challenges cited by 62% of practitioners, Shakudo's data-sovereign architecture ensures all orchestration happens on-premises or in private cloud. Built-in governance provides audit trails, role-based access control, and compliance validation without slowing deployment velocity.
Shakudo's automated resource management prevents the 40% compute cost overruns and 30-50% deployment delays that plague manual orchestration. Intelligent workload scheduling eliminates idle GPU waste. Resource optimization ensures teams pay only for what they actually use. Enterprise-grade monitoring provides visibility into performance, costs, and agent behavior across the entire AI lifecycle.
The result transforms orchestration from a blocker into a competitive advantage. Teams prove value with concentrated vertical wins, then scale horizontally using infrastructure that handles complexity automatically. Security and compliance integrate from day one. Costs remain predictable and optimized. Multi-agent systems coordinate reliably rather than creating chaos.
The 42% of enterprises that abandoned AI initiatives in 2025 didn't fail because AI doesn't work. They failed because orchestration mistakes made it impossible to capture AI's value at production scale.
These seven mistakes are predictable, documented, and avoidable. Organizations that address orchestration systematically—with unified agent management, automated resource optimization, integrated governance, and production-grade observability—turn AI from expensive experiments into reliable business capabilities.
The question isn't whether your organization needs better AI orchestration. It's whether you'll address it proactively or join the 42% learning these lessons through expensive failures.
Ready to avoid these orchestration mistakes? Shakudo's AI operating system eliminates the complexity that derails enterprise AI. Schedule a demo to see how unified orchestration turns AI pilots into production success.




















