

Ever wondered how smart assistants such as Siri, Google Assistant, and Alexa translate your voice commands into actions? How do search engines provide relevant search results? How do self-driving cars detect accidents? All these systems can work autonomously because of deep learning, which is set to be a "defining future technology". With the advancements around the globe, be it digital, environmental, or even social, technology is the answer because it applies deep learning to new domains and products and helps develop the necessary tools. If such is the importance of deep learning in our lives, we must understand what it is.
Deep learning is a subfield of machine learning that teaches computers to display human-like capabilities such as planning, reasoning, and creativity. It enables the systems to adapt and improvise in a new environment so that they can generalize their knowledge and apply it to unfamiliar scenarios. As far as the technical systems are concerned, deep learning enables them to:
Following are the top deep learning algorithms that can help you solve complex real-world problems.
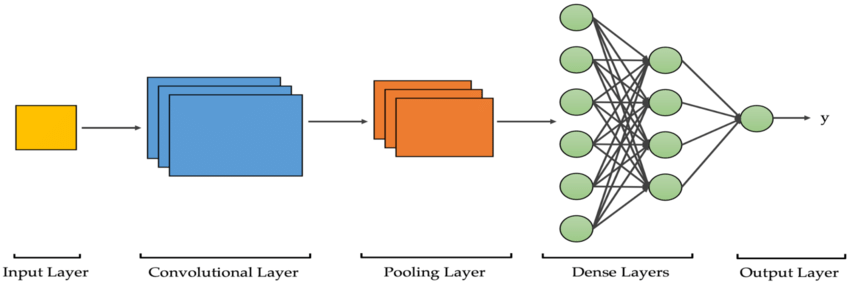
A Convolutional Neural Network (ConvNet or CNN) is a well-known artificial neural network that learns directly from data. It takes in an input image, assigns weights and biases to different image objects, and differentiates one from the other. Unlike other classification algorithms, ConvNet doesn’t require high pre-processing.
Convolutional Neural Network imitates the architecture of neurons in the human brain. It is particularly useful for Object detection and Image recognition. Like other artificial neural networks, CNN also consists of an input layer, hidden layers, and an output layer. The three common layers (building blocks) of CNN are:
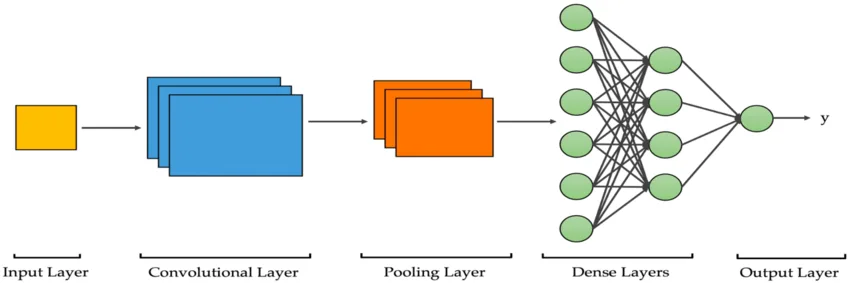
Using Convolutional Neural Networks for deep learning is popular due to the following three factors:
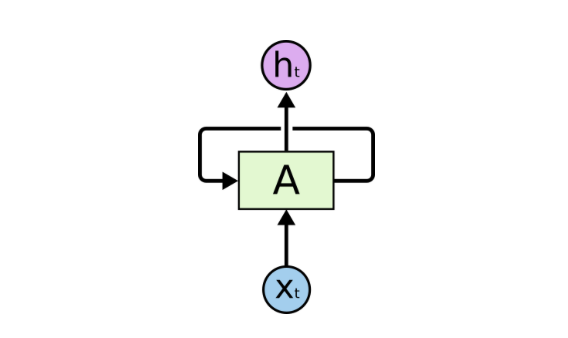
RNNs are deep learning neural networks that remember the input sequence, store it in cell states/memory states, and predict the future words. They are used for image captioning, time series prediction, machine translation, and natural language processing.
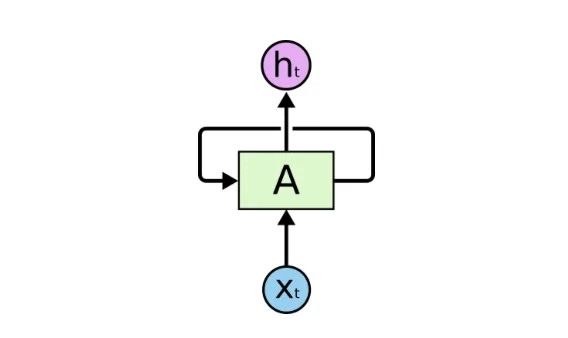
Suppose, while watching a drama, you know what happened in the previous episode. RNNs work in a similar fashion and remember the previous information to process the current input. But their shortcoming is: they can not remember long term dependencies due to vanishing gradient. Here comes the use of LSTMs.
Long Short-Term Memory Networks are advanced recurrent neural networks that can learn long term dependencies and can handle the vanishing gradient problem faced by RNN.
The LSTM network consists of different memory blocks called cells that have different parts as shown below.
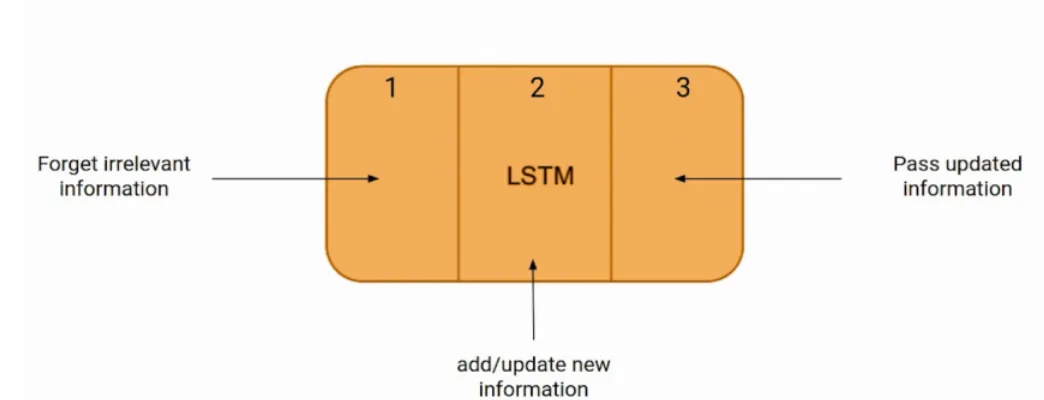
These three parts of the cell are known as gates.
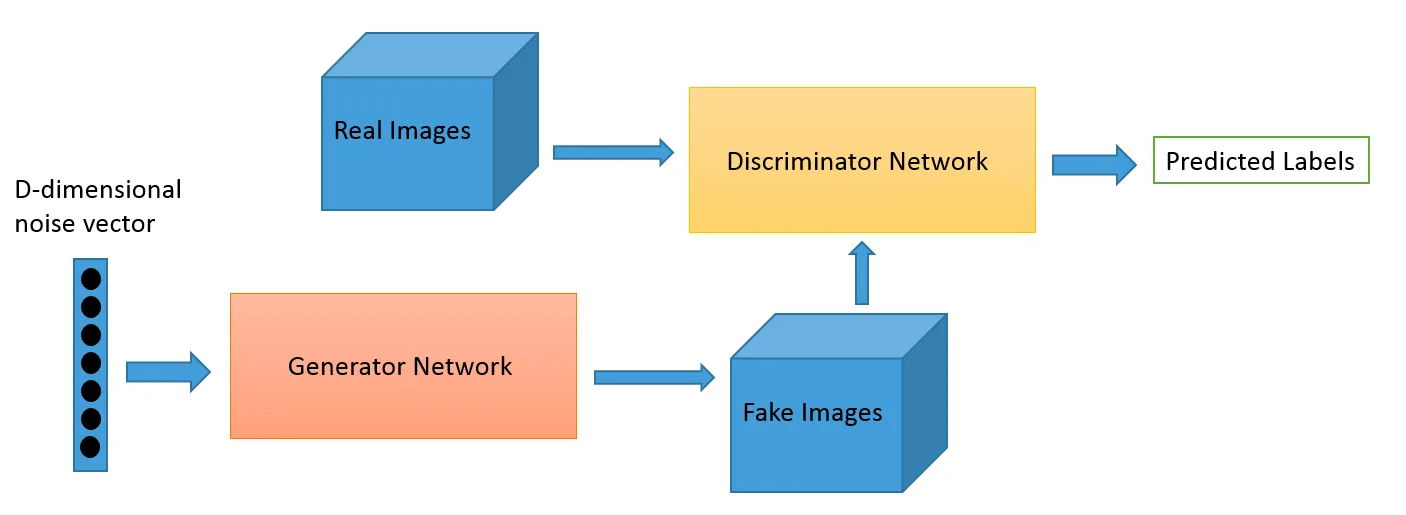
Generative Adversarial Network (GAN) is an unsupervised learning algorithm that consists of two neural networks. Both of these networks compete with each other to make accurate predictions.
Consider an example to understand the concept.
What would you do to get good at snooker? You would compete with a person who plays better than you. You would interpret where you were wrong, where he/she was right, and think on what strategy you could use to beat him/her in the next game.
You would continue to play the game until you defeat the opponent. In short, to become a powerful hero (generator), you need a more powerful opponent (discriminator). In deep learning, we use this concept to build better models.
GANs contain the following two neural networks:
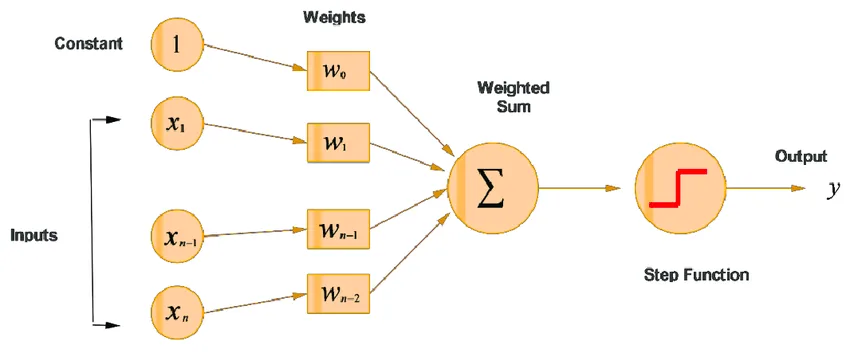
Multilayer Perceptron is a fully-connected multi-layer neural network that has three layers including one hidden layer. If there are more than one hidden layer, it is called a deep Artificial Neural Network.
MLPs are typical examples of feedforward artificial neural networks. Their hyperparameters need tuning and we can use different cross validation techniques to find ideal values for them.
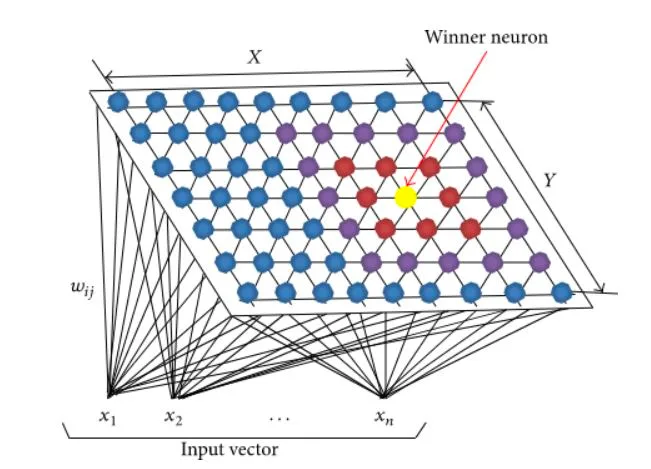
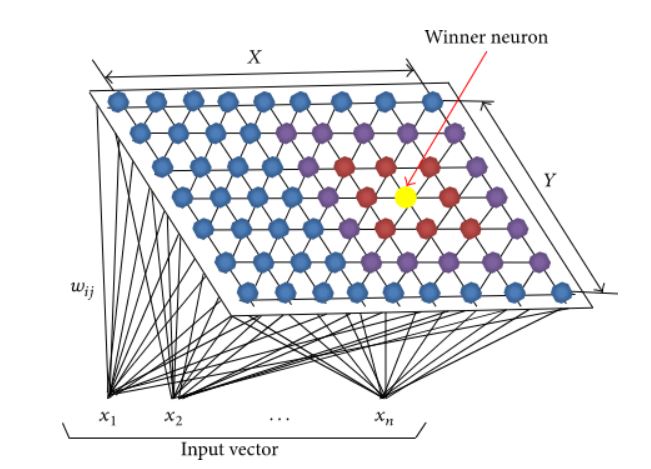
Self-Organizing Map (SOM) is a data visualization technique that reduces the dimensions of data to a map. It also groups similar data together and showcases clustering.
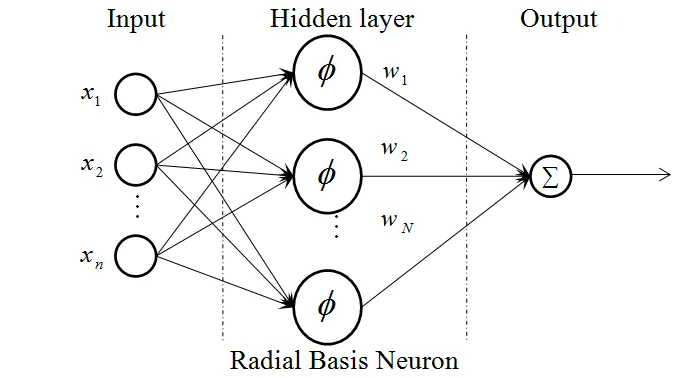
Radial Basis Function Networks (RBFNs) consist of an input layer, hidden layer, and an output layer. They use trial and error method to determine the structure of the neural network.
Deep learning algorithms have an increasing number of applications in many industries. For instance, iPhone's Facial Recognition uses deep learning to identify data points from our face and unlock the phone. Virtual assistants such as Amazon Echo, Alexa, Siri, and Google Assistant use deep learning algorithms to develop a customized user experience for us. Nowadays, hotels use robots to clean, greet, and deliver room service. Likewise, there are many other applications of deep learning algorithms. So, this is not the end of deep learning; there is way more to come from it. Who knows what AI and deep learning can do for us in the near future? Maybe it will be a society full of robots.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}