

Enterprise AI is at a genuine inflection point, and the numbers are brutal. Over 80% of AI implementations fail within the first six months, and agentic AI projects face even steeper odds, with MIT research indicating that 95% of enterprise AI pilots fail to deliver expected returns. Meanwhile, over 40% of agentic AI projects will be canceled by the end of 2027, due to escalating costs, unclear business value, or inadequate risk controls, according to Gartner.
These aren't abstract statistics. They represent billions of dollars written off, months of engineering time abandoned, and entire AI programs cancelled before they ever touched production. The question every CIO and CTO should be asking is not "why is AI failing?" but "what specifically is killing it?"
The answer is almost never the model.
Deloitte's 2025 Emerging Technology Trends study found that while 30% of organizations are exploring agentic options and 38% are piloting solutions, only 14% have solutions ready for deployment and a mere 11% are actively using these systems in production. That is a staggering collapse between experimentation and execution.
Forrester's 2025 AI Implementation Survey identified what analysts called "perpetual piloting" — the normalization of running dozens of proofs-of-concept while failing to ship a single production system at scale. The most visible failure of 2025 wasn't a collapsed initiative; it was this organizational pattern becoming endemic.
Recent data from S&P Global shows 42% of companies scrapped most of their AI initiatives in 2025, up sharply from just 17% the year before, and the average organization abandoned 46% of AI proof-of-concepts before they reached production. This isn't a technology problem. It is a systemic infrastructure problem, and it has specific, diagnosable root causes.
When you trace enterprise AI agent failures back to their origin point, the same six infrastructure decisions appear repeatedly. Understanding them is the first step toward deploying AI agents in production that actually hold.
1. Broken RAG pipelines treated as solved problems
Retrieval-Augmented Generation is the connective tissue of most enterprise AI agents, and it is failing at an alarming rate. The pattern is predictable: teams stand up a vector database, point it at enterprise documents, and declare the knowledge layer "done." Production traffic then surfaces the reality — stale embeddings, inconsistent chunking strategies, retrieval latency that breaks real-time SLAs, and hallucinations that undermine user trust within days.
Large enterprises run the most pilots but take nine months on average to scale, compared to just 90 days for mid-market firms. Much of that delay traces directly to data readiness: teams discover during production hardening that their retrieval infrastructure was built for demos, not workloads.
2. Polling architectures masquerading as real-time systems
Agents built on polling-based connectors — systems that check for updates on a schedule rather than reacting to events — introduce latency that makes autonomous workflows brittle. Companies are pouring $30–40 billion into generative AI, yet an MIT NANDA study finds that 95% of enterprise pilots deliver zero measurable return. A significant share of that failure traces to architecture decisions made at the start: teams choose polling because it is easier to build, and pay for it in production reliability.
Event-driven architectures, where agents react to state changes in real time across connected systems, are significantly more resilient under production load. They are also significantly harder to wire up without pre-built integrations.
3. The integration wall
UiPath's report notes that lack of interoperability is the second most cited reason for pilot failures, right after data quality issues. In the same study, 63% of executives cited "platform sprawl" as a growing concern, suggesting that many enterprises are juggling too many tools with limited interconnectivity.
This is the integration wall: every agent needs a custom connector for every tool, every connector is a point of failure, and the cumulative weight of custom integrations eventually collapses the project. The biggest bottleneck of 2025 was the "integration wall." Every agent needed a custom connector for every tool. That changed with the widespread adoption of the Model Context Protocol (MCP). Enterprises that still build point-to-point integrations are accruing architectural debt that will make their agentic systems obsolete before they reach scale.
4. Absent observability
You cannot fix what you cannot see. The majority of enterprise AI agent deployments go into production without structured evaluation harnesses, distributed tracing, or systematic failure classification. When something breaks — and something always breaks — teams have no systematic way to determine whether the failure originated in the prompt, the model, a tool integration, or the orchestration layer.
Without observability, every production incident becomes a multi-week archaeology project. Trust erodes. Rollback discussions start. And the agent that was supposed to automate a critical workflow becomes the reason leadership questions whether agents belong in production at all.
5. Governance vacuums at autonomous-action scale
The second failure pattern is giving AI agents the power to act without giving them rules to act by. Governance in agentic AI is not about restricting the AI. It's about encoding business logic — approval hierarchies, compliance thresholds, escalation triggers, decision trees — into deterministic rules that the agent must follow.
When governance is absent, agents make probabilistic guesses at enterprise scale. They approve things they shouldn't. They skip steps that matter. They optimize for speed when the business needed caution. In regulated industries — healthcare, financial services, energy — this is not just an operational failure. It is a compliance failure with legal consequences.
6. Data sovereignty exposure
This is the failure mode that stops deployments entirely in regulated sectors, rather than killing them after launch. Enterprise data transfers to AI and ML applications reached 18,033 terabytes in 2025, representing a 93% year-over-year increase. Much of that data is moving to external platforms without adequate controls.
The scale of this risk is quantified by 410 million Data Loss Prevention policy violations tied to ChatGPT alone, including attempts to share Social Security numbers, source code, and medical records. For healthcare organizations handling PHI or financial institutions managing client data, these numbers are not theoretical. They are the reason AI agent projects get cancelled at the security review stage.
The security picture for production AI agents is significantly worse than most organizations realize when they begin deploying them. Zscaler's red team testing found critical flaws in 100% of enterprise AI systems analyzed, with a median time to first critical failure of just 16 minutes.
Based on an analysis of nearly one trillion AI/ML transactions across the Zscaler Zero Trust Exchange platform between January and December of 2025, the research shows that enterprises are reaching a tipping point where AI has transitioned from a productivity tool to a primary vector for autonomous, machine-speed conflict.
For the engineering and data leaders responsible for deploying AI agents in production, this means security cannot be a post-hoc concern addressed at the compliance review. It must be designed into the infrastructure from day one — which is exactly what most generic agent platforms do not support.
The organizations that successfully deploy AI agents at scale share a set of common infrastructure decisions. They are not doing anything exotic. They are being disciplined about the fundamentals.
Integrating agents into legacy systems can be technically complex, often disrupting workflows and requiring costly modifications. In many cases, rethinking workflows with agentic AI from the ground up is the ideal path to successful implementation. The teams that succeed treat this as an architecture project from the start, not a model selection exercise.
Gartner's 2025 platform forecast indicates one of the steepest adoption curves in enterprise history. The leap from under 5% of applications embedding agent capabilities in 2025 to 40% in 2026 reflects a major architectural shift. Enterprise software is evolving from static systems to dynamic systems that reason, adapt, and automate.
For enterprises in healthcare, financial services, nuclear energy, and government, this shift is happening whether or not the underlying infrastructure is ready for it. The organizations that will capture the productivity gains — and avoid the compliance failures — are those that resolve the infrastructure layer before scaling the agent layer.
Trust remains a limiting factor, with only 27% of organizations expressing trust in fully autonomous AI agents, down from 43% one year earlier. Fewer than 20% of organizations report having mature data readiness, and over 80% lack mature AI infrastructure, constraining large-scale deployment. These numbers reveal the actual gap: not a shortage of ambition, but a shortage of production-grade infrastructure.
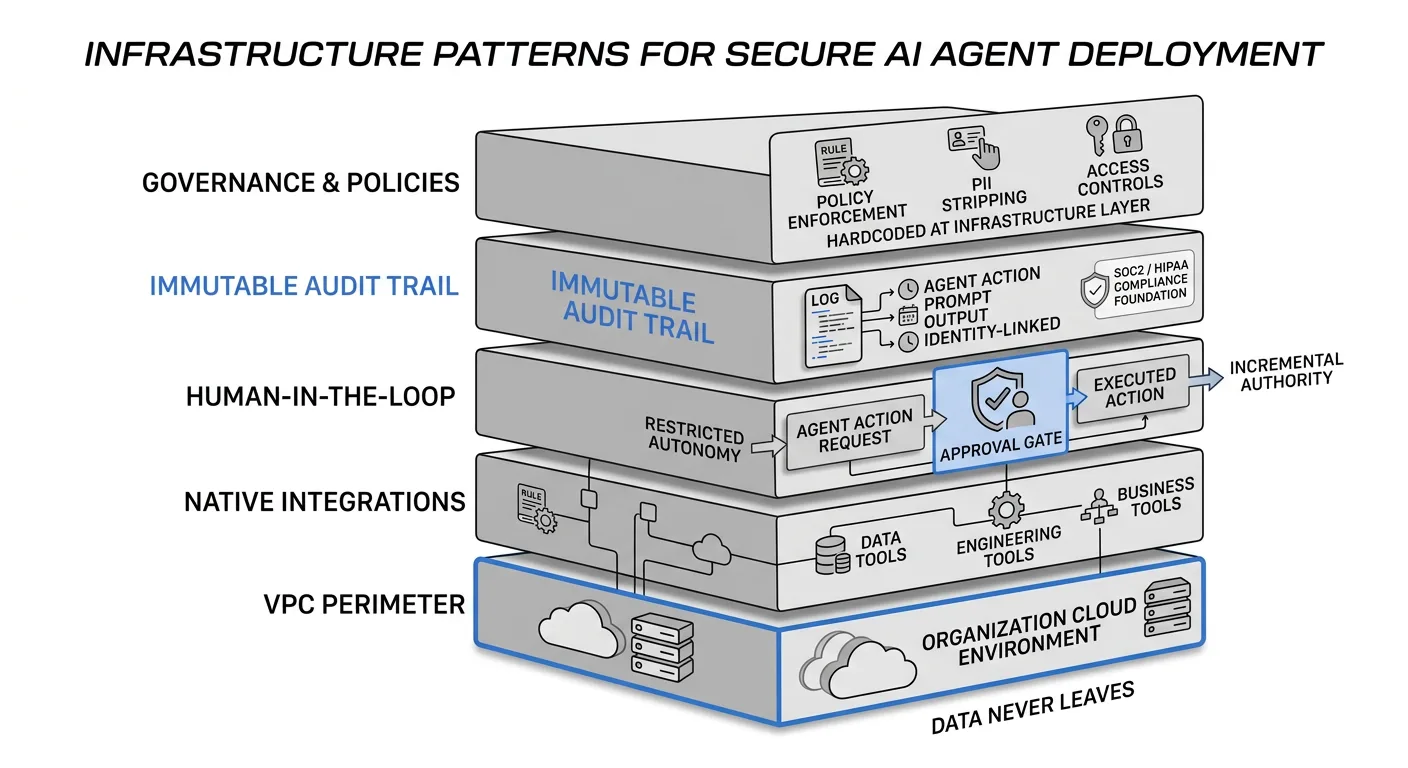
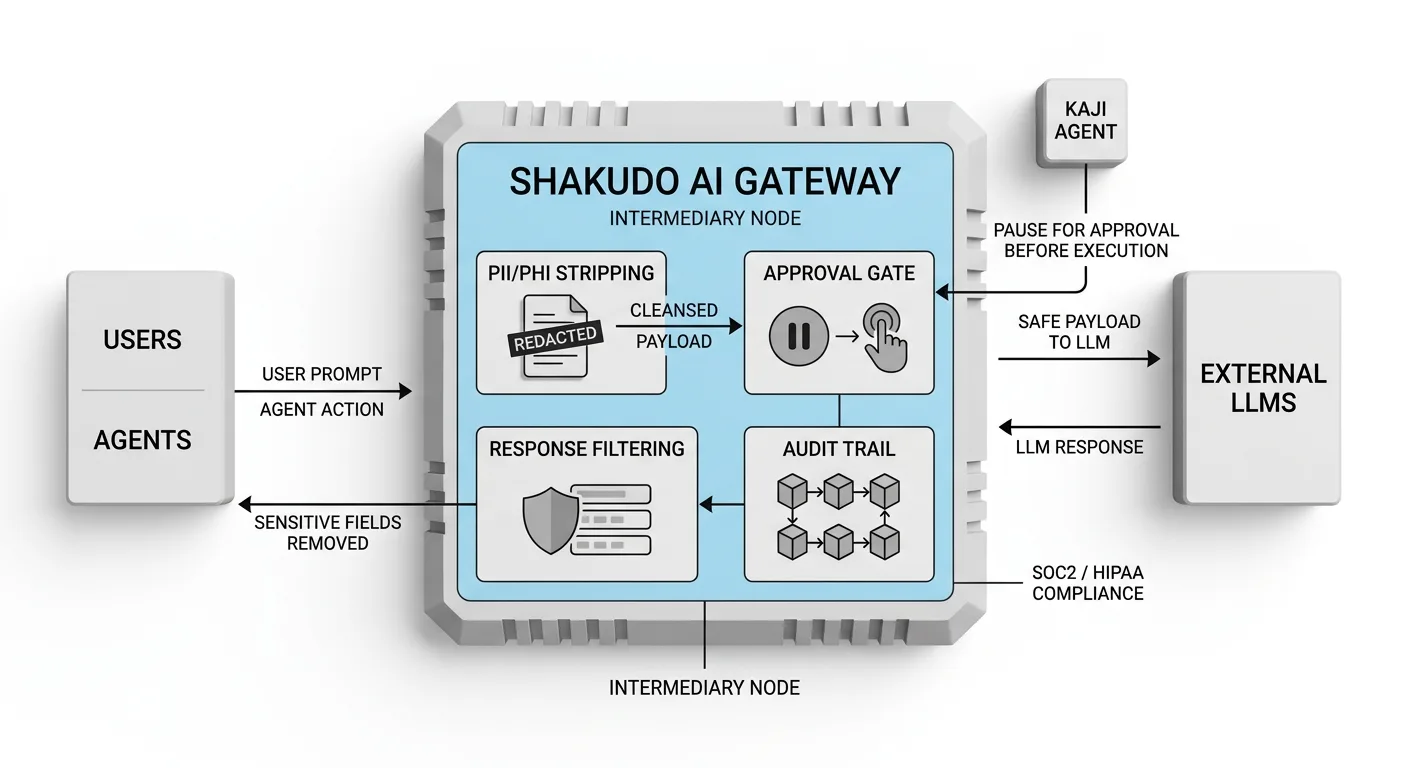
Shakudo was designed specifically for this infrastructure gap. The platform deploys entirely within an organization's own cloud VPC — AWS, Azure, GCP — or on-premise infrastructure, so all data, prompts, and institutional knowledge remain within the customer's security perimeter. External LLMs can be connected with zero-retention, zero-training guarantees, eliminating the data sovereignty exposure that stops regulated deployments cold.
Kaji, Shakudo's enterprise AI agent, operates within this already-secured environment and is built for the production conditions that generic agent platforms cannot handle. With over 200 prebuilt connections to data, engineering, and business tools, Kaji eliminates the integration wall before it becomes a problem. It works where teams already operate — Slack, Teams, Mattermost — removing the adoption friction that buries otherwise functional agent deployments.
Critically, Kaji is human-in-the-loop by design. It pauses and requests approval before executing high-stakes or irreversible actions, which is the governance pattern that production deployments in regulated industries require. The Shakudo AI Gateway sits between users, agents, and models — stripping PII and PHI from payloads before they reach external LLMs, filtering sensitive fields from agent responses, and maintaining the immutable, identity-linked audit trail that SOC2 and HIPAA compliance demands.
The outcomes validate the architecture. Shakudo cut one enterprise's AI tool deployment from a six-month procurement cycle to same-day delivery. Kaji autonomously improved a major logistics partner's ML model accuracy by 49% — without human intervention — entirely within the customer's own controlled environment. These are not pilot results. They are production outcomes.
The 80% failure rate is a solvable problem. The technology is not the bottleneck — the future of agentic AI is not about more powerful models. The models are already powerful enough. What is missing in most failed deployments is the operating system beneath the agent: the governed, observable, sovereign infrastructure layer that makes autonomous action safe enough to run at enterprise scale.
Engineering and data leaders evaluating how to deploy AI agents in production have a clear decision to make. Build that infrastructure layer from scratch — six months of custom integration work, security architecture, governance design, and observability tooling — or deploy on a platform where it already exists.
If you are ready to stop piloting and start deploying, Kaji at shakudo.io/kaji is built for exactly this moment.




















