

The pressure is undeniable. Forty percent of enterprise applications will be integrated with task-specific AI agents by 2026, up from less than 5% today. Yet for most regulated enterprises, the path from that ambition to production-running agents on their own infrastructure is anything but clear. Two forces are colliding: compliance mandates that make cloud-based AI legally risky, and the brutal engineering reality of assembling a production-grade AI stack on Kubernetes from scratch.
This is not a theoretical problem. It is the central deployment challenge of 2026.
The agentic AI conversation in boardrooms is far ahead of what most engineering teams can actually deliver. Business leaders are prioritizing security, compliance, and auditability (75%) as the most critical requirements for agent deployment, and leading teams are embedding privacy by design and segmenting sensitive data to trace and remediate issues early, with these safeguards becoming foundational to scaling agents responsibly in 2026. The mandate is clear. The mechanism is not.
Meanwhile, McKinsey's State of AI report found only 23% of enterprises are actually scaling AI agents, with another 39% stuck in experimentation, and the gap between announcement and deployment has never been wider. The enterprises that move from pilot to production fastest will compound their advantage. Those that stay stuck in infrastructure assembly will not.
There are two dominant failure modes. The first is reaching for a cloud-hosted agent platform and discovering that it is incompatible with data governance requirements. The second is deciding to build on-prem AI agent infrastructure internally and watching the timeline balloon from weeks into months. Understanding both traps is the prerequisite for avoiding them.
For organizations in healthcare, financial services, and government, the issue with cloud-based agentic AI is not capability. It is sovereignty. Every query processed by an external LLM endpoint, every prompt containing internal business context, every agent action log that leaves the organizational perimeter represents a potential compliance violation.
The regulatory pressure is becoming structural, not optional. The EU AI Act entered into force on 1 August 2024, with governance rules and obligations for general-purpose AI models becoming applicable on 2 August 2025, and the rules for high-risk AI systems applying on 2 August 2026. Organizations that deploy cloud-connected AI agents handling sensitive data are increasingly exposed as these enforcement phases activate.
As enterprises move deeper into generative AI adoption, staying compliant is no longer a matter of good practice — it is a matter of operational survival, with frameworks like the EU AI Act, the NIST AI Risk Management Framework, and ISO/IEC 42001 defining how organizations design, deploy, and monitor AI systems in 2026. Cloud AI deployments that send sensitive payloads to external providers simply cannot satisfy these requirements without significant architectural compromise. Our nine AI governance frameworks reshaping enterprise compliance breaks down exactly how each framework maps to deployment architecture decisions.
The calculation changes entirely when all inference, all data, and all agent outputs remain inside the organizational perimeter. On-prem agentic AI infrastructure is not a technical concession; it is a strategic prerequisite for regulated industries that want to move fast without creating compliance exposure.
So the answer is on-prem. Fine. But what does it actually take to deploy an ai agent on kubernetes in a production-ready configuration? Most teams discover the answer the hard way.
A self-assembled on-prem agentic AI stack requires teams to independently source, configure, integrate, and harden each of the following layers:
90% of respondents expect their AI workloads on Kubernetes to grow in the next 12 months, with the average Kubernetes adopter now running clusters in more than five environments, driven by multicloud strategies, on-prem repatriation, and AI needs. The organizations navigating this well are consolidating onto platform engineering models rather than treating each component as a separate DIY project.
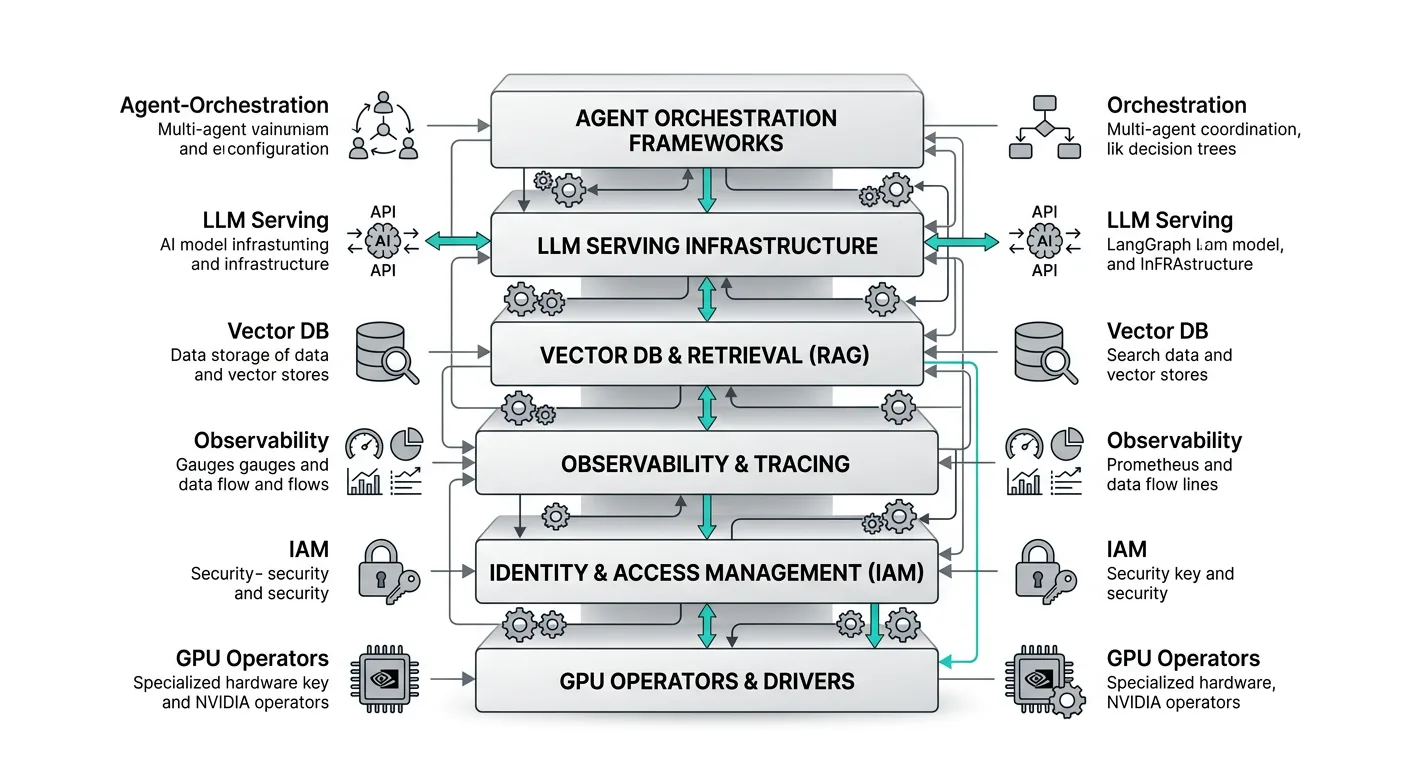
The raw cost of the DIY path is significant. Platform engineering salaries often approach $200,000 a year, and those engineers spend months assembling infrastructure rather than shipping value. According to the State of Production Kubernetes 2025 report, 88% of teams report year-over-year TCO increases for Kubernetes, and that pressure intensifies when GPU infrastructure enters the equation. A survey of 917 Kubernetes practitioners found that 54% struggle with GPU cost waste averaging $200,000 annually.
The outcome for most teams that attempt a full DIY build is predictable: senior engineers become infrastructure plumbers, pilot timelines stretch from weeks to quarters, and the business stakeholders who commissioned the AI initiative lose confidence before a single agent reaches production. The build vs. buy decision for AI agents deserves rigorous analysis before committing either path.
The components above describe the minimum viable stack for running an ai agent on prem. But production-grade on-prem agentic AI infrastructure demands more than connectivity between components. It requires operational maturity across several dimensions that are easy to underestimate during the design phase.
Multi-agent orchestration and reliability. Running a single agent in isolation is architecturally simple. Coordinating multiple agents across a shared environment requires explicit handling of race conditions, task delegation, failure recovery, and resource contention. A 2026 production system coordinates agents across CRM, inventory, support ticketing, and payment systems, with each agent handling specialized tasks while a supervisor orchestrates the whole workflow. The architecture complexity jumps by an order of magnitude, as does the operational risk if governance is not in place.
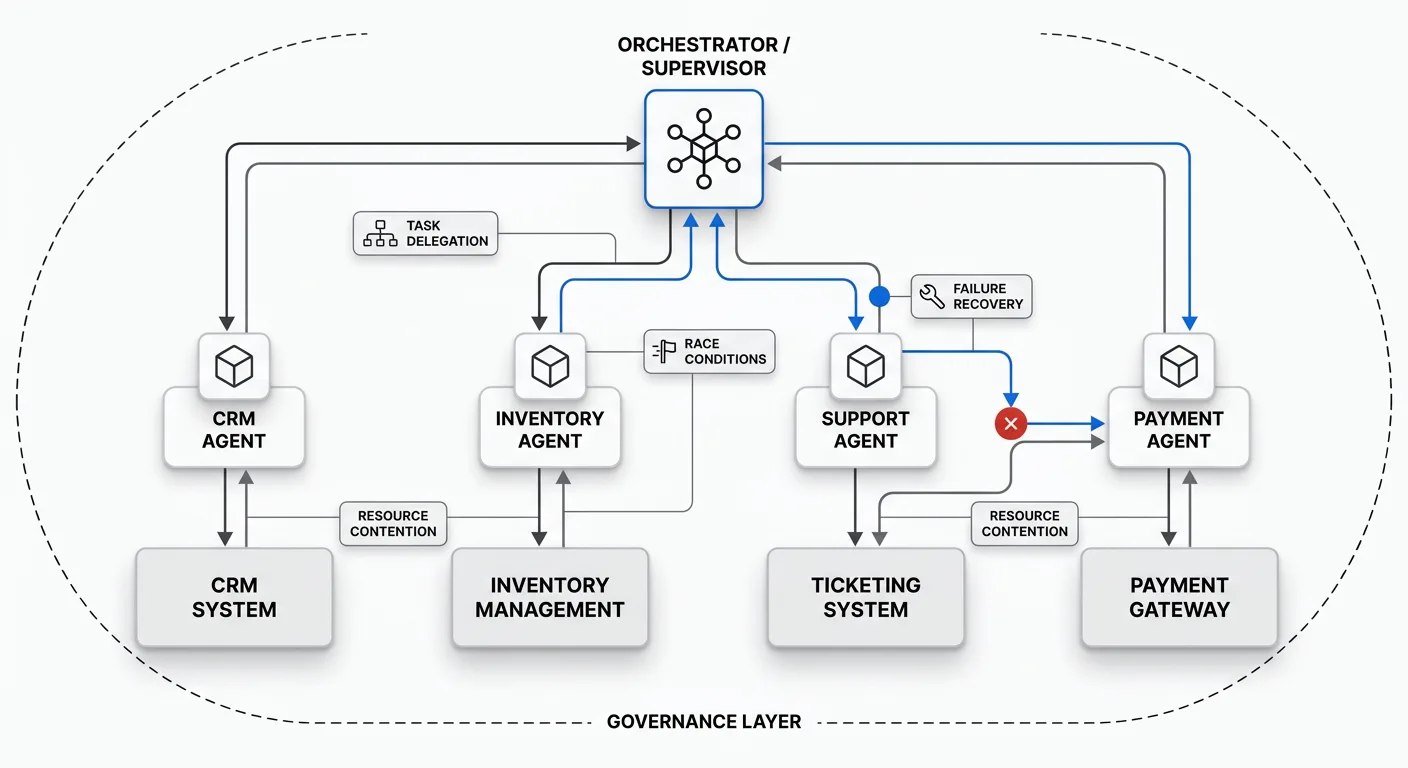
Compliance documentation and audit trails. Regulated organizations cannot simply deploy agents and trust that they behave correctly. Before launching a proof of concept, enterprises must prove that controls function in runtime, and in the 2026 compliance environment, screenshots and declarations are no longer sufficient — only operational evidence counts. Every agent action, every model call, and every data access must produce a verifiable audit record.
Human oversight by design. The most operationally robust agentic deployments are not fully autonomous by default. They are designed with checkpoints at which agents pause and request human approval before executing high-stakes or irreversible actions. Building this into a self-assembled stack is possible, but it requires deliberate architectural investment that many teams skip during initial builds.
The demand for on-prem agentic AI infrastructure is not hypothetical. Enterprises across sectors are already deploying agents in production, and the patterns are instructive.
A financial services company is building agentic workflows to automatically capture meeting actions from video conferences, draft communications to remind participants of their commitments, and track follow-through. For a financial institution, this workflow must process internal meeting content without that data leaving the organizational perimeter. Cloud-hosted agents are not viable here. The full scope of what is now possible is documented in our big book of AI agent financial services use cases.
In the public sector, AI agents are being used to cover workforce shortages, partnering with human workers to complete key processes. Government agencies operating under federal data handling mandates require complete network isolation and verifiable audit trails for every agent action — requirements that on-prem deployment satisfies by design.
In healthcare, agents that surface patient data insights, automate prior authorization research, or assist clinical documentation must never route PHI through external LLM endpoints. The HIPAA exposure alone makes cloud-connected agentic AI a non-starter for most health systems without complex data scrubbing architectures.
For teams actively evaluating how to deploy ai agent on kubernetes or selecting on-prem agentic ai infrastructure, several decisions have outsized consequences.
Hardware and cluster topology. GPU scheduling in Kubernetes requires node taints, tolerations, and resource quotas configured explicitly for AI workloads. Teams that treat GPU nodes like standard compute nodes discover contention, underutilization, and instability quickly. The infrastructure must be designed for AI-specific scheduling from the start.
Model selection for air-gapped deployments. Not all open-weight models perform equivalently in sovereign deployments. Model size, quantization strategy, and hardware compatibility must be evaluated against actual workload requirements before infrastructure is provisioned around a specific model family.
Network isolation and zero-trust policy. On-prem agent infrastructure must enforce strict network policies at the pod level. Agent components should not have unrestricted egress, even within the cluster. Secrets management and API key rotation should be automated, not manual.
Observability from day one. Distributed tracing for agent actions, token usage monitoring, latency histograms per model endpoint, and alert routing for agent failures are not optional features to add later. As AI moves from experimentation to deployment, governance is the difference between scaling successfully and stalling out, and enterprises where senior leadership actively shapes AI governance achieve significantly greater business value than those delegating the work to technical teams alone. Building observability into the initial deployment is the practice that separates teams that scale from teams that stall.
Compliance documentation architecture. Audit trail requirements vary by jurisdiction and industry, but the baseline expectation is an identity-linked, immutable record of every agent action, tool call, and model output. This record must be queryable for incident response and exportable for regulatory review.
For enterprises that have assessed the build-from-scratch path and recognized the cost, Kaji offers a fundamentally different approach to on-prem agentic AI infrastructure.
Shakudo, the underlying platform, deploys entirely within an organization's own VPC, on-premises data center, or private cloud — the customer's infrastructure, governed by the customer's policies. Kaji is the enterprise AI agent that operates within that already-sovereign environment. All data, prompts, model outputs, and institutional knowledge remain within the organizational perimeter. External LLMs can be used with zero-retention and zero-training guarantees when they are needed, but nothing leaves without explicit organizational control.
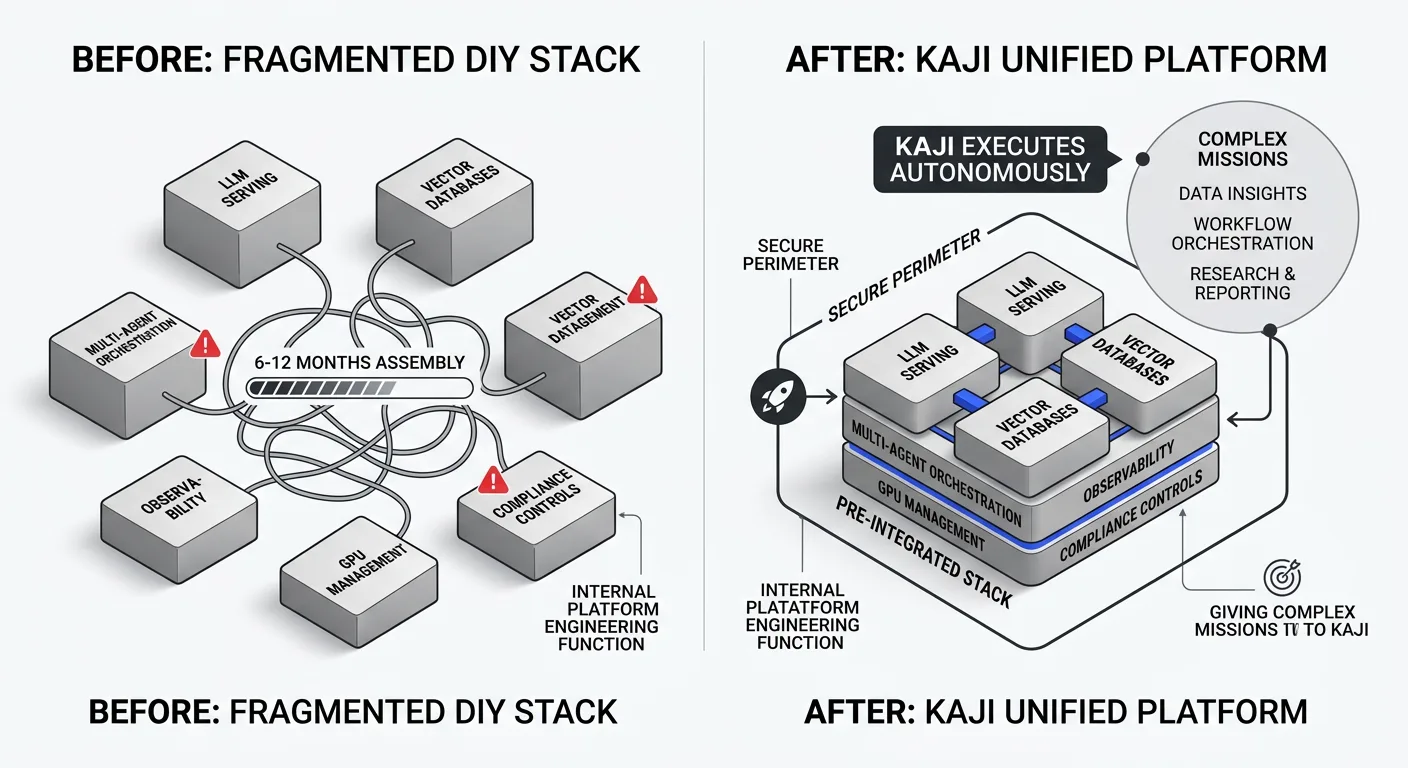
What Kaji delivers is the pre-integrated stack that most teams spend six to twelve months assembling: LLM serving, vector databases, multi-agent orchestration, observability, GPU management, and compliance controls arrive already wired together and security-hardened. Rather than building an internal platform engineering function to assemble these components, enterprises give Kaji complex missions — surfacing data insights, orchestrating multi-step workflows, automating research and reporting pipelines — and Kaji executes them autonomously within the secure perimeter.
Kaji works where teams already collaborate. Slack, Teams, and Mattermost integrations mean no new interface to learn and no change management overhead. 200+ prebuilt connections to data, engineering, and business tools ensure that the agent can reach the systems it needs to complete its missions. Human-in-the-loop checkpoints are built in by design, so high-stakes or irreversible actions require approval before execution. The Shakudo AI Gateway enforces organization-wide governance policies, strips PII and PHI from payloads before they reach external models, and maintains a permanent, identity-linked audit trail suitable for SOC2 and HIPAA compliance review.
The result is a path from zero to running AI agents on your own hardware measured in days, not months — without the platform engineering headcount or the infrastructure fragility that characterizes self-assembled stacks.
The organizations that figure out on-prem agentic AI deployment will operate with a structural advantage that compounds over time. They will execute workflows faster, with better data, and with less compliance risk than competitors still routing sensitive information through external cloud platforms or stuck in DevOps limbo with unfinished self-builds.
The enterprises that win won't be the ones with the most AI projects — they'll be the ones with AI agents that actually run. The technical path is clear. The choice is whether to build it from scratch over months or deploy a pre-integrated sovereign stack in days.
For engineering leaders, data teams, and IT decision-makers evaluating this choice, the starting point is a concrete conversation about your current infrastructure, your compliance requirements, and what it would take to get your first agents into production. Kaji is built for exactly that conversation.




















