

The conversation has officially shifted from "can we build AI agents?" to "can we trust them in production?" For engineering and platform teams, that question has a very specific answer: it depends entirely on the infrastructure underneath the agent. And in 2026, that infrastructure is Kubernetes.
The CNCF Annual Cloud Native Survey, released January 20, 2026, confirms that Kubernetes has solidified its role as the de facto operating system for AI, with 82% of container users now running it in production environments. That number was 66% just two years ago. The acceleration is structural, not cyclical — and it has direct implications for every team trying to deploy ai agents on kubernetes at enterprise scale.
Kubernetes didn't become the foundation for AI workloads by accident. The platform has become the common denominator for cloud native scale, stability, and innovation — evolving beyond orchestration to become the backbone of enterprise infrastructure. When your AI agents need to call internal APIs, query Prometheus metrics, pull pod logs, interact with CI/CD systems, and route decisions through an LLM, you need an orchestration layer that already speaks the language of all those systems natively.
Running agents on Kubernetes makes sense once you go beyond toy projects. Organizations are already running workloads in clusters, and Kubernetes provides scaling, reliability, and integration with the very systems — CI/CD, observability, GitOps — that agents need to interact with.
The numbers back this up. According to the 2025 CNCF data, 66% of organizations using generative AI rely on Kubernetes for some or all of their AI inference workloads. And with 57% of companies already running AI agents in production and 81% planning to expand into more complex multi-step use cases in 2026, the demand for a disciplined, kubernetes ai agent framework is acute.
Most teams hitting production with AI agents have been doing it the hard way — stitching together Python frameworks, kubectl wrappers, custom GitOps scripts, and ad-hoc Prometheus connectors into something that works on a good day. Kagent is an open-source framework purpose-built to bring agentic AI into Kubernetes. Instead of gluing together your own kubectl wrappers, GitOps scripts, and Prometheus connectors, kagent gives you a runtime where those capabilities already exist.
Kagent was accepted to the CNCF on May 22, 2025 at the Sandbox maturity level, making it the first agentic AI framework to receive that designation. Introduced by Solo.io, kagent is an open-source framework designed to help users build and run AI agents to speed up Kubernetes workflows — offering tools, resources, and AI agents that help automate configuration, troubleshooting, observability, and network security, with an architecture built on the Model Context Protocol (MCP).
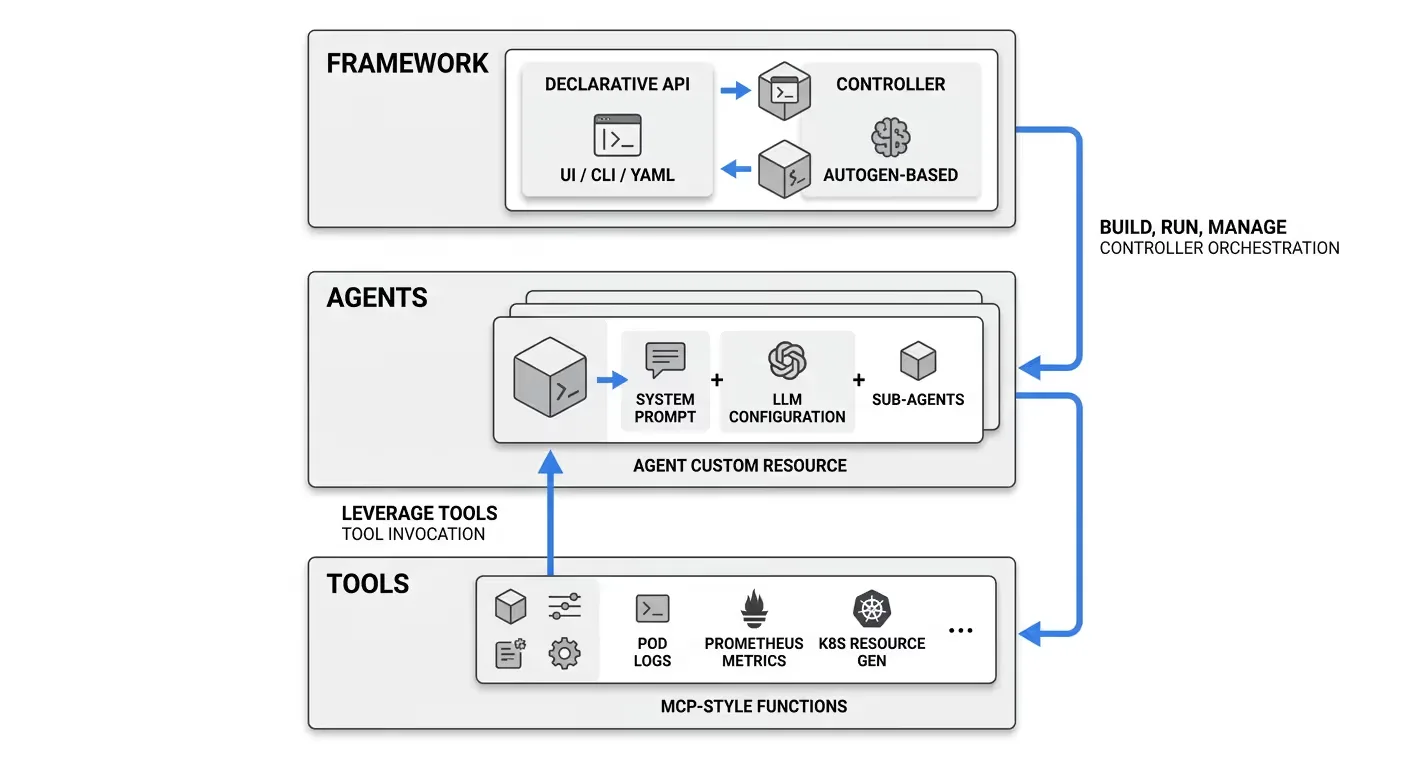
The framework is built around three core layers:
The declarative model is what separates kagent from DIY approaches. Rather than imperative Python scripts that are fragile and opaque, you define agents as YAML manifests and manage them like any other Kubernetes resource. Kagent is designed to be declarative — you define agents and tools in a YAML file. That means GitOps, version control, peer review, and rollback all apply to your agent fleet the same way they apply to your application deployments. If you're weighing whether to build this layer yourself or adopt an existing framework, our build vs. buy breakdown for enterprise AI agents covers the tradeoffs in detail.
Here is a concrete walkthrough of what deploying an ai agent kubernetes setup looks like with kagent.
Prerequisites: A running Kubernetes cluster, Helm, and an API key for a supported LLM provider. Kagent supports multiple LLM providers including OpenAI, Azure OpenAI, Anthropic, Google Vertex AI, Ollama, and any other custom providers accessible via AI gateways. Providers are represented by the ModelConfig resource.
Step 1: Install kagent via Helm
Install the CRDs first, then the kagent control plane:
Then install the kagent chart with your LLM provider credentials.
Step 2: Store your LLM API key as a Kubernetes Secret
Keeping credentials in Kubernetes Secrets (ideally backed by a secrets manager like Vault or AWS Secrets Manager) is the baseline for any production deployment. Hardcoding credentials in manifests or environment variables is a common mistake that creates serious security exposure at scale.
Step 3: Define your Agent as a custom resource
The kagent controller detects the new Agent custom resource and provisions the necessary pod, wiring up the tools and LLM configuration automatically.
Step 4: Interact with your agent
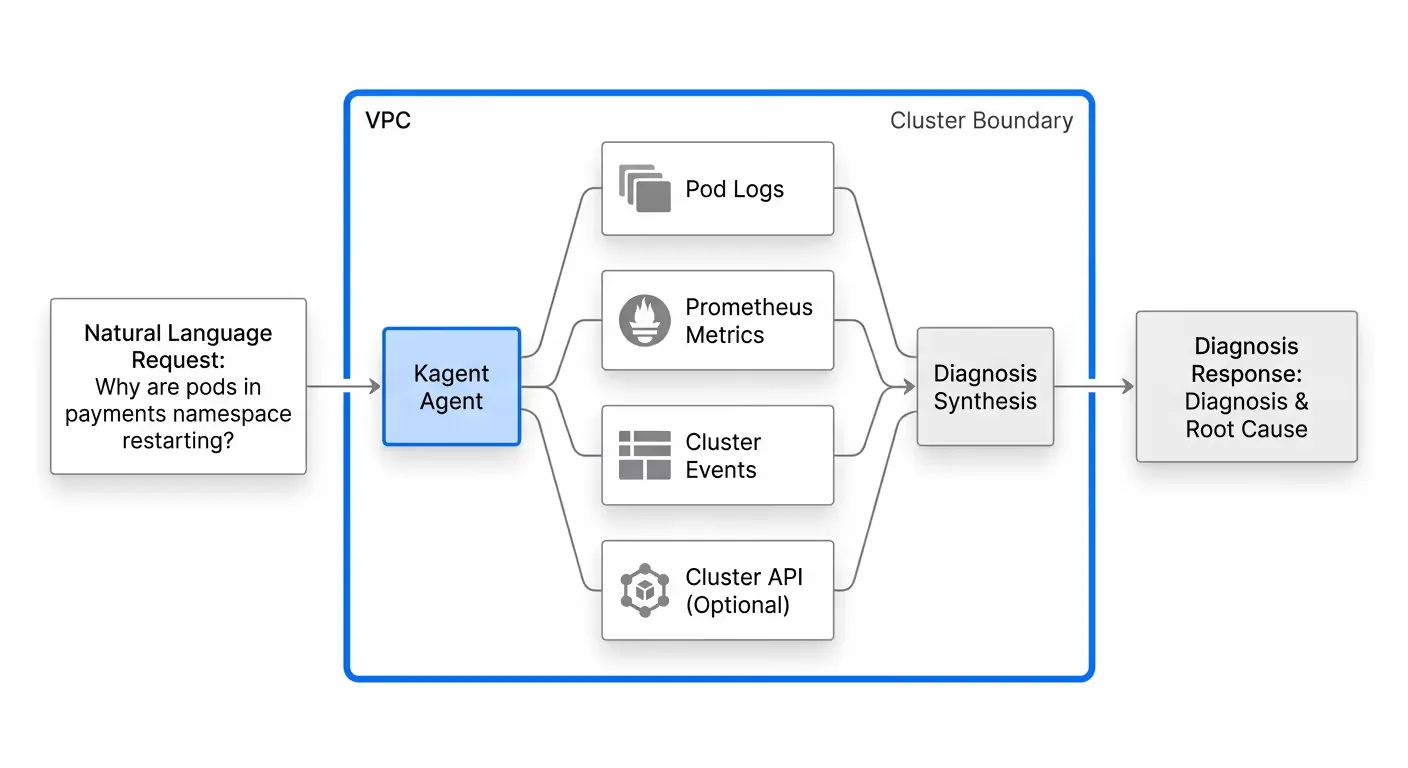
You can now issue natural language requests directly to the agent: "Why are pods in the payments namespace restarting?" The agent will query logs, check recent events, run Prometheus queries, and synthesize a diagnosis — all within your cluster, without any data leaving your environment.
For BYO (Bring Your Own) agents written in LangChain, CrewAI, or Google ADK, kagent supports importing agents from any provider — so if your team is already writing agents in Python with CrewAI, ADK, or LangChain, kagent lets you bring those into the Kubernetes-native runtime. The only additional requirement is containerizing the agent with a Dockerfile.
Getting an agent running in a dev cluster is a 30-minute exercise. Getting it production-ready for a regulated enterprise is a different project entirely. Agents are autonomous and non-deterministic — you cannot predict which agents will talk to other agents or what actions they will take, which presents a complex problem for security, monitoring, and observability. Here are the pillars that actually matter:
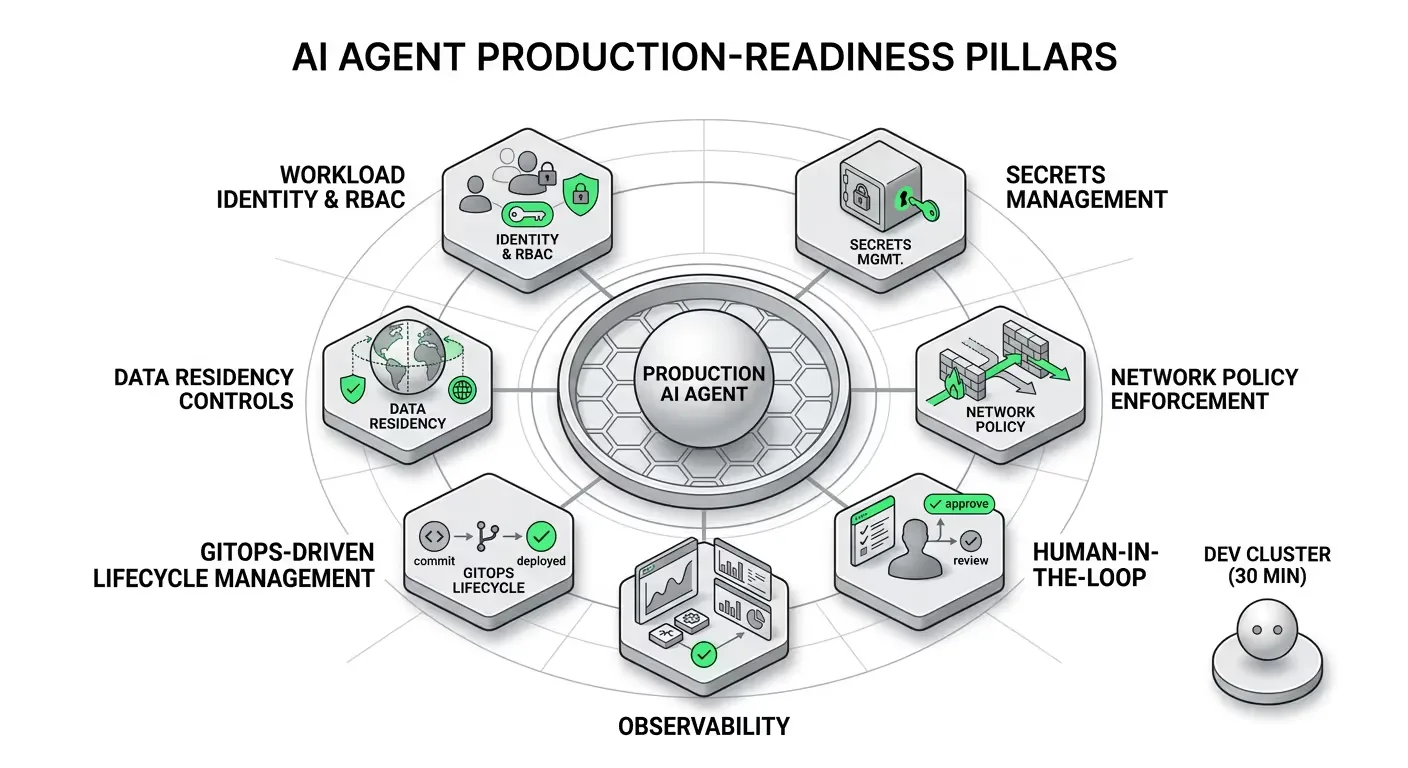
Every agent should run under a dedicated Kubernetes ServiceAccount with namespace-scoped roles granting only the permissions that agent explicitly needs. Dedicated ServiceAccounts prevent privilege creep by ensuring workloads do not share a single identity — a common issue with the default account. An agent that reads pod logs has no business touching Secrets or modifying deployments.
LLM API keys and internal credentials must never be hardcoded in manifests. Use Kubernetes Secrets backed by external vaults, with short rotation cycles. This model becomes brittle at scale, especially for non-deterministic AI systems that spin up and down dynamically — the emerging best practice is eliminating long-lived secrets and replacing them with short-lived, identity-based access that is continuously validated and audited.
For any action that modifies cluster state — scaling a deployment, deleting a resource, triggering a rollback — require explicit human approval before execution. This is not optional in regulated environments; it is a compliance requirement.
AI observability for agents means the ability to monitor and understand everything an agent is doing — not just whether an API returns a response, but what decisions the agent made and why. Traditional app monitoring might tell you a request succeeded; AI observability tells you if the answer was correct, how the agent arrived at it, and whether the process can be improved. Integrate with Prometheus for metrics, OpenTelemetry for traces, and treat agent definitions — their system prompts, tool bindings, LLM configurations — as code. Commit them to Git, review them in pull requests, promote them through environments. The CNCF survey identifies a clear link between operational maturity and the use of standardized platforms, noting that 58% of "cloud native innovators" use GitOps principles extensively, compared to only 23% of "adopters."
For healthcare, finance, and government workloads, data residency is non-negotiable. Run model inference within your own cluster using Ollama or a private model endpoint. Strip PII from any payloads that route to external LLMs. Audit every outbound call.
The pilot-to-production gap is real and well-documented. 65% of enterprise leaders cite agentic system complexity as the number one barrier to deployment. The challenge is not building a prototype — every team can spin up a LangChain agent in an afternoon. The challenge is getting that agent through IT security review, integrated with production data sources, audited for every action, and scaled across a fleet of clusters without fragile DIY orchestration. The full scope of what that transition actually requires is laid out in our guide to taking agentic AI from demo to production.
Gartner predicts that by 2026, 40% of enterprise applications will feature embedded task-specific agents, up from less than 5% in early 2025. That growth trajectory is only achievable if the infrastructure underneath agents is as mature as the agents themselves. Deploying AI agents at scale presents a familiar challenge for DevOps teams: the gap between what works locally and what runs in production. The Model Context Protocol standardizes how AI agents access tools and data sources, but enterprises require more than connectivity — they need authentication, observability, and governance layers that production environments demand.
Kagent addresses the growing complexity of cloud-native operations by automating routine troubleshooting, reducing the need for specialist intervention in common scenarios, and enabling teams to formalize operational expertise. Enterprise-grade capabilities on top of the open source project include advanced management features, observability tools, and multicluster federation support.
For enterprises in healthcare, financial services, and government that cannot route sensitive data through public APIs, the open-source kagent foundation is necessary but not sufficient on its own. What regulated industries need is the full enterprise stack assembled around it: secrets management pre-integrated, network policies pre-enforced, observability pipelines pre-wired, and a compliance-ready audit trail built in from day one.
That is the problem Kaji solves. Kaji is Shakudo's enterprise AI agent — the intelligence layer that runs within Shakudo's AI operating system, which deploys entirely within an organization's own cloud VPC (AWS, Azure, GCP) or on-premises infrastructure. All queries, outputs, and institutional knowledge stay within the enterprise perimeter. External LLMs can be used with zero-retention guarantees, and Shakudo's AI Gateway strips PII and PHI from payloads before they leave the VPC.
Where most platform teams spend months stitching together agent runtimes, LLM configurations, secrets management, and audit pipelines, Shakudo delivers a production-grade kubernetes ai agent environment with 200+ prebuilt connections to data, engineering, and business tools — already running in your cluster, already integrated with Slack and Teams, and already capable of executing complex multi-step workflows across your tech stack. Kaji is human-in-the-loop by design, pausing for approval before irreversible actions, which satisfies the governance requirements that 75% of enterprise leaders cite as their primary deployment blocker.
Kagent open source ai agents kubernetes is the right starting point for any platform team that wants Kubernetes-native agent orchestration without vendor lock-in. The declarative model, the CNCF backing, and the MCP-native tooling architecture are all strong signals of a project with long-term staying power. As CNCF CTO Chris Aniszczyk put it, "Kubernetes is no longer a niche tool; it's a core infrastructure layer supporting scale, reliability, and increasingly AI systems."
For enterprises that cannot spend six months assembling the security and compliance layer themselves, Shakudo wraps that full stack around the kagent paradigm — turning a months-long infrastructure project into a days-long deployment.
Either way, the path to production runs through Kubernetes. The question is how much of it you want to build yourself.
Ready to deploy AI agents in production? Explore Kaji to see how Shakudo delivers a Kubernetes-native enterprise AI agent environment — data-sovereign, compliance-ready, and pre-integrated with your existing stack.




















