Most enterprise AI agents fail not because the models lack intelligence, but because they are architected as isolated software novelties rather than governed, enterprise-grade workflows. The industry is currently witnessing a mass extinction of pilot projects—over 40% of initiatives abandoned by 2025—driven by a fundamental misunderstanding of infrastructure, security, and orchestration constraints. This guide satirically explores the architectural "anti-patterns" that guarantee scalability failure—from vendor lock-in and fragmented DevOps to the "Shadow AI" insurgency—and details how a unified operating system approach solves the "last mile" problem to enable genuine production value.
The artificial intelligence revolution, promised to us in breathless keynote speeches and glossy whitepapers for the better part of three years, has ostensibly arrived. Yet, if one were to walk into the average Fortune 500 boardroom today, the prevailing atmosphere is not one of triumphant innovation, but rather a bewildered frustration. The conversation has shifted dramatically from the speculative excitement of "How can we use Generative AI?" to the hard-nosed financial reality of "Why is our cloud bill $2 million higher this quarter with absolutely nothing to show for it?" and "Why did our customer support bot just offer a user a 90% discount on a legacy product we no longer manufacture?"
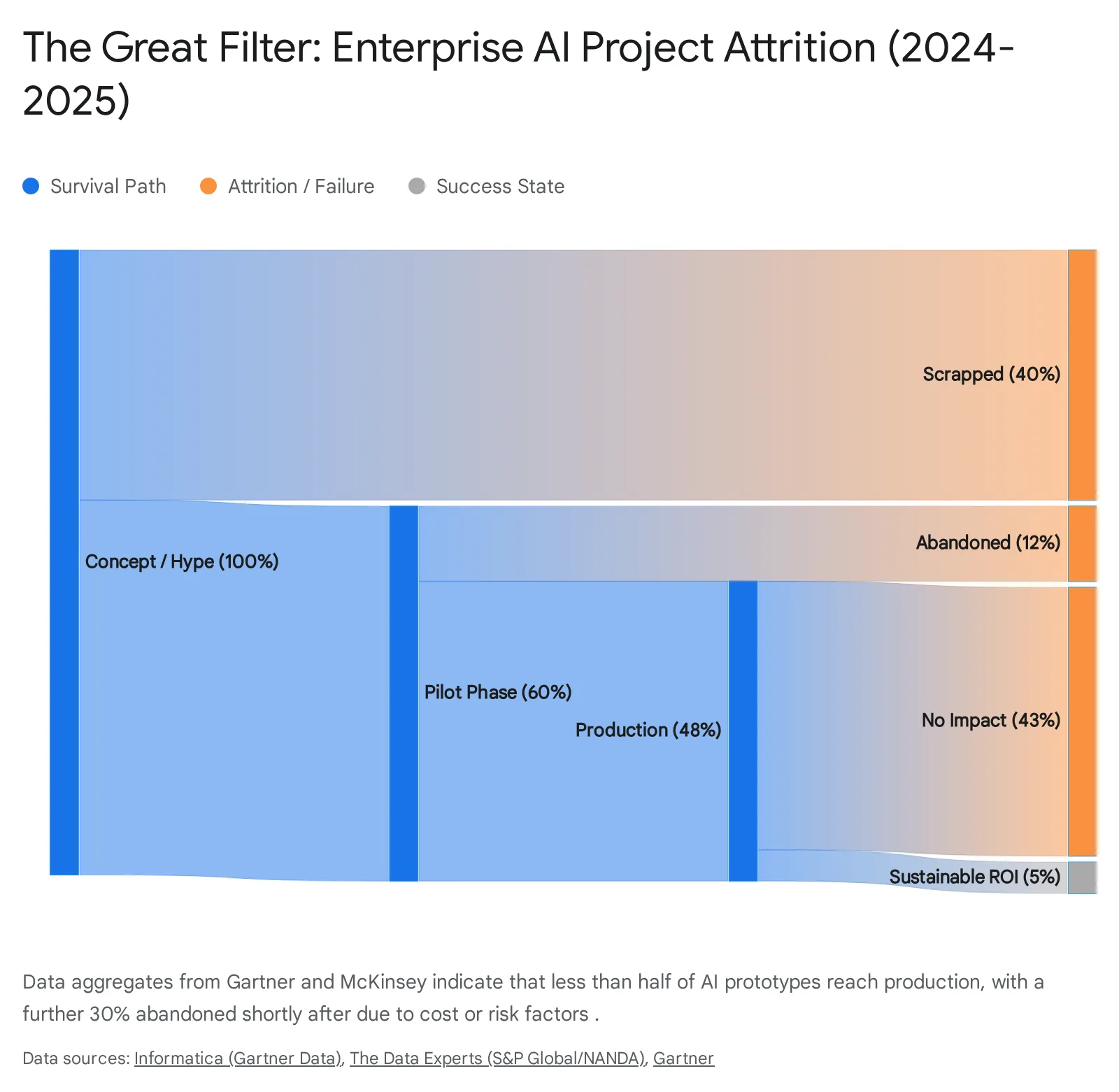
We are standing amidst the wreckage of the "Pilot Phase." The industry consensus is brutal and the statistics are damning. According to recent data from major analyst firms, the failure rate of AI projects is not just persisting; it is accelerating as the complexity of agentic workflows increases. The estimated that at least 30% of Generative AI projects will be abandoned completely after the proof-of-concept (POC) stage due to unclear business value, escalating costs, or inadequate risk controls. Even more alarmingly, data suggests that 95% of enterprise AI pilots fail to achieve rapid revenue acceleration, meaning that the vast majority of implementations are failing to deliver meaningful business impact despite massive capital injection.
Why is this happening? It is not because the Large Language Models (LLMs) aren't smart enough. It is because enterprises are building AI agents using the architectural equivalent of duct tape and prayers. They are treating autonomous agents like chatbots, ignoring the crushing weight of the "DevOps Tax," the insidious creep of Shadow AI, and the financial hemorrhage of cloud egress fees.
We are witnessing a mass extinction event for AI Pilots. This report is your survival guide. But to survive, you must first understand exactly how to die. In the following sections, we will rigorously examine the architectural decisions that guarantee failure. We will outline the specific steps you must take if you wish to build an unscalable, insecure, and prohibitively expensive AI agent ecosystem. We will explore the "Anti-Patterns"—the traps that look like shortcuts but are actually dead ends.
The roadmap to failure is paved with good intentions and bad infrastructure. Let us walk it together, so that you might eventually choose the other path.
The first and most effective way to ensure your AI initiative fails at scale is to bet the entire farm on a single, proprietary model provider. This is the "Walled Garden" trap. It is seductive because it is easy. In the early days of a POC, friction is the enemy. You get an API key, you send a prompt, you get a response. It feels like magic. It requires no infrastructure, no GPU management, and no complex networking.
But in the enterprise, "magic" is just another word for "unmanageable technical debt" waiting to mature. By 2025, the cracks in the "API Wrapper" strategy have become chasms.
To truly fail, you must design your architecture such that your core business logic is tightly coupled to a specific vendor's API (e.g., relying exclusively on OpenAI's Assistants API or a closed ecosystem like Microsoft's Copilot Studio). Do not build an abstraction layer. Do not use open standards. Hardcode your prompts to the quirks of a specific model version that might be deprecated in six months.
Why this guarantees failure:
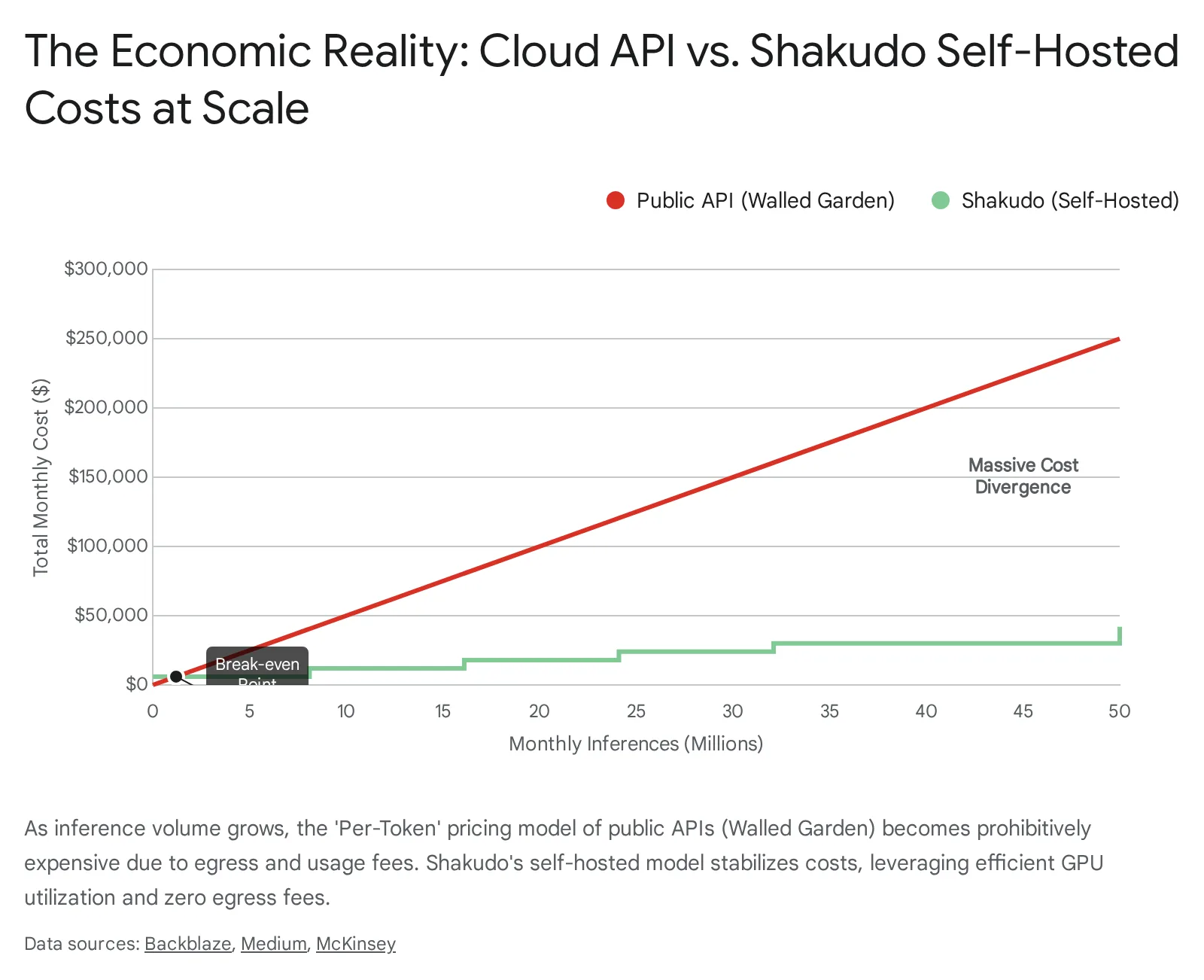
Every time your agent "thinks," it requires context. In a sophisticated RAG (Retrieval-Augmented Generation) system—the standard for any enterprise utility—this means sending massive chunks of your proprietary data out of your VPC (Virtual Private Cloud) to the vendor's API. Cloud providers charge heavily for data egress.
As your agent scales from 100 users to 10,000, your egress fees will scale linearly, or even exponentially if you are using agentic loops that require multiple reasoning steps per user request. Recent studies from Backblaze and Dimensional Research in 2025 indicate that 95% of organizations report "surprise" cloud storage fees, often driven by these steep egress costs. The cost of moving data is cited by 58% of respondents as the single biggest barrier to realizing multi-cloud strategies. If you want to bleed budget, design a system that requires moving petabytes of vector embeddings across the public internet every time a customer asks a question.
When you rely on a public API, you are competing for compute with every teenager generating memes, every student cheating on an essay, and every other startup building a wrapper. You have absolutely no control over inference speeds.
For an internal agent trying to automate a real-time financial trade or a customer support verification, a 3-second latency spike is a broken product. While a 5-second wait might be acceptable for a casual chat, it is catastrophic for an autonomous agent embedded in a high-frequency trading loop or a real-time fraud detection system. Public APIs are "best effort" services; enterprise SLAs require determinism. By relying on the Walled Garden, you abdicate control over your application's heartbeat.
By sending PII (Personally Identifiable Information) or sensitive IP to a public model, you are creating a compliance nightmare. Even with "Zero Data Retention" agreements, the data still leaves your boundary. It traverses public networks and is processed on servers you do not own, in jurisdictions you may not control.
For banks, defense contractors, and healthcare providers, this is a non-starter. It is a ticking time bomb that will eventually detonate during a security audit or a regulatory review. We have already seen instances where employees inadvertently fed proprietary source code into public models for debugging, only for that code to potentially resurface in responses to other users. To fail effectively, ignore these risks. Assume that the "Enterprise" checkbox on the vendor's pricing page indemnifies you against all data leakage. It does not.
The antidote to the Walled Garden is an Operating System approach, like Shakudo. Shakudo allows you to host open-source models (like Llama 3, Mistral, Mixtral) inside your own infrastructure. You bring the compute, Shakudo brings the orchestration.
If you want your AI project to fail via a catastrophic security breach, simply ignore the phenomenon of "Shadow AI." Assume that if IT hasn't approved it, it isn't happening. Assume that your Acceptable Use Policy (AUP) is a magical shield that prevents employees from taking the path of least resistance.
The Reality:
Your employees are already using AI. They are effectively running a parallel IT organization on their personal credit cards and home Wi-Fi. They are pasting proprietary code into ChatGPT to debug it. They are uploading customer CSVs to "PDF Chat" tools to summarize them. They are connecting their work calendars to "Scheduling Agents" that scrape meeting notes.
The statistics are terrifying for any CISO:
To maximize risk and ensure your organization ends up in a headline, follow this blueprint:
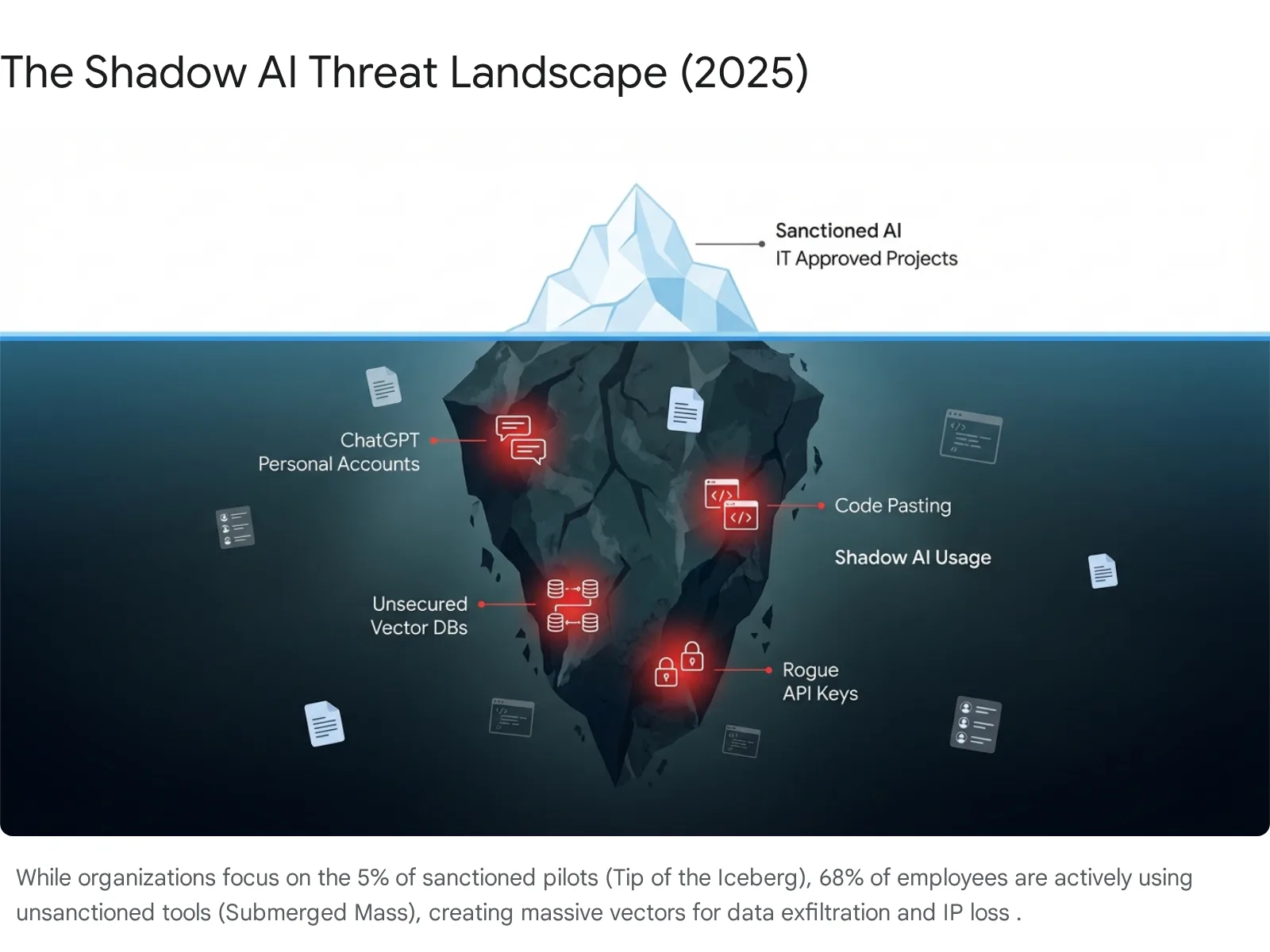
You cannot ban AI. You must govern it. Shakudo provides a centralized control plane for all AI activities, turning Shadow AI into Sanctioned AI.
This is the most technical and painful way to fail. It involves underestimating the sheer complexity of the modern AI technology stack. It relies on the hubris of believing that your data science team can also be your platform engineering team, your security team, and your site reliability engineering team.
To build a modern AI agent, you need more than just a model. You need a symphony of distributed systems:
To ensure failure, attempt to stitch these tools together manually using bespoke scripts, fragile connections, and hope.
Python environment management is a solved problem, right? Wrong. In the AI world, it is a nightmare. Try getting torch (for your model), apache-airflow (for scheduling), and ray (for scaling) to play nicely in the same Docker container.
You will enter "Dependency Hell." A requirement for numpy version 1.21 in one library conflicts with version 1.24 in another. You spend days debugging cryptic error messages about shared object files and CUDA driver mismatches.
Deploy your inference server (e.g., Ollama) on a standard Kubernetes cluster without specialized autoscaling logic.
Try to build a "Customer Insight Agent" that syncs data from Salesforce to a Vector DB (Qdrant) in real-time.
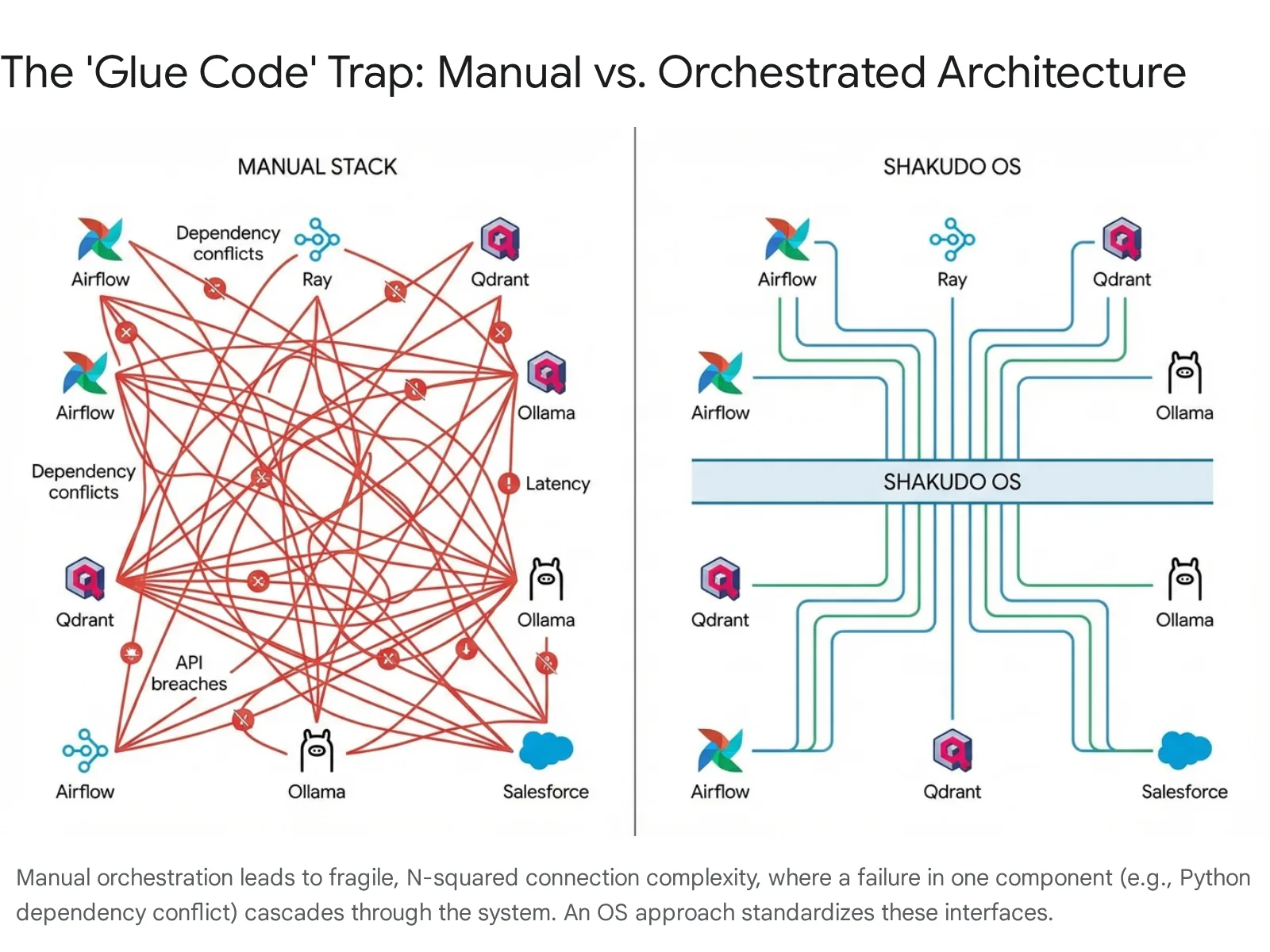
Shakudo solves the DevOps Abyss by acting as an Operating System. It abstracts the underlying infrastructure complexity.
The newest and most exciting way to fail is with "Agentic AI." This moves beyond simple Q&A to autonomous agents that do things: "Refund this transaction," "Update the CRM," "Deploy this code."
To fail here, build an agent using a basic framework (like a raw LangChain loop) without strict state management or governance. Give it access to tools and let it run.
The Failure Mode:
Let's look at a concrete example of how these traps manifest in a real business scenario. This is a technical post-mortem of a project that failed, contrasted with the blueprint of one that succeeded.
The Goal: Build an agent that answers customer queries about order status and, if necessary, updates the customer's shipping address in Salesforce.
The fundamental premise of Shakudo is that the "Modern Data Stack" has become too fragmented to manage manually. The "Anti-Patterns" described above are symptoms of a deeper problem: the lack of a unified control plane. Shakudo acts as a unification layer—an Operating System—that sits between your infrastructure (AWS, Azure, GCP, On-Prem) and your tools.
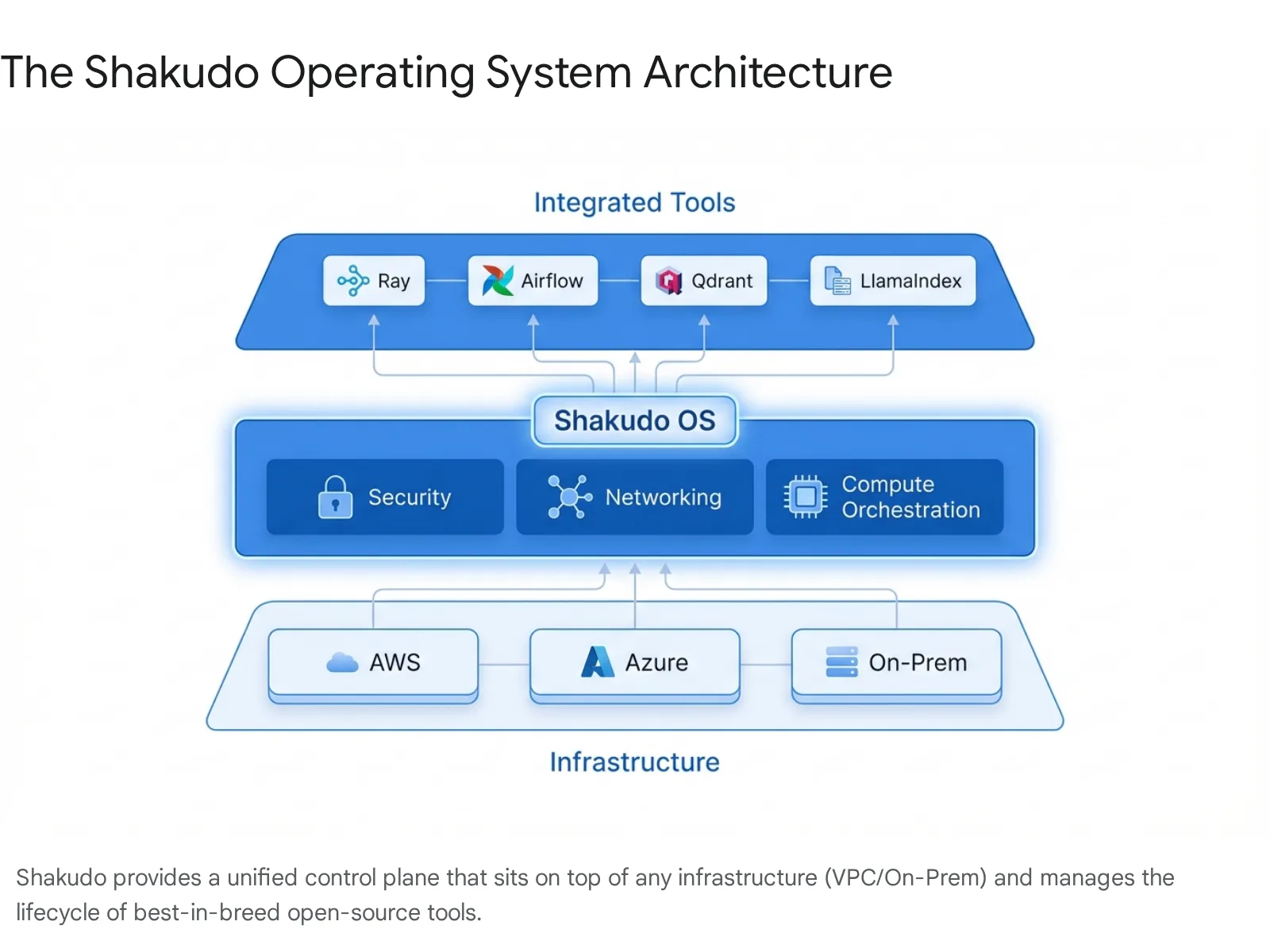
In an era of increasing regulation and cyber warfare, data sovereignty is not a luxury; it is a mandate. Shakudo deploys entirely within your environment.
The AI field is moving too fast to bet on a single horse. Today, Qdrant might be the best vector DB. Tomorrow, it might be something else.
Most agent frameworks (like LangChain) are code-heavy and difficult to govern. Visual builders (like Zapier) are too simple for enterprise logic. AI Gateway: Shakudo fully supports the Model Context Protocol (MCP) through the Shakudo AI Gateway, allowing agents to securely connect to data sources and tools across the enterprise without custom integrations. The AI Gateway acts as a secure governance layer, managing authentication, access control, and token usage for these connections.
The high failure rate of AI is not a failure of the technology's potential; it is a failure of infrastructure strategy. Organizations are trying to build skyscrapers on quicksand. They are piloting complex agents on fragile, manual, insecure stacks that collapse under the pressure of production scale.
To build AI agents that don't fail:
Shakudo is that Operating System. It is the difference between a cool demo that dies in a month and a transformational asset that scales for a decade.
The choice is yours: You can keep debugging Terraform scripts and paying egress fees, or you can start building.