

The physics of latency are forcing a fundamental rearchitecture of enterprise AI infrastructure. While cloud-based LLMs dominated 2023-2024, enterprises deploying AI in manufacturing facilities, healthcare clinics, and retail environments are hitting hard limits: round-trip network latency, unpredictable cloud costs, and regulatory requirements that prohibit sending sensitive data off-premises. The solution isn't bigger cloud models. It's compact, edge-optimized LLMs running where decisions actually happen.
Three converging challenges are making cloud-only AI architectures untenable for many enterprise use cases.
First, data sovereignty regulations in healthcare (HIPAA), finance (GDPR, SOC 2), and manufacturing (ITAR) explicitly restrict where sensitive data can be processed. Sending patient records, financial transactions, or proprietary manufacturing data to third-party cloud APIs creates compliance exposure that legal and security teams won't accept. This isn't theoretical risk. It's blocking AI adoption in regulated sectors. Organizations navigating these requirements need robust SOC 2 compliance frameworks that enable AI deployment while meeting security standards.
Second, latency requirements for real-time decision-making exceed what cloud inference can deliver. A manufacturing quality control system needs sub-100ms response times to flag defects on a production line moving at speed. Even with optimized cloud endpoints, network round-trips add 50-200ms of unavoidable latency before processing begins. For point-of-care diagnostics or autonomous vehicle systems, this delay is operationally unacceptable.
Third, cloud pricing models create unpredictable cost structures at scale. At $0.60 per million tokens for GPT-4 or $0.03 per million for GPT-3.5, a retail chain processing 100 million daily inference requests faces $3,000-60,000 in monthly API costs. These economics don't work for high-volume, low-margin use cases where inference needs to cost fractions of a cent.
The traditional answer has been accepting these tradeoffs. Edge AI changes the equation.
Edge AI deployment requires rethinking model architecture, compression techniques, and inference optimization for resource-constrained environments.
Model Selection and Parameter Efficiency
The breakthrough enabling edge deployment is the maturation of 7-9B parameter models that approach larger model capabilities at a fraction of the computational cost. Models like Meta's Llama-3.1-8B-Instruct, Zhipu's GLM-4-9B, and Alibaba's Qwen2.5-VL-7B demonstrate that intelligent architectural choices (grouped query attention, mixture-of-experts routing, efficient tokenization) deliver production-grade performance without requiring datacenter-scale hardware.
These models run on NVIDIA Jetson edge devices, AWS Panorama appliances, or even high-end server CPUs with 32-64GB RAM. The key constraint isn't whether these devices can run inference, but whether they can do so with acceptable throughput and latency.
Quantization and Compression Strategies
Deploying 8B parameter models on edge hardware requires aggressive optimization. Quantization reduces model precision from 16-bit floating point to 8-bit or 4-bit integers, cutting memory requirements by 50-75% with minimal accuracy degradation. Techniques like GPTQ (post-training quantization) and GGUF (efficient file formats) enable a quantized Llama-3.1-8B to fit in 4-6GB of memory instead of 16GB.
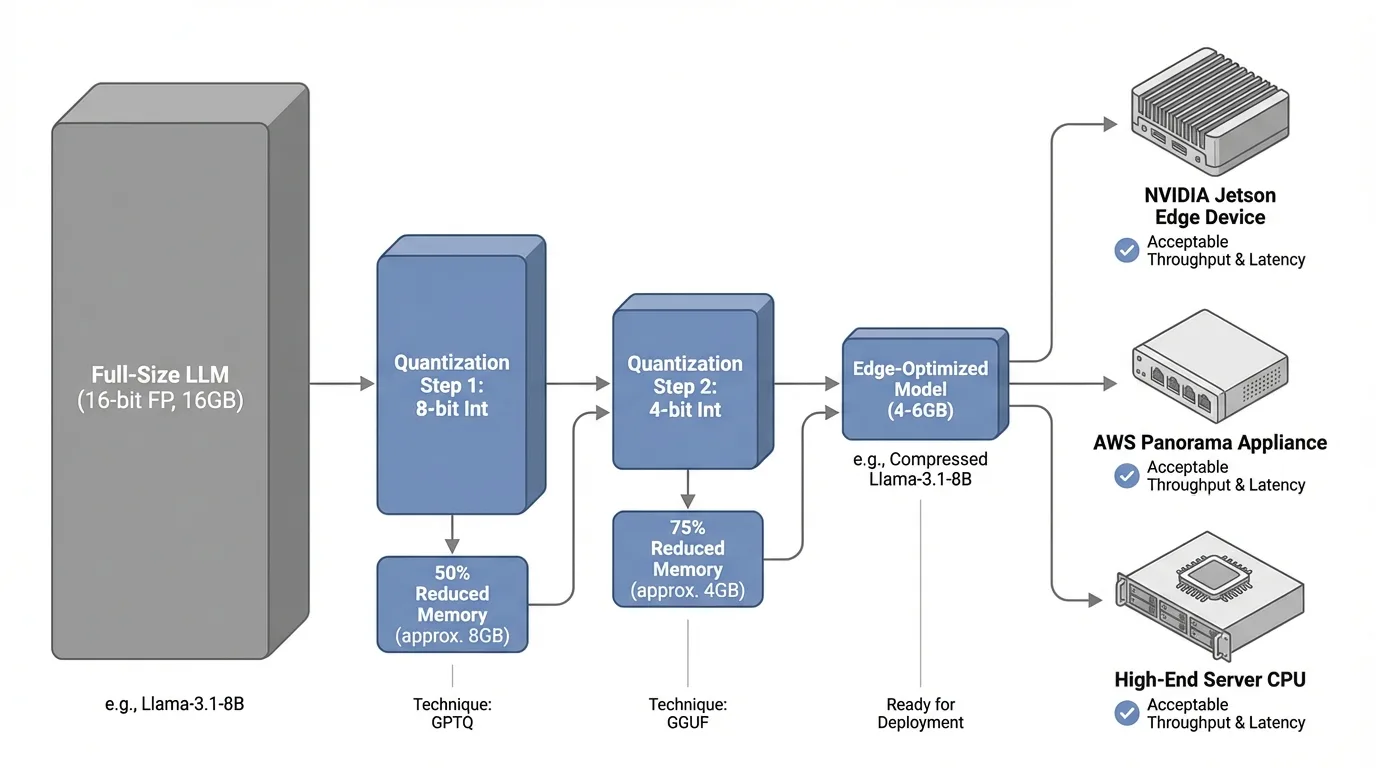
Knowledge distillation further compresses models by training smaller networks to mimic larger teacher models' behavior. The result: edge-deployable models that retain 95%+ of the original model's capabilities while running 3-4x faster.
Inference Optimization and Batching
Edge inference engines like vLLM, TensorRT-LLM, and llama.cpp implement continuous batching, KV cache optimization, and speculative decoding to maximize throughput. These optimizations allow a single edge device to handle 50-200 concurrent inference requests depending on sequence length and hardware specifications.
Benchmark data shows edge-optimized deployments achieving 8-12ms per token generation on NVIDIA Jetson Orin, translating to total inference latencies of 80-120ms for typical requests. This represents a 13% improvement over cloud-based inference when network latency is factored in, and the performance gap widens in bandwidth-constrained or high-latency environments.
The technical capabilities translate into measurable business value across three dimensions.
Cost Predictability and Reduction
Edge deployment shifts from per-token operational costs to fixed capital expenditure. A $5,000-15,000 edge device processing 10 million daily inferences costs $0.05-0.15 per million tokens over a 3-year depreciation period. This is 20-200x cheaper than cloud API pricing for high-volume use cases. More importantly, costs become predictable and linearly scalable with deployment footprint rather than usage spikes.
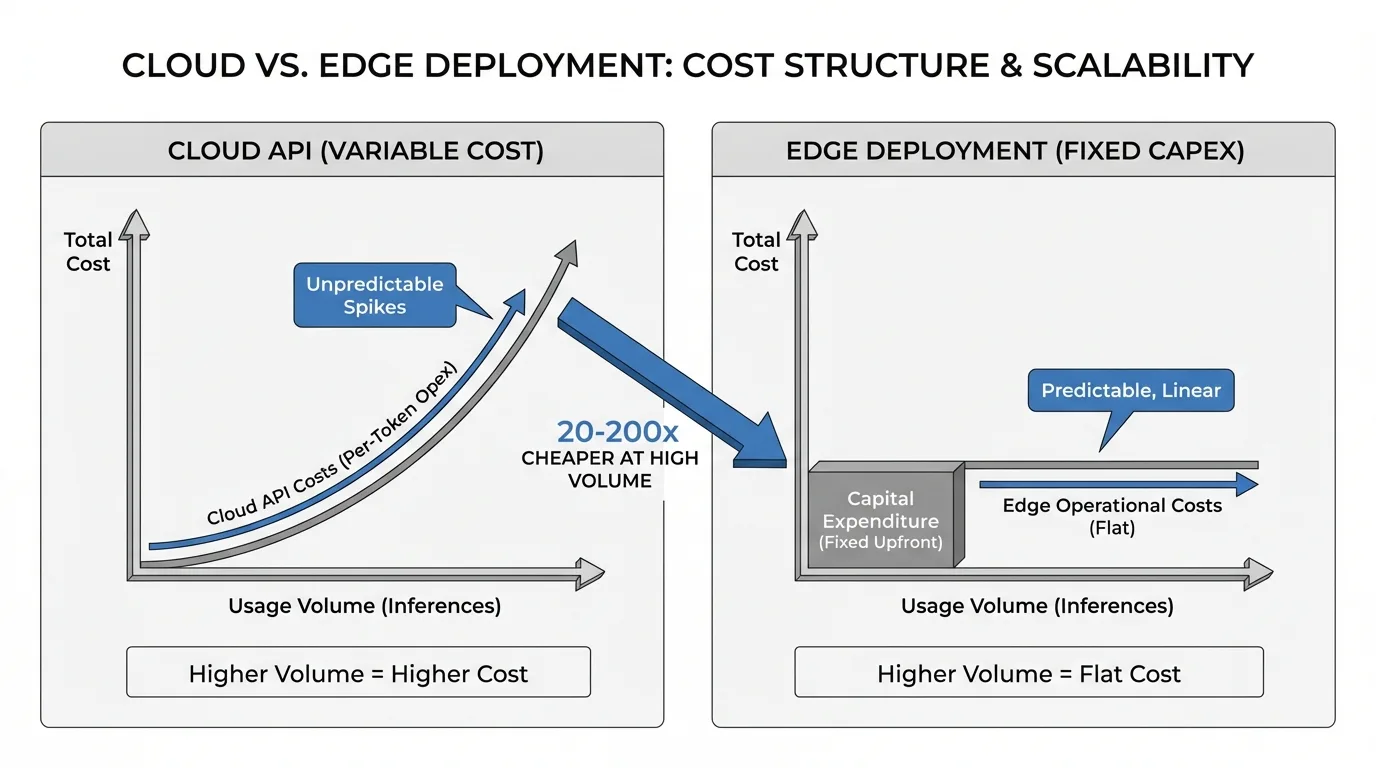
To visualize the impact on your specific operations, use the ROI calculator below to compare your projected cloud API spend against the fixed-cost nature of edge infrastructure.
.comparison-table { width: 100%; border-collapse: collapse; font-size: 12px; border-bottom: 1px solid var(—border); }
.comparison-table th { background-color: var(—black-faded); color: var(—white); text-align: left; padding: 12px; text-transform: uppercase; font-size: 10px; letter-spacing: 0.5px; }
.comparison-table td { padding: 12px; border-bottom: 1px solid var(—border); }
.val-highlight { color: var(—primary-1); font-weight: 600; }
.calc-container { padding: 24px; background-image: linear-gradient(180deg, transparent, rgba(196, 125, 95, 0.05)); }
.calc-header { margin-bottom: 20px; border-left: 3px solid var(—primary-1); padding-left: 12px; }
.calc-header h4 { color: var(—white); margin: 0; font-size: 16px; text-transform: uppercase; letter-spacing: 1px; }
/* Grid for Inputs */ .calc-grid { display: grid; grid-template-columns: 1fr 1fr; gap: 16px; margin-bottom: 20px; }
@media (max-width: 600px) { .calc-grid { grid-template-columns: 1fr; } }
.input-field-group label { display: block; font-size: 10px; color: var(—grey-on-black); margin-bottom: 6px; text-transform: uppercase; }
.input-field-group input { width: 100%; background: #111; border: 1px solid var(—border); color: var(—white); padding: 12px; border-radius: 4px; outline: none; font-size: 16px; box-sizing: border-box; }
/* Slider Styling */ .slider-container { margin-bottom: 24px; background: rgba(255,255,255,0.02); padding: 16px; border-radius: 4px; border: 1px dashed var(—white-faded); }
.slider-label-row { display: flex; justify-content: space-between; margin-bottom: 10px; flex-wrap: wrap; gap: 8px; }
input[type=range] { width: 100%; cursor: pointer; accent-color: var(—primary-1); margin: 10px 0; }
/* Dashboard Cards - Responsive */ .roi-dashboard { display: flex; flex-wrap: wrap; gap: 12px; background: var(—black-faded); border: 1px solid var(—white-faded); padding: 20px; border-radius: 4px; }
.roi-card { flex: 1 1 150px; /* Allows cards to shrink and grow, but wrap when they hit 150px */ min-width: 120px; }
@media (max-width: 480px) { .roi-dashboard { flex-direction: column; text-align: left; } .roi-card { border-bottom: 1px solid var(—border); padding-bottom: 12px; border-right: none; } .roi-card:last-child { border-bottom: none; padding-bottom: 0; text-align: left; } }
.roi-label { font-size: 9px; color: var(—grey-on-black); margin-bottom: 4px; text-transform: uppercase; } .roi-value { color: var(—white); font-size: 20px; font-weight: 700; } .roi-positive { color: var(—primary-1) !important; text-shadow: 0 0 10px var(—glow); } .roi-negative { color: #ff4d4d !important; }
.footer-note { font-size: 10px; color: var(—grey-on-black); margin-top: 16px; font-style: italic; line-height: 1.4; }
| Metric | Cloud | Edge |
|---|---|---|
| Sovereignty | Risk | Zero Leak |
| Latency | 250ms+ | 40-120ms |
| Scaling | Linear | Fixed |
<div class="calc-grid">
<div class="input-field-group">
<label>Daily Tokens (Millions)</label>
<input type="number" id="tokenVol" value="1500" oninput="runEnterpriseCalc()">
</div>
<div class="input-field-group">
<label>Cloud Price ($/1M)</label>
<input type="number" id="apiPrice" value="0.60" step="0.1" oninput="runEnterpriseCalc()">
</div>
</div>
<div class="slider-container">
<div class="slider-label-row">
<label class="roi-label">Utilization: <span id="utilValue" style="color:var(--white);">97%</span></label>
<span style="font-size: 9px; color: var(--grey-on-black);">(Adjust for spiky traffic)</span>
</div>
<input type="range" id="utilSlider" min="5" max="100" value="97" oninput="runEnterpriseCalc()">
</div>
<div class="roi-dashboard">
<div class="roi-card">
<div class="roi-label">3-Year Cloud Spend</div>
<div id="cloudTotal" class="roi-value">$0</div>
</div>
<div class="roi-card">
<div class="roi-label">Payback</div>
<div id="paybackValue" class="roi-value">--</div>
</div>
<div class="roi-card">
<div class="roi-label">ROI</div>
<div id="savingsPercent" class="roi-value">0%</div>
</div>
</div>
<p class="footer-note">*Assumes $250k CAPEX and $3.5k/mo ops. Low utilization favors Cloud OpEx.</p>Regulatory Compliance and Data Sovereignty
On-premises edge deployment means sensitive data never leaves the facility network perimeter. Healthcare providers can analyze patient data for diagnostic assistance without HIPAA violations. Financial institutions can run fraud detection on transaction data without cross-border data transfer concerns. Manufacturers can apply AI to proprietary designs without intellectual property exposure.
This isn't just about avoiding violations. It's about enabling AI use cases that were previously off-limits.
Operational Resilience
Edge AI eliminates cloud connectivity as a single point of failure. A manufacturing facility with edge-deployed quality control continues operating during internet outages. A retail store's inventory optimization system works regardless of WAN availability. This resilience matters in distributed environments where connectivity can't be guaranteed.
These capabilities are enabling new deployment patterns across industries.
In manufacturing, automotive suppliers deploy Llama-based vision models for real-time defect detection on assembly lines. The models analyze camera feeds at 30fps, flagging anomalies with 98%+ accuracy while keeping proprietary part designs on-premises. Prior cloud-based approaches couldn't meet latency requirements and created IP exposure risks.
Healthcare systems use edge-deployed GLM-4-9B for clinical decision support at point-of-care. Physicians query patient histories, lab results, and treatment protocols with natural language, receiving contextualized recommendations in under 200ms without patient data leaving the clinic network. This addresses both HIPAA requirements and the practical reality that many healthcare facilities have limited bandwidth.
Retail chains deploy Qwen2.5-VL-7B for visual inventory management and customer analytics. Edge devices in each store process security camera feeds to track stock levels, identify theft patterns, and analyze traffic flows. Processing locally reduces bandwidth costs (no need to stream video to cloud) and enables real-time alerting that wouldn't be practical with cloud round-trips. For sales-focused applications, similar AI approaches can analyze sales call transcripts to identify winning strategies and optimize customer interactions.
Successful edge AI deployment requires addressing several technical and operational challenges.
Hardware Selection and Provisioning
Teams need to right-size edge hardware based on inference load, concurrency requirements, and latency budgets. NVIDIA Jetson Orin (32GB) handles 20-40 concurrent requests with sub-100ms latency for 8B models. Higher throughput scenarios may require server-grade hardware with A10 or L4 GPUs.
Model Management and Updates
Distributed edge deployments require robust model versioning, A/B testing infrastructure, and remote update mechanisms. Organizations need processes to validate new model versions, gradually roll them out across edge locations, and roll back if issues arise. This operational overhead is nontrivial for enterprises managing hundreds of edge locations.
Monitoring and Observability
Edge deployments need centralized monitoring for inference latency, throughput, error rates, and hardware utilization across distributed devices. Without proper observability, diagnosing performance issues or capacity constraints becomes extremely difficult.
API Compatibility and Integration
Deploying OpenAI-compatible API endpoints on edge devices allows existing applications built for cloud LLM APIs to work with minimal code changes. Tools like vLLM and TensorRT-LLM provide OpenAI-compatible serving layers that standardize integration patterns.
The technical components for edge AI exist, but orchestrating them across distributed infrastructure remains complex. Organizations need to manage model deployment, inference serving, monitoring, data pipelines, and integration with existing systems across potentially hundreds of edge locations.
This is where platforms that provide unified orchestration become valuable. Shakudo enables enterprises to deploy edge-optimized LLMs like Llama-3.1-8B and Qwen2.5 within their own VPCs and edge infrastructure while maintaining centralized control over the complete AI stack. Rather than assembling and managing dozens of individual tools, teams get integrated orchestration of model serving, data pipelines, monitoring, and the 170+ open-source AI tools needed for production deployments. Financial institutions, in particular, have successfully operationalized MLOps at scale using similar platform approaches to manage complex, distributed AI infrastructure.
The platform approach addresses the operational gap between having the technical capability to run edge AI and actually doing it reliably at scale across distributed infrastructure.
Edge AI with compact LLMs represents a fundamental shift in enterprise AI architecture, not a temporary workaround. As models continue improving and edge hardware becomes more capable, the economic and technical advantages of processing data where it's generated will only strengthen.
For enterprises in regulated industries or operating distributed physical infrastructure, edge deployment isn't optional. It's the only path to AI adoption that satisfies data sovereignty requirements while delivering the low-latency performance real-time operations demand.
The question isn't whether to move AI to the edge, but how quickly your organization can build the capabilities to do so effectively. Start by identifying high-value use cases where latency, compliance, or cost make cloud inference impractical. Evaluate compact models against your performance requirements. And invest in the infrastructure and processes needed to deploy and manage AI across distributed environments.
The enterprises that master edge AI deployment will have a significant operational advantage over those still dependent on centralized cloud architectures. The technology is ready. The question is whether your infrastructure is.




















