

The best AI models require vast amounts of data. Yet the most valuable enterprise data cannot be moved, shared, or centralized due to regulatory constraints, competitive concerns, or sovereignty requirements. This creates an impossible choice: either accept limited AI capabilities trained on siloed data, or violate compliance boundaries to aggregate information. In 2025, as sovereign AI becomes critical infrastructure comparable to power grids and telecommunications networks, this tension has reached a breaking point.
Federated learning resolves this paradox by inverting the traditional machine learning paradigm.
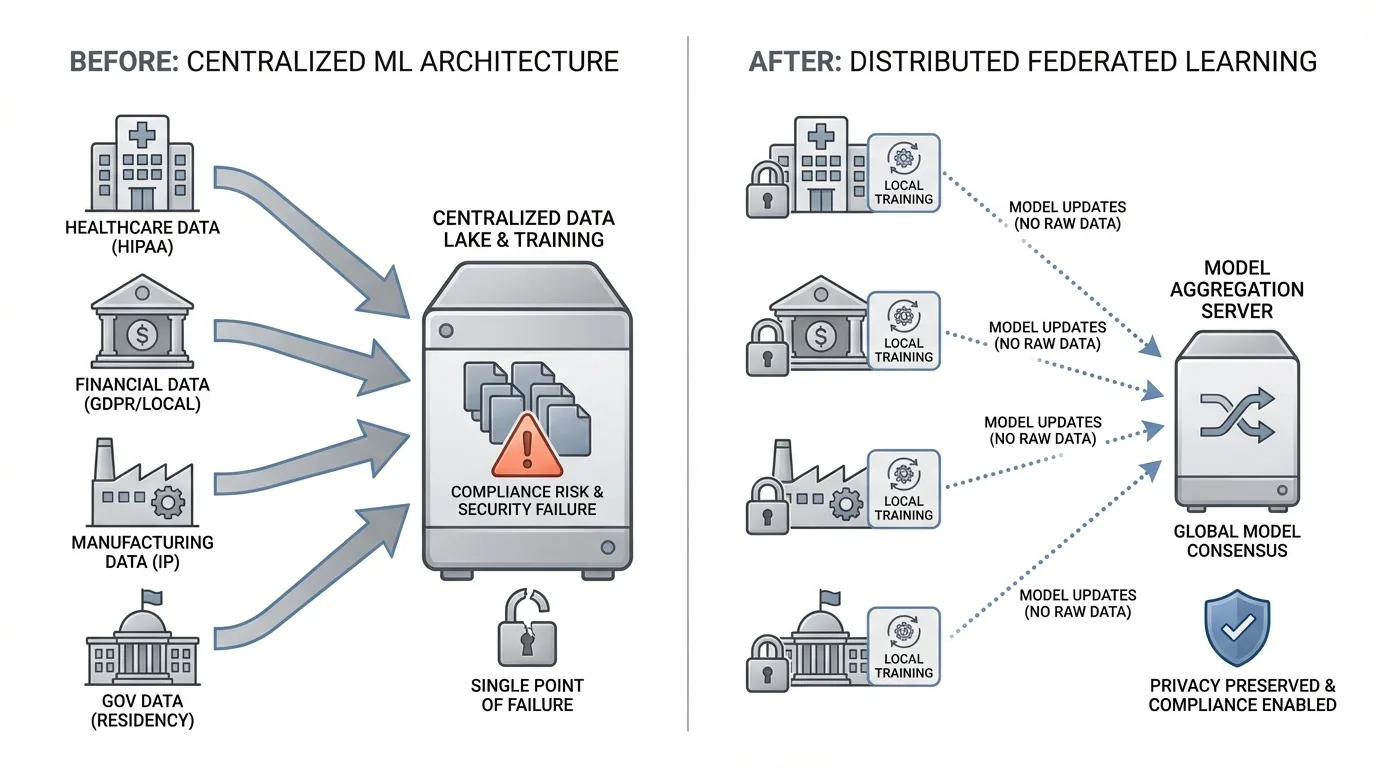
Traditional machine learning architectures assume data centralization. You collect datasets from various sources, aggregate them in a single location, and train models on the combined information. This approach worked well when data privacy was an afterthought and regulatory frameworks were nascent.
Today's reality is fundamentally different. Healthcare organizations cannot share patient records across hospital networks due to HIPAA regulations. Financial institutions face prohibitive restrictions on cross-border transaction data movement under GDPR and local banking laws. Manufacturers cannot expose proprietary operational data from facilities to centralized cloud environments without risking intellectual property theft. Government agencies must maintain data residency within national boundaries.
The cost of non-compliance is staggering. GDPR violations can reach 4% of global annual revenue. Healthcare breaches average $10.93 million per incident. Beyond regulatory penalties, centralized data architectures create single points of failure for security breaches and limit participation from organizations unwilling to expose sensitive information.
Yet the pressure to leverage AI continues intensifying. Organizations with distributed data silos are watching competitors gain advantages from machine learning while remaining unable to utilize their own distributed datasets.
Federated learning fundamentally restructures the training process by moving computation to data rather than data to computation.
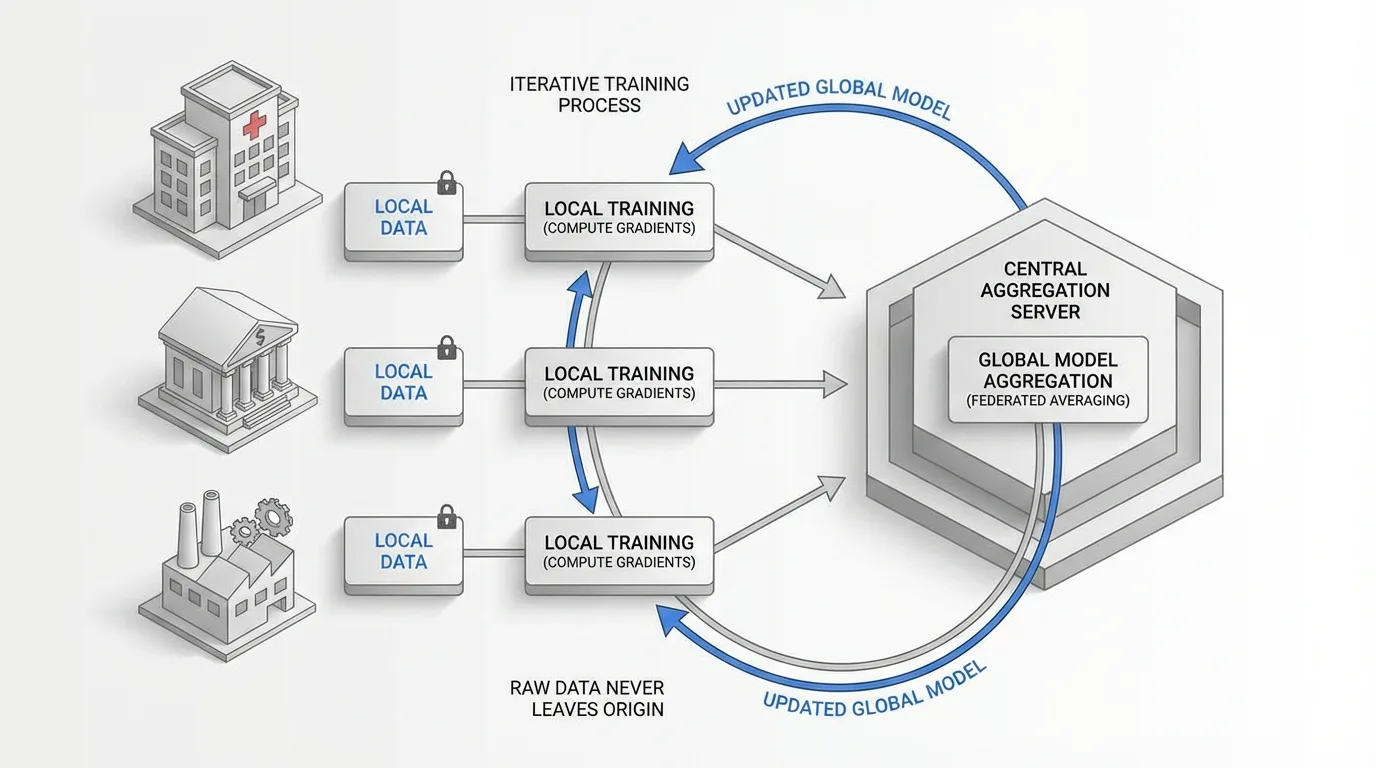
Instead of centralizing raw data, federated learning keeps information distributed across its original locations (edge devices, regional servers, organizational boundaries). The training process occurs locally on each node using that node's private dataset. Only model updates, specifically gradients or parameters, are transmitted to a central aggregation server.
The central server combines these updates using aggregation algorithms (typically federated averaging) to produce an improved global model. This updated model is then distributed back to participating nodes for the next training round. The process iterates until the model converges to optimal performance.
Critically, raw data never leaves its origin location. A hospital trains on its patient records locally. A bank processes its transaction data within its own infrastructure. A factory analyzes operational metrics on-premises. The learning happens collaboratively, but the data remains sovereign.
Modern frameworks like NVIDIA FLARE (Federated Learning Application Runtime Environment) and Flower provide production-ready infrastructure for enterprise federated learning. NVIDIA FLARE offers a domain-agnostic platform with built-in security features, support for heterogeneous computing environments, and integration with popular ML frameworks like PyTorch and TensorFlow. Flower provides a flexible Python framework that simplifies federated learning implementation across diverse architectures.
These tools handle the complex orchestration required for distributed training: secure communication protocols, differential privacy mechanisms, client selection strategies, and fault tolerance. What once required extensive custom development is now accessible through standardized frameworks.
While regulatory compliance drives initial interest in federated learning, the strategic advantages extend far deeper.
Data sovereignty becomes operationalized rather than aspirational. Organizations maintain complete control over their data assets while participating in collaborative learning initiatives. This aligns perfectly with the sovereign AI paradigm where nations and enterprises must control their AI capabilities using their own infrastructure, data, and workforce.
Competitive collaboration becomes possible. Competitors within an industry can jointly train better models without exposing proprietary information. Banks can collaboratively improve fraud detection while keeping customer data private. Hospitals can build superior diagnostic models without sharing patient records. The collective intelligence improves outcomes for all participants without compromising competitive positions.
Edge intelligence scales naturally. Federated learning architectures inherently support edge deployment scenarios where data generation occurs on distributed devices. Manufacturing sensors, retail point-of-sale systems, and IoT networks can contribute to model training without overwhelming network bandwidth or creating centralized data bottlenecks.
Model performance often exceeds centralized alternatives. Federated learning preserves the natural distribution of data across its sources, which can produce models that generalize better to real-world heterogeneity than those trained on artificially homogenized centralized datasets.
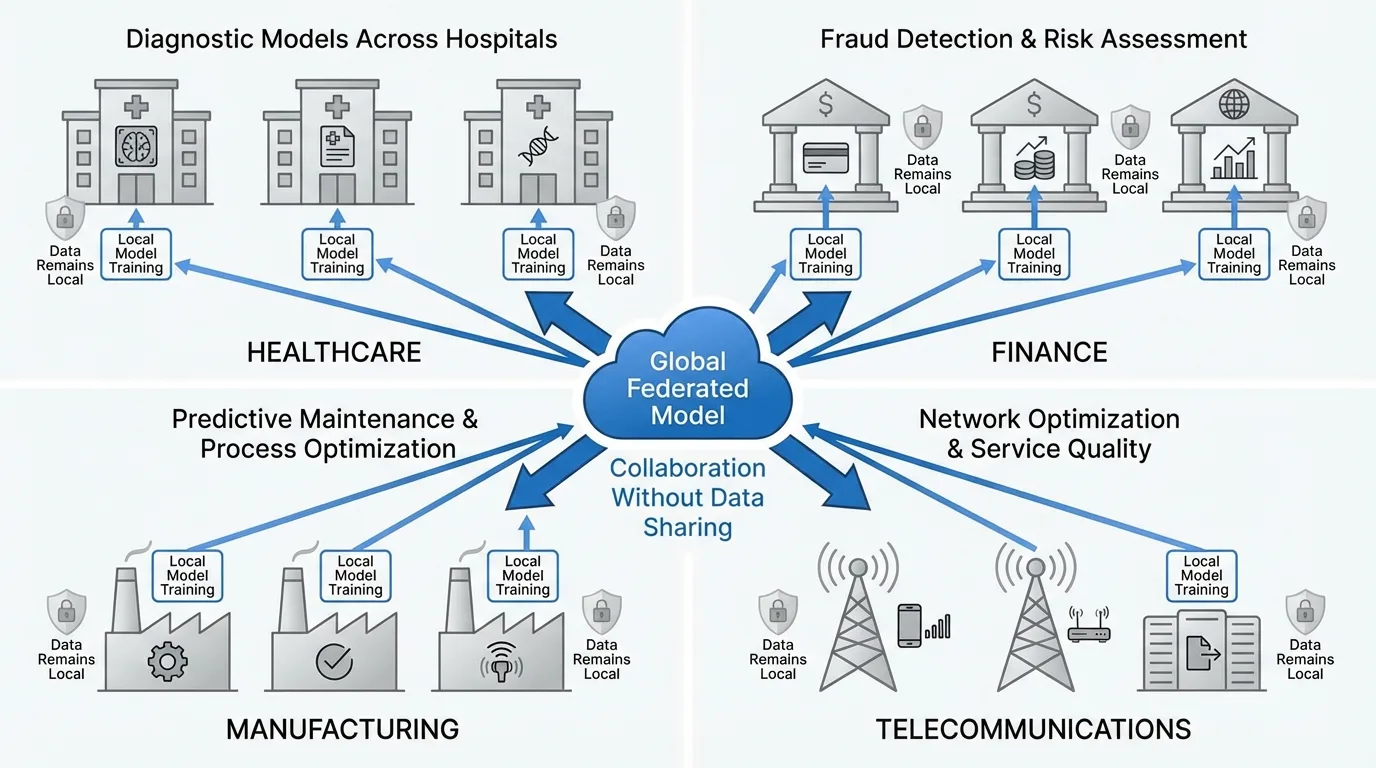
Healthcare organizations are deploying federated learning to build diagnostic models across hospital networks. Multiple institutions collaborate to train models on medical imaging, electronic health records, or genomic data while patient information never leaves each facility. The resulting models benefit from diversity across patient populations, geographic regions, and clinical practices without creating privacy vulnerabilities.
Financial institutions use federated learning for fraud detection and risk assessment across regional branches or international subsidiaries. Transaction patterns, credit behaviors, and market signals remain within regulatory boundaries while contributing to globally optimized models. This is particularly critical for international banks navigating conflicting data residency requirements and operationalizing MLOps across jurisdictions.
Manufacturing enterprises implement federated learning to optimize production processes across global facilities. Operational parameters, quality metrics, and equipment sensor data from factories worldwide contribute to predictive maintenance and process optimization models without exposing proprietary manufacturing techniques to centralized repositories.
Telecommunications providers leverage federated learning for network optimization and predictive maintenance across distributed infrastructure. Cell towers, edge nodes, and regional data centers contribute to models that improve service quality while network configuration and usage patterns remain localized.
Successful federated learning deployments require careful architectural planning.
Communication efficiency becomes critical. Unlike centralized training where data transfer happens once, federated learning requires multiple rounds of model update exchange. Organizations must optimize communication protocols, implement gradient compression techniques, and carefully schedule update frequencies to balance model performance against bandwidth constraints.
Heterogeneity management presents unique challenges. Participating nodes often have different computational capabilities, data distributions, and availability patterns. Robust federated learning implementations must handle stragglers, adapt to non-IID (non-independent and identically distributed) data, and maintain training progress despite intermittent node participation.
Security and privacy require defense-in-depth approaches. While federated learning inherently improves privacy by avoiding data centralization, model updates can still leak information through inference attacks. Production deployments should implement differential privacy, secure aggregation protocols, and encrypted communication channels. Organizations pursuing SOC 2 compliance must ensure their federated learning architecture meets stringent security requirements.
Infrastructure requirements differ significantly from centralized ML. Organizations need secure aggregation servers, identity management systems for node authentication, monitoring infrastructure for distributed training visibility, and orchestration platforms that can coordinate across organizational or geographic boundaries.
Implementing production-grade federated learning requires infrastructure that maintains data sovereignty while orchestrating complex distributed workflows. Organizations need to deploy and manage frameworks like NVIDIA FLARE and Flower within their own controlled environments, integrate them with existing ML pipelines and data infrastructure, and ensure all components operate within compliance boundaries.
Shakudo's deployment of 170+ AI tools within customer VPCs provides the foundation for these federated learning architectures. By operating entirely within customer-controlled infrastructure, organizations can orchestrate distributed training workflows while ensuring all data, models, and compute remain sovereign. This vendor-independent approach aligns with the fundamental requirements of both federated learning and sovereign AI, where control over the complete technology stack is non-negotiable.
Federated learning represents more than a technical architecture. It embodies a fundamental shift in how organizations approach AI development in an era where data sovereignty is strategic infrastructure.
As AI becomes comparable to ports, power grids, and telecommunications networks in strategic importance, the ability to develop and deploy models using your own infrastructure, data, and workforce becomes a competitive necessity. Federated learning provides the technical foundation for this sovereignty while enabling the collaborative learning required for state-of-the-art model performance.
The question is no longer whether enterprises should consider federated learning, but how quickly they can implement it to remain competitive in the sovereign AI era. Organizations that master distributed, privacy-preserving model training will define the next decade of AI innovation.
Ready to implement federated learning within your infrastructure? Explore how sovereign AI architectures can unlock your distributed data assets while maintaining complete control over your AI capabilities.




















