

Here's what no one tells you about deploying LLMs in production: 57% of organizations have agents in production, yet 32% cite quality as their top barrier. The painful reality? Enterprises are losing an estimated $1.9 billion annually due to undetected LLM failures and quality issues in production.
The culprit isn't the models themselves. It's the catastrophic gap between how we evaluate LLMs and how they actually perform in enterprise environments.
Enterprise teams make a critical mistake: they select models based on leaderboard performance, then watch those same models fail spectacularly on real business tasks.
Models that dominate leaderboards often underperform in production. The disconnect isn't accidental. It stems from fundamental misalignments between academic testing and business requirements. When GPT-4 achieves 99% on MMLU but your financial services chatbot can't handle regulatory compliance scenarios, the benchmark told you nothing useful.
Consider what generic benchmarks actually measure. They test broad language understanding, common sense reasoning, and general knowledge recall. A financial services chatbot needs evaluation data covering regulatory compliance scenarios, product-specific terminology, and conversation patterns unique to that institution. Generic benchmarks can't capture these requirements.
The problem compounds when you realize that state-of-the-art systems now score above 90% on tests like MMLU, prompting platforms like Vellum AI to exclude saturated benchmarks from their leaderboards entirely. When every top model aces the same test, that test reveals nothing about which system will actually serve your specific use case.
Evaluation costs spiral in ways most teams never anticipate. You need three evaluation approaches, each with different economics.
Human annotation remains the gold standard but doesn't scale. While human evaluation costs $20-100 per hour, automated LLM evaluation can process the same volume for $0.03-15.00 per 1 million tokens. For an enterprise processing thousands of outputs daily, manual evaluation of 100,000 responses takes 50+ days.
LLM-as-a-judge offers radical cost reduction. The current iteration of AlpacaEval runs in less than three minutes, costs less than $109, and has a 0.98 Spearman correlation with human evaluation. Yet these judges exhibit systematic biases. Position bias creates 40% GPT-4 inconsistency, while verbosity bias inflates scores by roughly 15%.
Hybrid approaches balance economics with accuracy. Use LLM judges for initial filtering at $0.03-15.00 per million tokens, identifying obvious successes and failures while flagging top 5-10% of complex cases for human review. Apply intelligent sample selection where conflicting automated scores trigger human evaluation, reducing human evaluation needs by 80% while maintaining quality.
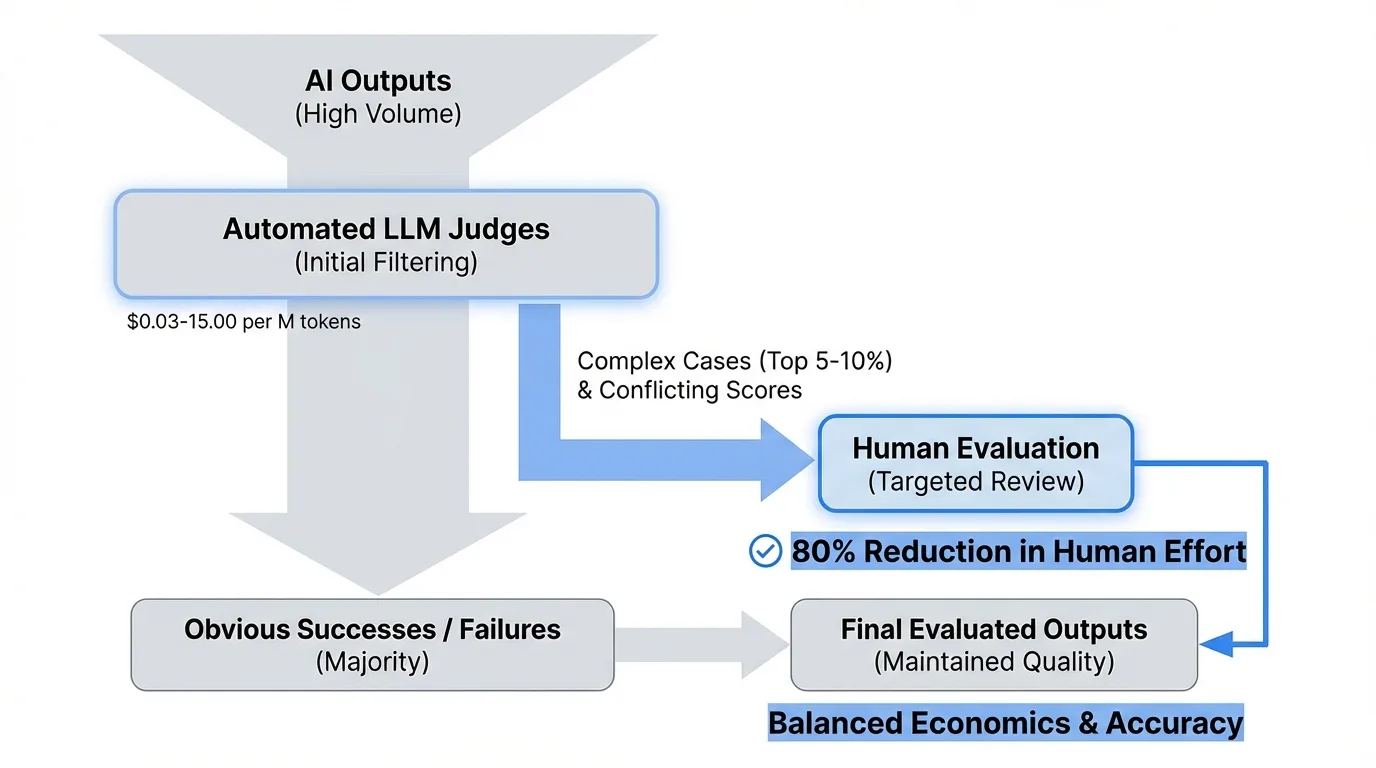
The hidden complexity: evaluation costs aren't just about running tests. They include building custom evaluation datasets, maintaining test infrastructure, and continuously updating benchmarks as your application evolves.
Traditional metrics like accuracy or BLEU scores fundamentally misunderstand what makes LLM outputs valuable in enterprise contexts.
Faithfulness: Is the output grounded in provided context, or is the model hallucinating? DoorDash implemented a multi-layered quality control approach with an LLM Guardrail and LLM Judge, achieving a 90% reduction in hallucinations and a 99% reduction in compliance issues. This matters more than fluency for any enterprise deployment.
Relevance: Does the response actually answer the user's question? LLMs excel at sounding helpful while drifting off-topic. Relevance checks matter more than style, particularly when users are trying to accomplish specific tasks.
Completeness: Did the model provide enough information for the user to take action? Incomplete responses create support escalations, exactly what your LLM deployment was meant to reduce.
Consistency: Does the model maintain the same tone, policies, and factual statements across similar queries? Inconsistency destroys user trust faster than occasional errors.
Compliance: LLMs may generate biased, offensive, or non-compliant language if guardrails fail. Enterprises should monitor outputs for sensitive terms, tone violations, or data leakage using pattern matchers or classifiers.
Domain accuracy: Generic language fluency means nothing if the model gets domain-specific facts wrong. A pharmaceutical company tried GPT-4 out-of-the-box, which achieved 66% accuracy. They then used a data development platform with GPT-4 to train a smaller model, increasing their results to 88% in just a few hours.
Safety and bias: Models trained on biased data perpetuate those biases. Google's hate-speech detection algorithm, Perspective, exhibited bias against African-American Vernacular English (AAVE), often misclassifying it as toxic due to insufficient representation in the training data.
These dimensions require multifaceted evaluation approaches that most enterprises struggle to implement systematically.
Evaluation isn't a one-time exercise. It's continuous infrastructure that needs to run at production scale.
Nearly 89% of respondents have implemented observability for their agents, outpacing evals adoption at 52%. This reveals a critical gap: teams monitor what's happening in production but lack systematic testing before deployment.
The infrastructure challenge breaks down into several components:
Monitoring LLMs in enterprise settings is fundamentally different from monitoring traditional machine learning models. LLMs are probabilistic, non-deterministic, and highly context-sensitive. Without proper observability, their behavior can silently drift, generate incorrect outputs, or introduce risk.
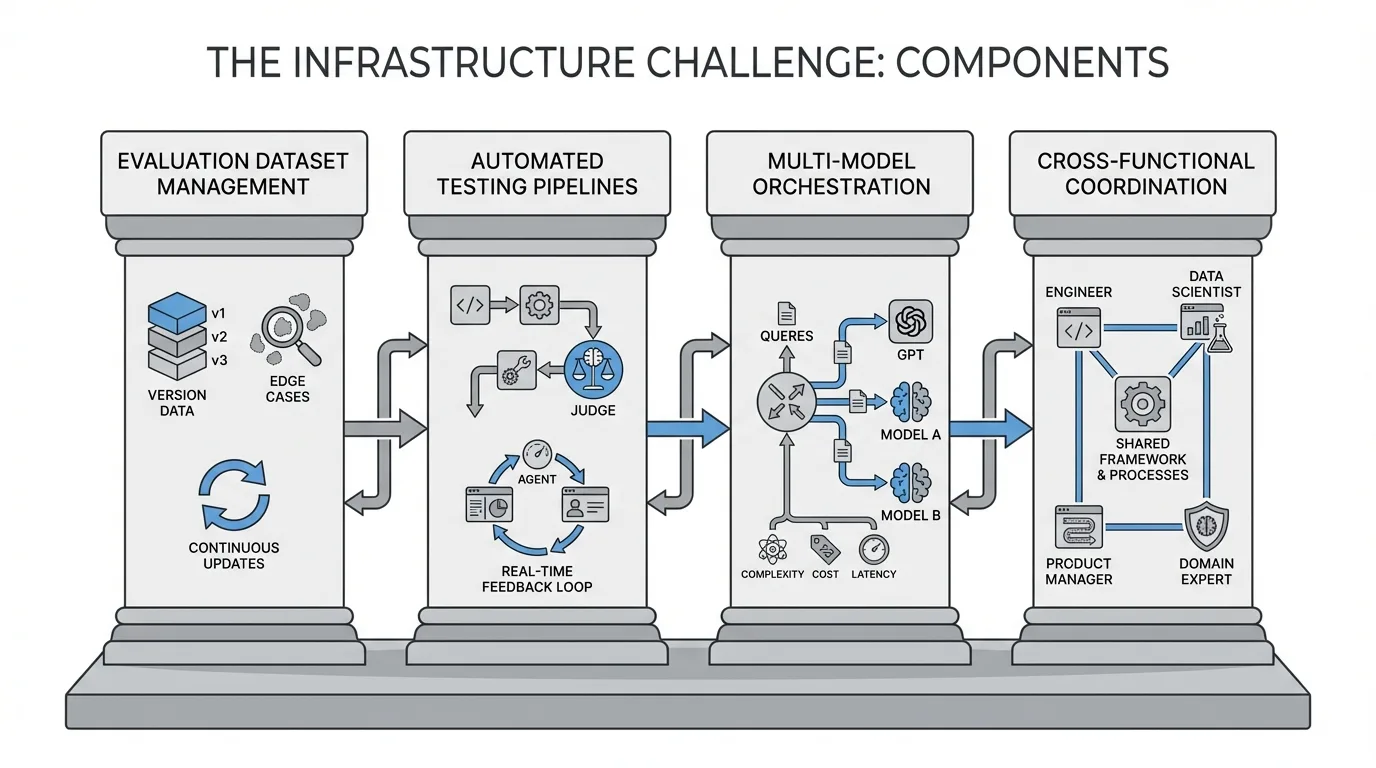
Successful enterprises follow distinct patterns that separate functional LLM deployments from expensive failures.
Start with offline evaluation before production deployment. Just over half of organizations (52.4%) report running offline evaluations on test sets, indicating that many teams see the importance of catching regressions and validating agent behavior before deployment. The teams that skip this step pay for it in production incidents.
Use layered evaluation with increasing sophistication. Start with simple programmatic checks for formatting, length, and content safety. Add automated LLM scoring across multiple quality dimensions. Reserve human review for edge cases and high-stakes decisions. This hybrid approach achieves 95%+ cost reduction while maintaining 90%+ of human evaluation quality.
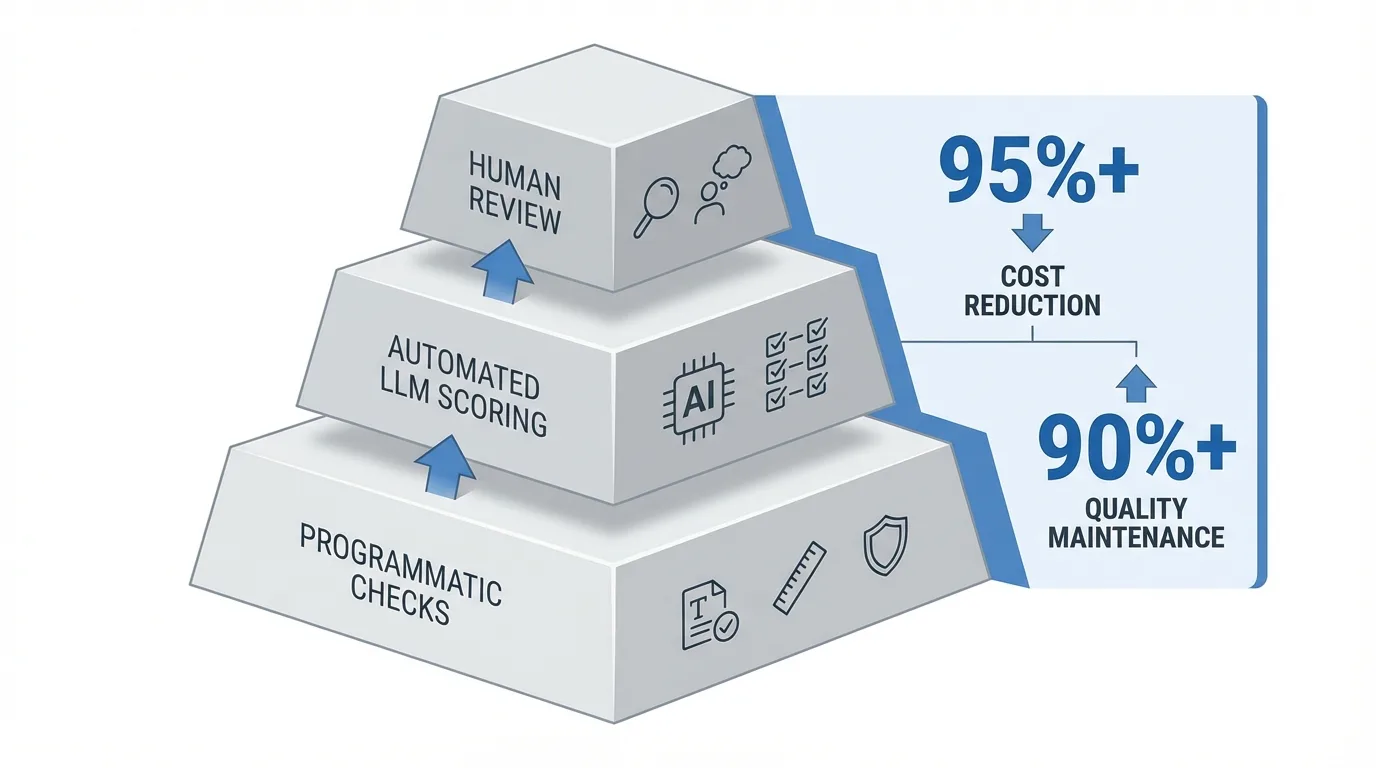
Build domain-specific evaluation datasets. This requires custom evaluation datasets that reflect actual user queries, edge cases specific to the business, and success criteria tied to operational metrics. A financial services chatbot needs evaluation data covering regulatory compliance scenarios, product-specific terminology, and conversation patterns unique to that institution. Generic benchmarks can't capture these requirements. Organizations can leverage approaches like extracting key insights from financial documents using AI to build these domain-specific test sets.
Implement continuous evaluation loops. User feedback is critical. Enterprises must capture corrections, dissatisfaction signals, and ratings. These signals feed into prompt refinement, RAG updates, and model fine-tuning.
Establish clear success metrics tied to business outcomes. For customer support applications, relevant metrics might include task completion rate, escalation reduction, response accuracy, safety violations per 100 interactions, and average handling time. None of these appear in standard benchmarks, but all directly impact ROI.
The gap between proof-of-concept and production-ready LLM systems comes down to evaluation infrastructure. Teams that build robust evaluation frameworks ship faster, experience fewer production failures, and achieve better business outcomes.
Effective evaluation requires three foundational elements:
Custom evaluation datasets aligned with business requirements. You can't evaluate what you haven't defined. Successful teams translate business requirements into measurable quality dimensions, then build test datasets that predict production performance.
Automated evaluation pipelines integrated into development workflows. Teams with great evaluations move up to 10 times faster than those relying on ad-hoc production monitoring. This acceleration translates directly to faster feature delivery and competitive advantage.
Hybrid human-AI evaluation at appropriate scale. Human evaluators remain the gold standard for establishing ground truth, particularly for nuanced quality dimensions that require contextual understanding. Human evaluators bring diverse perspectives but may introduce inconsistency through subjective interpretation or evaluator fatigue.
Shakudo addresses the evaluation infrastructure crisis by providing pre-integrated evaluation frameworks that deploy on enterprise infrastructure in days. Unlike cloud platforms where evaluation costs spiral unpredictably, Shakudo's data-sovereign architecture enables comprehensive evaluation suites—human annotation, automated testing, and LLM-as-a-judge—with full cost control and compliance.
Organizations using Shakudo rapidly implement custom evaluation pipelines that test domain-specific requirements, maintain data privacy for sensitive evaluation datasets, and scale testing infrastructure elastically without vendor lock-in. This accelerates the path from proof-of-concept to confident production deployment.
The enterprises succeeding with LLM deployments share a common characteristic: they treat evaluation as core infrastructure, not an afterthought. The highest-performing AI-driven organizations treat LLM evaluation as a continuous operational function, integral to their growth, strategy, and trustworthiness.
The cost of inadequate evaluation isn't just financial. It's delayed launches, eroded user trust, and competitive disadvantage as more agile competitors ship reliable AI experiences. A single high-profile AI failure can damage brand reputation and customer trust irreparably. Comprehensive evaluation acts as insurance against these catastrophic failures.
If your team is evaluating LLMs based primarily on benchmark scores, running limited pre-production testing, or lacking automated evaluation infrastructure, you're exposed to the same risks that have caused 95% of enterprise GenAI implementations to fail. As outlined in our guide to AI challenges and risks, understanding how to safely scale AI requires addressing these evaluation gaps systematically.
The solution isn't more sophisticated models. It's building evaluation infrastructure that bridges the gap between benchmark performance and business reality. Organizations that make this investment today will dominate their markets tomorrow, while those that don't will join the statistics of failed AI initiatives.
Ready to build production-grade LLM evaluation infrastructure? Contact Shakudo to learn how enterprises deploy comprehensive evaluation frameworks with full data sovereignty and cost control.




















