

The promise of open source AI is compelling: 89% of organizations that have adopted AI use open-source AI in some form for their infrastructure. Enterprises are rapidly adopting frameworks like TensorFlow, PyTorch, Kubeflow, and LangChain to build intelligent systems that avoid vendor lock-in and maintain data sovereignty. Yet beneath this adoption surge lies a stark operational reality. While these AI frameworks offer zero licensing fees and unprecedented flexibility, they introduce hidden complexity that can cripple deployment velocity and balloon infrastructure costs.
The fundamental challenge isn't choosing between open source and proprietary AI. It's orchestrating dozens of disconnected tools into production-ready systems while maintaining enterprise-grade security, compliance, and performance.
Modern AI infrastructure resembles a patchwork of specialized tools, each excellent in isolation but challenging to unify. Data scientists need TensorFlow or PyTorch for model training, MLflow for experiment tracking, Kubeflow for pipeline orchestration, LangChain for LLM applications, vector databases for retrieval, and monitoring tools for production systems. More than 68 percent of organizations implementing AI pipelines reported integration challenges due to the absence of unified MLOps platforms, leading to an average 27 percent rise in operational delays across ML cycles.
The problem compounds at scale. Each framework requires specific configurations, dependency management, security hardening, and infrastructure optimization. Many open-source platforms require strong DevOps or MLOps expertise to deploy and manage, and without the right engineering skills, setup can be time-consuming and error-prone. This fragmentation recreates the operational chaos that enterprises spent decades escaping: siloed tools, redundant integrations, and lack of coherent workflows.
Consider the typical path from experimentation to production. Data scientists develop models locally using PyTorch, track experiments in MLflow, containerize applications with Docker, deploy pipelines on Kubeflow, serve models through custom APIs, and monitor performance with separate observability tools. Each transition point introduces integration work, version conflicts, and potential failure modes.
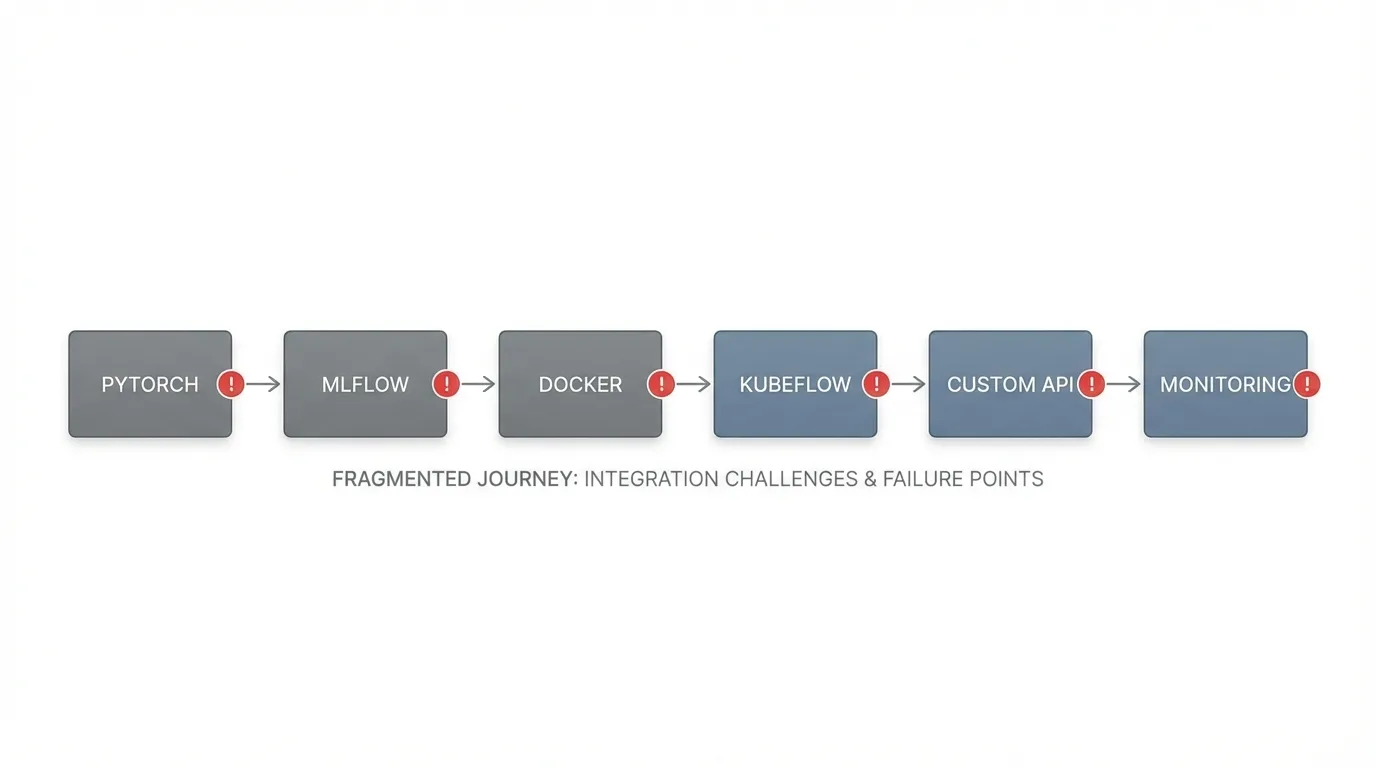
Open source AI frameworks eliminate licensing fees but introduce operational expenses that often exceed commercial alternatives. The hidden costs manifest across multiple dimensions:
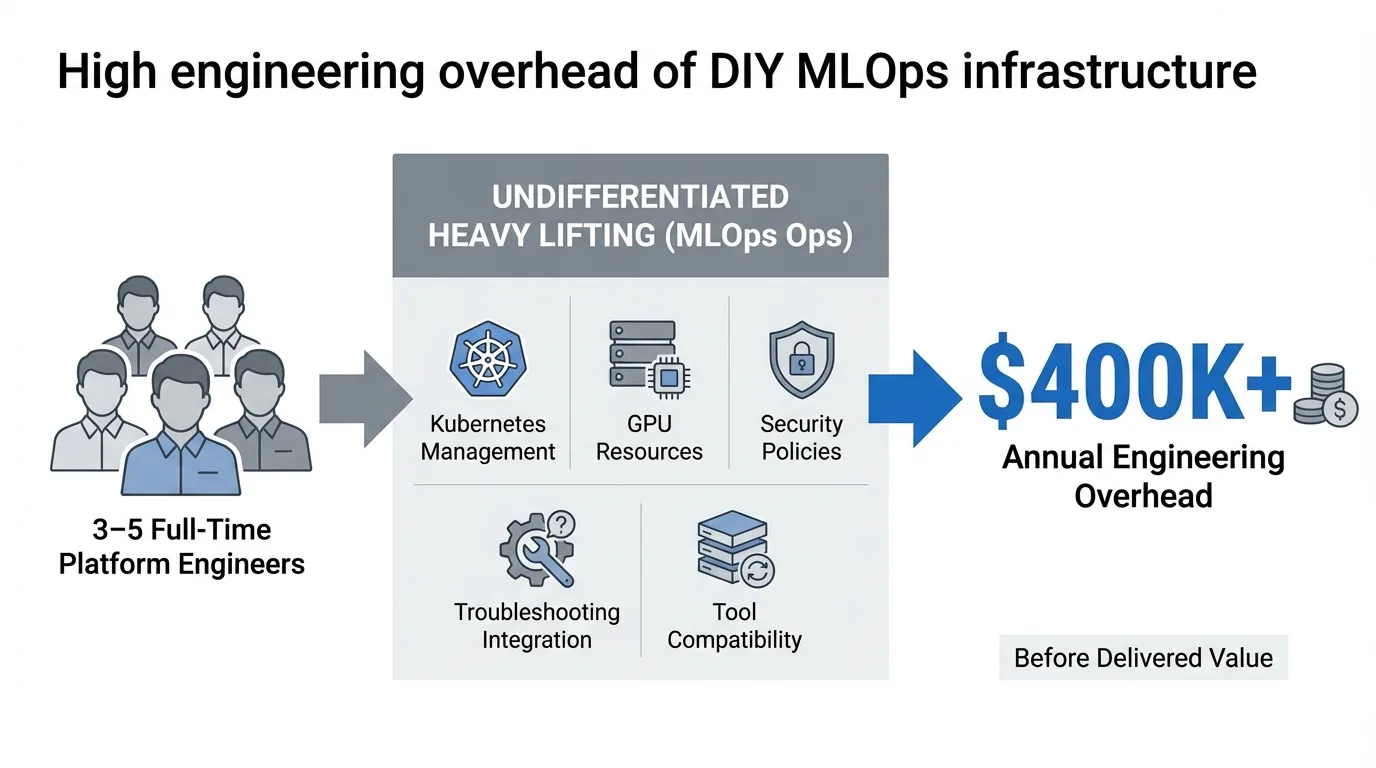
Engineering overhead: Building and maintaining production MLOps infrastructure requires dedicated platform engineering expertise. Organizations typically need 3-5 full-time engineers just to maintain baseline operations, translating to over $400,000 annually in engineering overhead before delivering any business value. These teams spend their time on undifferentiated heavy lifting: configuring Kubernetes clusters, managing GPU resources, implementing security policies, troubleshooting integration issues, and maintaining tool compatibility across updates.
Security hardening: Open source tools ship with minimal security configurations. Unlike commercial platforms, open-source solutions don't always provide 24/7 support or guaranteed SLAs, and most assistance comes from community forums or documentation, which can delay problem resolution. Enterprises must implement authentication, authorization, secrets management, network policies, vulnerability scanning, and compliance controls across each component.
Integration complexity: Achieving seamless AI workflow automation across fragmented toolsets complicates the implementation of reproducible AI pipelines and MLOps standardization, and integrating disparate systems for CI/CD for machine learning and automated data lineage remains complex and can increase initial setup costs by over 50%.
Deployment bottlenecks: Without unified orchestration, deployment cycles stretch from days to months. Implementing critical governance features like model drift monitoring, explainable AI integration, and regulatory audit trails requires significant engineering effort, with many firms reporting implementation timelines 40% longer than anticipated.
The competitive advantage in enterprise AI doesn't come from selecting the best individual frameworks. It emerges from orchestrating those frameworks into coherent, production-ready systems. 94% of organizations view process orchestration as essential for deploying AI effectively, with this orchestration layer connecting individual tools into coherent workflows.
Effective orchestration platforms provide several critical capabilities:
MLflow continues to be the most widely adopted open-source MLOps platform in 2025, while Kubeflow remains the go-to choice for organizations running ML workloads on Kubernetes, offering a scalable platform for training, serving, and orchestrating ML workflows. However, these tools require substantial operational expertise to deploy at enterprise scale, and common MLOps mistakes can cost enterprises millions if not properly addressed.
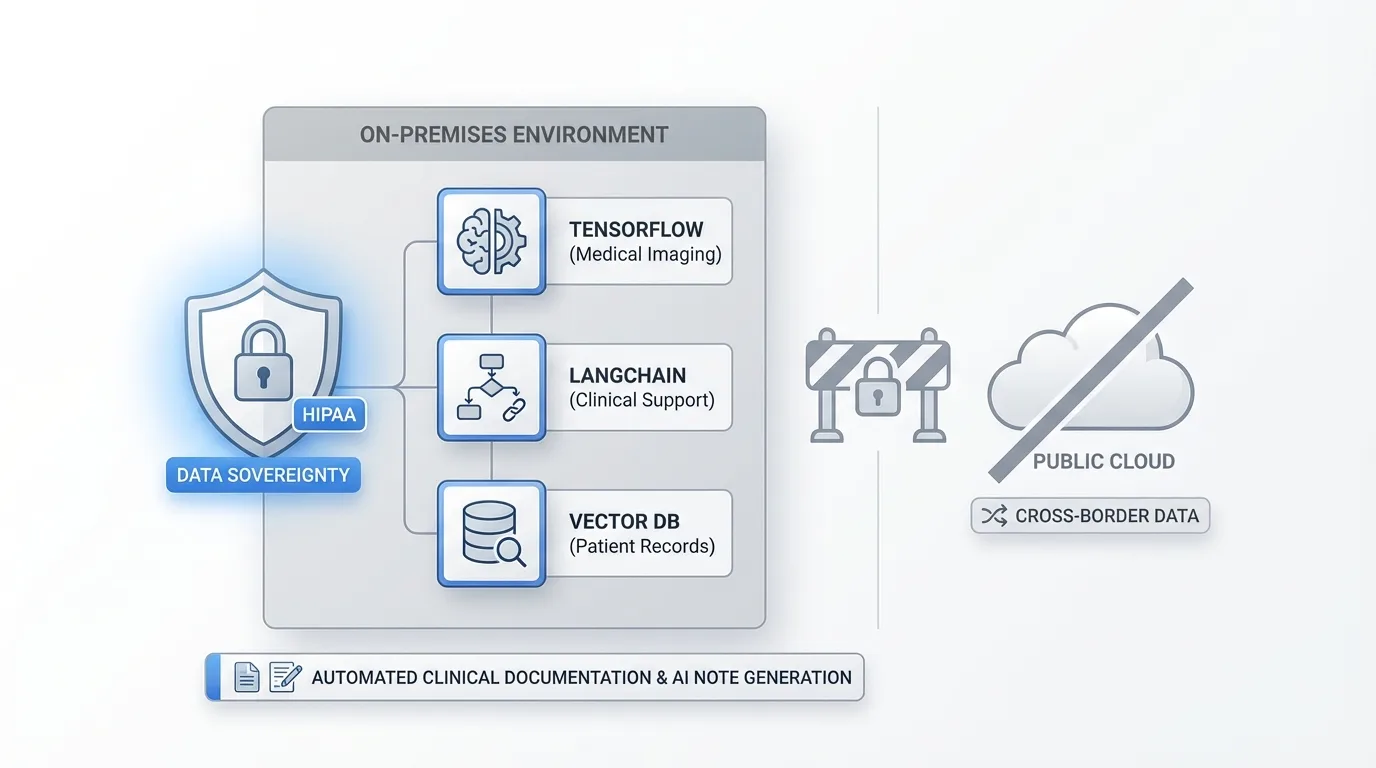
The orchestration challenge becomes particularly acute in regulated industries where data sovereignty and compliance requirements eliminate public cloud options.
Healthcare organizations need to orchestrate TensorFlow models for medical imaging, LangChain applications for clinical decision support, and vector databases for patient record retrieval while maintaining HIPAA compliance and on-premises deployment. Clinical trial data is highly sensitive and often cannot cross borders, making public cloud deployments infeasible, and hybrid models allow organizations to keep protected health information within sovereign environments while still taking advantage of modern processing power capabilities. Solutions like automated clinical documentation with AI note generation demonstrate how healthcare organizations can leverage orchestrated frameworks while maintaining compliance.
Financial services firms face similar constraints. They deploy PyTorch models for fraud detection, time-series forecasting with specialized frameworks, and LLM-powered customer service agents while meeting SOC 2, PCI DSS, and data residency requirements. 42% of enterprises need access to eight or more data sources to deploy AI agents successfully, with security concerns emerging as the top challenge across both leadership (53%) and practitioners (62%).
Government agencies require complete data sovereignty for national security applications. They orchestrate open source frameworks for intelligence analysis, threat detection, and citizen services while maintaining air-gapped deployments and strict access controls. Open models are capable options for teams that need cost control or air-gapped deployments.
Telecommunications providers leverage open source AI for network optimization, customer churn prediction, and service personalization. Data residency regulations require all AI processing to remain local, making open models and on-premises orchestration mandatory rather than optional.
Successfully orchestrating open source AI frameworks requires strategic decisions across multiple dimensions:
Architecture approach: The concerns over security, cost, and guidelines induce most firms to adopt architecture approaches that include cloud and on-premises data centers. Hybrid deployments provide flexibility to keep sensitive data on-premises while leveraging cloud resources for development and testing.
Platform vs. point solutions: Organizations face a build-versus-buy decision. Building custom orchestration platforms provides maximum flexibility but requires sustained engineering investment. MLOps stacks are getting crowded: landscape roundups show teams stitching together experiment tracking, orchestration, model registry, monitoring, and data tools — often 5+ components for one lifecycle. Managed orchestration platforms reduce operational overhead but require careful vendor evaluation. Understanding MLOps best practices every enterprise needs can help guide this critical decision.
Team structure and skills: Platforms like Google Vertex AI and Azure ML minimize technical barriers through visual interfaces, while Kubernetes-native solutions like Kubeflow demand DevOps expertise but provide superior scalability for technical teams with container orchestration experience. Organizations must align platform choices with team capabilities or invest in upskilling.
Security and compliance: Regulated industries require security controls embedded throughout the orchestration layer. This includes role-based access control, audit logging, model governance, data lineage tracking, and compliance reporting. These capabilities cannot be effectively retrofitted; they must be architectural from the start.
Cost optimization: Companies implementing proper MLOps report 40% cost reductions in ML lifecycle management and 97% improvements in model performance. Effective orchestration optimizes GPU utilization, implements model caching, and provides visibility into resource consumption across frameworks.
Shakudo addresses the orchestration challenge by providing pre-integrated, production-ready deployment of 200+ open source AI frameworks. Rather than spending months integrating TensorFlow, PyTorch, MLflow, Kubeflow, LangChain, and vector databases, enterprises can deploy complete MLOps stacks on-premises or in private cloud within days.
The platform maintains complete data sovereignty while delivering enterprise-grade security, compliance, and governance controls. This approach eliminates the typical requirement for dedicated platform engineering teams while preserving the flexibility and innovation velocity of open source frameworks. For regulated enterprises in healthcare, finance, and government, this means leveraging cutting-edge AI capabilities while meeting strict compliance requirements without the operational complexity that typically accompanies open source adoption.
The future of enterprise AI belongs to organizations that master orchestration, not just framework selection. The increasing complexity and computational scale of modern artificial intelligence models serves as a primary market driver, and the drive for MLOps lifecycle automation is a primary market catalyst, enabling enterprise-grade AI deployment in high-stakes AI applications.
Successful orchestration transforms fragmented open source tools into unified platforms that accelerate deployment, reduce operational costs, and maintain enterprise governance. Organizations that invest in robust orchestration platforms position themselves to leverage AI innovation velocity while avoiding the operational quicksand that traps competitors in perpetual infrastructure work.
The question isn't whether to adopt open source AI frameworks. It's whether your organization can orchestrate them effectively enough to capture value before operational complexity erodes the cost advantages that made open source attractive in the first place. The enterprises that solve orchestration will build sustainable AI operations. Those that don't will discover that "free" frameworks carry hidden costs that dwarf commercial alternatives.
Ready to accelerate your AI deployment? Explore how unified orchestration platforms can reduce your time-to-production from months to days while maintaining complete data sovereignty and enterprise-grade security.




















