
87% of data science projects never make it to production. Despite billions invested in AI talent and infrastructure, most enterprise machine learning initiatives stall between experimentation and deployment. As the global MLOps market explodes from $3.13 billion in 2025 to a projected $89.18 billion by 2035, organizations that master ML operations will capture competitive advantages while others watch their AI investments evaporate.
The statistics paint a sobering picture. Moving a model from lab to full-scale production often takes seven to twelve months, according to Cisco's AI Readiness Index 2025. This delay stems from predictable yet persistent challenges: poor data quality, siloed information systems, and chronic shortages of skilled AI talent.
The operational chaos intensifies as ML initiatives scale. Manual model deployment processes, lack of visibility into model performance post-deployment, and no systematic retraining or lifecycle management create cascading failures. Models drift undetected, compliance requirements go unmet, and engineering teams spend more time firefighting than innovating.
For regulated industries, the challenges multiply. 59% of organizations face compliance barriers while 63% struggle with high integration complexities across existing systems. Without proper audit trails, governance frameworks, and automated compliance checks, enterprises in healthcare, finance, and government cannot safely deploy AI systems that handle sensitive data.
Traditional software CI/CD doesn't translate directly to machine learning. ML pipelines must handle not just code, but data versioning, model artifacts, hyperparameters, and computational environments. Implement automated testing that validates model performance against baseline metrics before deployment, catching regressions before they reach production.
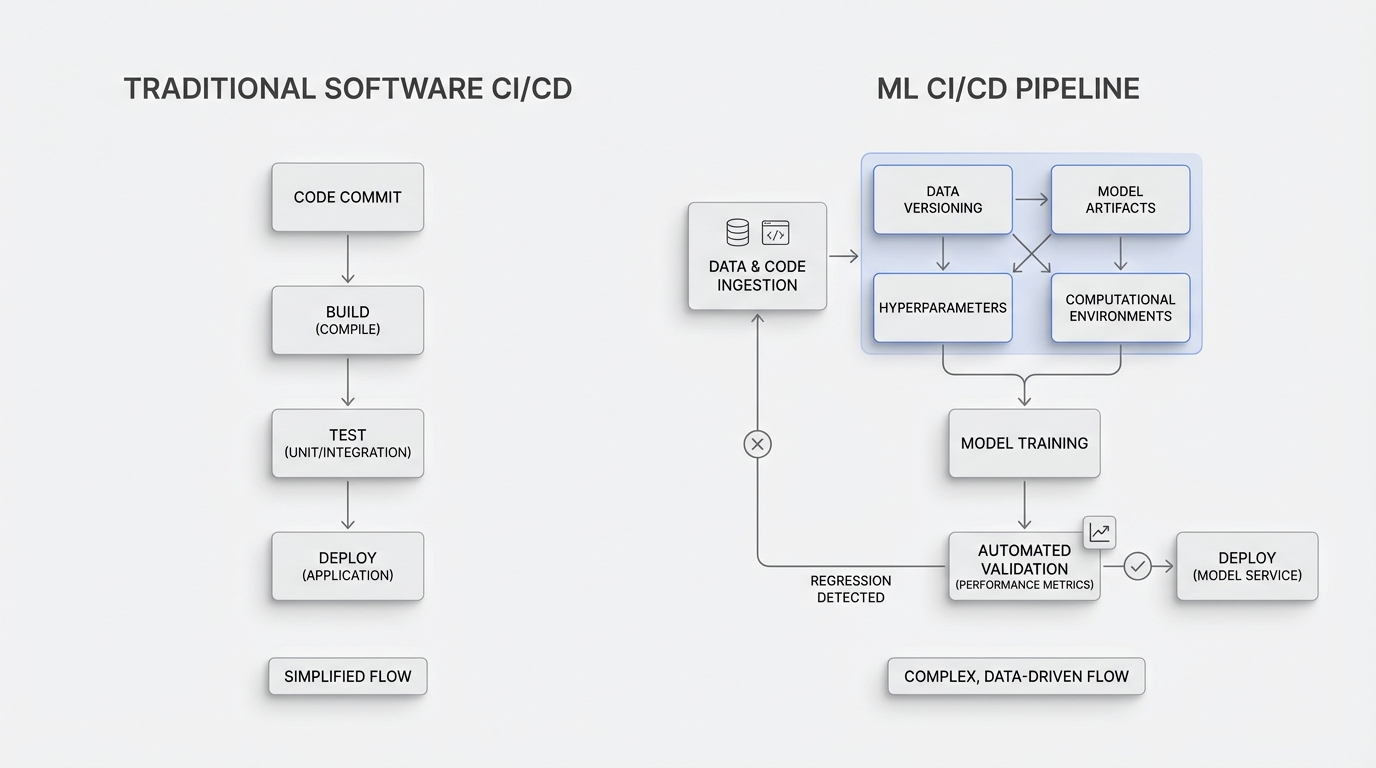
Every model iteration requires complete lineage tracking. This means versioning code, training data, feature engineering logic, hyperparameters, and dependencies. When a model fails in production, teams must reproduce the exact training conditions to debug issues. Without versioning, troubleshooting becomes archaeological guesswork.
Inconsistent feature computation between training and serving environments causes silent failures. A centralized feature store ensures feature definitions remain consistent, enables feature reuse across teams, and provides the low-latency access production systems require. This single source of truth eliminates a major category of deployment bugs.
Production monitoring extends beyond infrastructure metrics. Track data drift, concept drift, prediction distributions, and business KPIs. Set automated alerts for anomalies in input data characteristics or model behavior. Companies implementing comprehensive MLOps best practices report 60% faster model deployment and 40% reduction in production incidents, largely due to proactive monitoring.
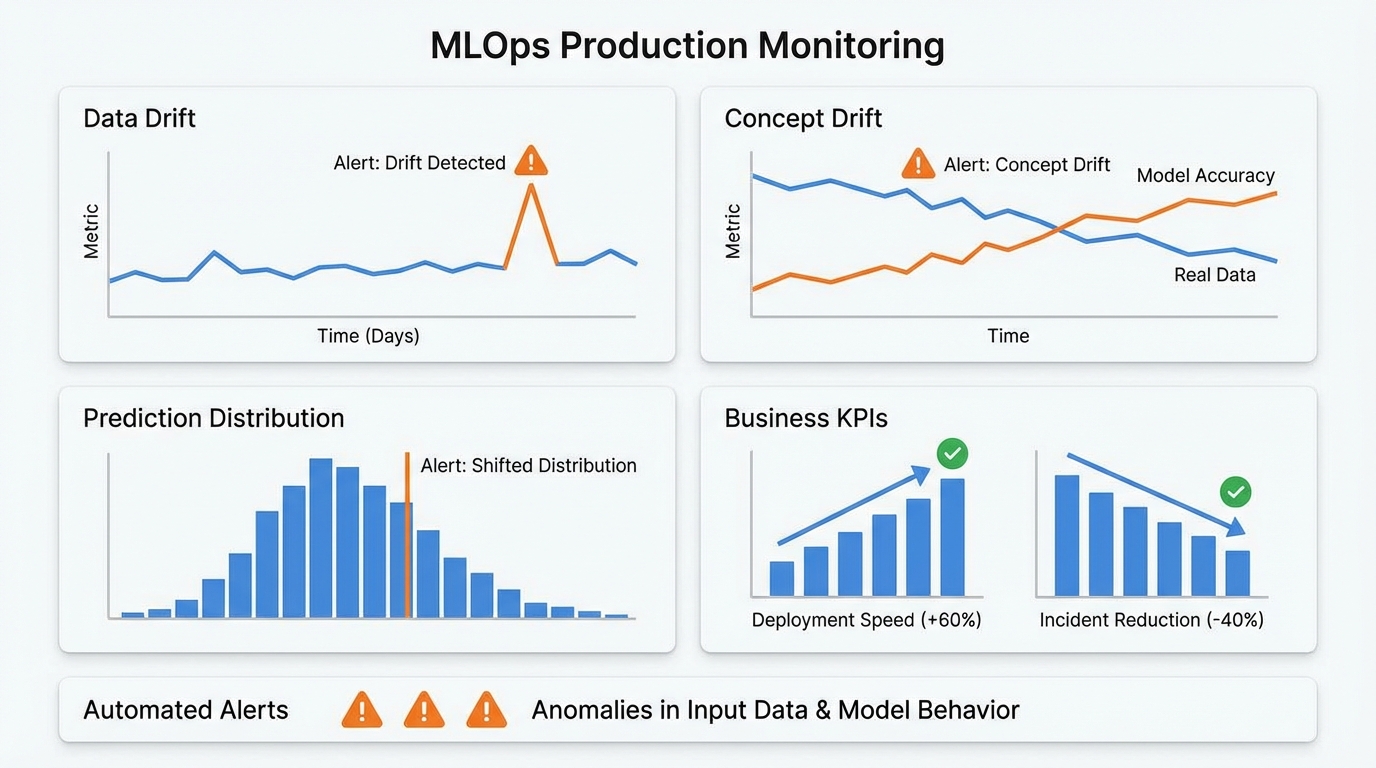
Model performance degrades over time as real-world patterns shift. Establish triggers based on performance thresholds, data drift metrics, or time intervals. Automated retraining pipelines should include data validation, training, evaluation, and conditional deployment based on improvement criteria.
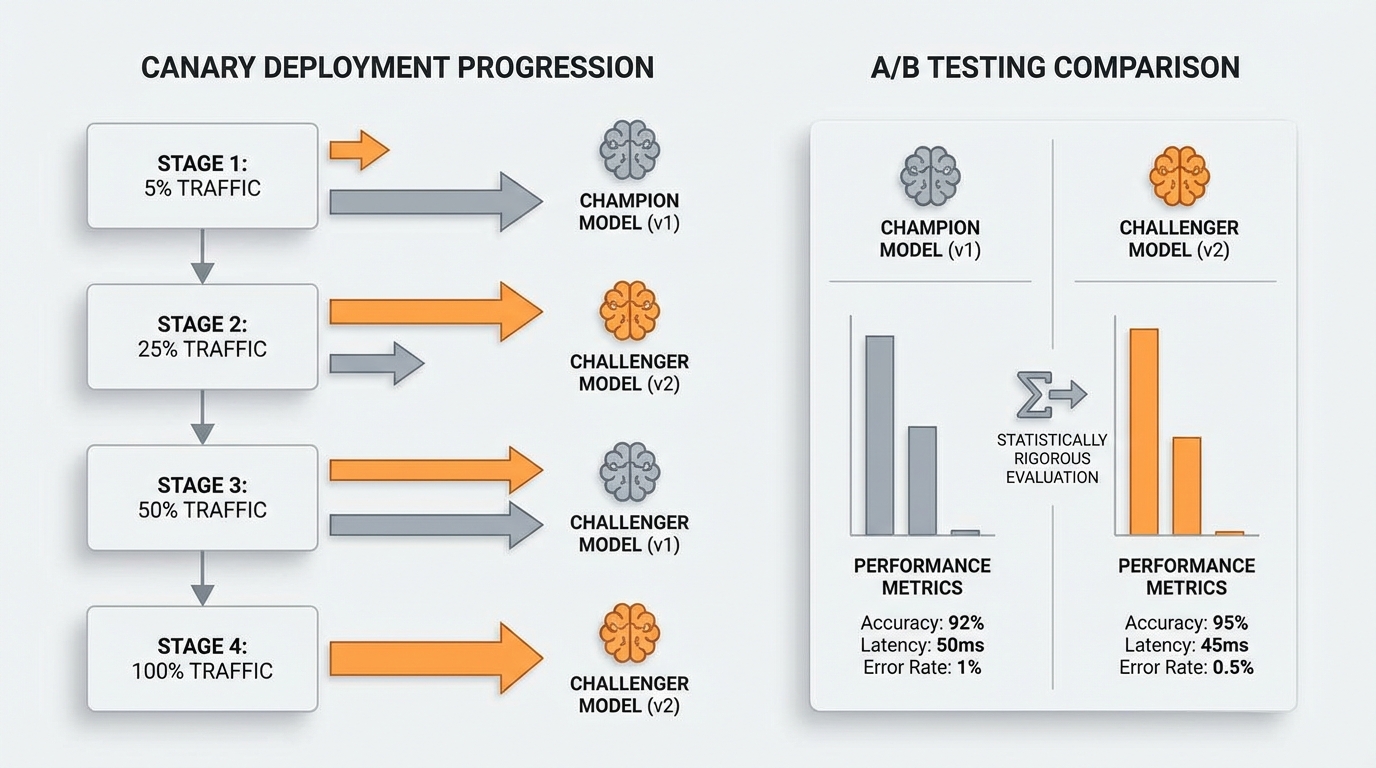
Never deploy models to full production simultaneously. Implement canary deployments that expose new models to small traffic percentages, monitor performance, then gradually increase traffic. Build infrastructure for A/B testing that compares new models against champions using statistically rigorous evaluation.
Regulated industries require complete transparency into model decisions. Implement approval workflows, document model limitations and intended use cases, and maintain immutable logs of all deployment actions. Every prediction in high-stakes applications should trace back to a specific model version with known characteristics.
Manual infrastructure configuration creates snowflake systems that cannot be reproduced. Define all ML infrastructure through code: training clusters, serving endpoints, monitoring dashboards, and data pipelines. This enables disaster recovery, multi-environment deployment, and eliminates configuration drift.
Bad data creates bad models. Implement schema validation, statistical checks, and anomaly detection on training data before model training begins. In production, validate input data against expected distributions and reject requests that fall outside acceptable ranges.
Black box models face adoption barriers in regulated industries and high-stakes decisions. Implement explainability techniques appropriate to your models: SHAP values, LIME, attention visualizations. Provide stakeholders with confidence scores and feature importance rankings they can understand.
ML workloads consume substantial compute resources. Implement autoscaling for training and inference, use spot instances for fault-tolerant workloads, and monitor resource utilization. Track cost per prediction and establish budgets with automated alerts for anomalies.
MLOps succeeds when data scientists, ML engineers, DevOps teams, and business stakeholders collaborate effectively. Establish shared responsibilities, common tools, and communication protocols. Create self-service platforms that let data scientists deploy models without requiring deep infrastructure expertise.
These practices deliver measurable outcomes. Organizations implementing comprehensive MLOps frameworks report dramatic improvements in deployment velocity, system reliability, and team productivity. The automation reduces manual toil, letting skilled practitioners focus on high-value model development rather than operational firefighting.
The competitive advantage compounds over time. While competitors struggle with seven-to-twelve month deployment cycles, organizations with mature MLOps practices iterate weekly or daily. This velocity enables rapid experimentation, faster response to market changes, and continuous improvement of AI-driven products.
Compliance becomes manageable rather than prohibitive. Automated audit trails, governance workflows, and monitoring satisfy regulatory requirements without creating bottlenecks. Enterprises can confidently deploy AI in regulated contexts, opening revenue opportunities that competitors cannot pursue.
Financial services firms use these practices to deploy fraud detection models that adapt to emerging attack patterns within hours rather than months. Complete audit trails satisfy regulators while A/B testing validates improvements before full deployment.
Healthcare organizations leverage MLOps to maintain diagnostic models that comply with HIPAA and FDA requirements. Automated monitoring detects when model performance degrades on new patient populations, triggering retraining before clinical accuracy suffers.
Retail companies implement recommendation systems that continuously optimize based on seasonal trends and inventory changes. Feature stores ensure promotional logic applies consistently across online and in-store experiences.
Start with assessment. Evaluate your current ML lifecycle: How long does deployment take? Do you have automated testing? Can you reproduce training runs? Can you explain model decisions to auditors?
Prioritize based on pain points. If compliance blocks deployment, focus on governance and audit trails. If models fail silently in production, implement monitoring first. If deployment takes months, automate CI/CD pipelines.
Adopt incrementally. 72% of enterprises are adopting automation tools, while 68% prioritize scalable model deployment in production environments. You don't need perfect MLOps on day one. Implement practices that address your most acute challenges, then expand systematically.
Invest in platforms over point solutions. Integrating dozens of specialized tools creates the complexity that 63% of organizations struggle with. Seek platforms that provide integrated MLOps capabilities with unified interfaces and consistent workflows.
Shakudo addresses the core challenge that derails most MLOps initiatives: integration complexity. Rather than assembling and maintaining dozens of open-source tools, Shakudo provides pre-integrated MLOps frameworks with automated CI/CD pipelines and enterprise-grade security. The platform deploys on-premises or in private clouds, ensuring regulated enterprises maintain complete control over sensitive training data while eliminating vendor lock-in concerns that complicate long-term strategy.
For organizations facing the seven-to-twelve month deployment timeline, Shakudo collapses this to days through standardized workflows and automation. Teams get production-ready infrastructure without building integration layers or managing tool compatibility.
The gap between ML experimentation and production operation separates successful AI initiatives from expensive failures. Over 85% of AI projects fail due to a lack of operational infrastructure. The technology exists to bridge this gap, but success requires deliberate implementation of MLOps practices that address the full model lifecycle.
Enterprises that invest in MLOps foundations today will capture the competitive advantages of AI while others struggle with deployment bottlenecks, compliance barriers, and operational chaos. The question isn't whether to implement MLOps, but how quickly you can transform experimental models into production systems delivering measurable business value.
Start by evaluating your current ML operations against these twelve practices. Identify gaps, prioritize improvements, and begin building the operational foundation your AI initiatives require. The market is moving rapidly, and deployment velocity increasingly determines who captures value from AI innovation.
87% of data science projects never make it to production. Despite billions invested in AI talent and infrastructure, most enterprise machine learning initiatives stall between experimentation and deployment. As the global MLOps market explodes from $3.13 billion in 2025 to a projected $89.18 billion by 2035, organizations that master ML operations will capture competitive advantages while others watch their AI investments evaporate.
The statistics paint a sobering picture. Moving a model from lab to full-scale production often takes seven to twelve months, according to Cisco's AI Readiness Index 2025. This delay stems from predictable yet persistent challenges: poor data quality, siloed information systems, and chronic shortages of skilled AI talent.
The operational chaos intensifies as ML initiatives scale. Manual model deployment processes, lack of visibility into model performance post-deployment, and no systematic retraining or lifecycle management create cascading failures. Models drift undetected, compliance requirements go unmet, and engineering teams spend more time firefighting than innovating.
For regulated industries, the challenges multiply. 59% of organizations face compliance barriers while 63% struggle with high integration complexities across existing systems. Without proper audit trails, governance frameworks, and automated compliance checks, enterprises in healthcare, finance, and government cannot safely deploy AI systems that handle sensitive data.
Traditional software CI/CD doesn't translate directly to machine learning. ML pipelines must handle not just code, but data versioning, model artifacts, hyperparameters, and computational environments. Implement automated testing that validates model performance against baseline metrics before deployment, catching regressions before they reach production.
Every model iteration requires complete lineage tracking. This means versioning code, training data, feature engineering logic, hyperparameters, and dependencies. When a model fails in production, teams must reproduce the exact training conditions to debug issues. Without versioning, troubleshooting becomes archaeological guesswork.
Inconsistent feature computation between training and serving environments causes silent failures. A centralized feature store ensures feature definitions remain consistent, enables feature reuse across teams, and provides the low-latency access production systems require. This single source of truth eliminates a major category of deployment bugs.
Production monitoring extends beyond infrastructure metrics. Track data drift, concept drift, prediction distributions, and business KPIs. Set automated alerts for anomalies in input data characteristics or model behavior. Companies implementing comprehensive MLOps best practices report 60% faster model deployment and 40% reduction in production incidents, largely due to proactive monitoring.
Model performance degrades over time as real-world patterns shift. Establish triggers based on performance thresholds, data drift metrics, or time intervals. Automated retraining pipelines should include data validation, training, evaluation, and conditional deployment based on improvement criteria.
Never deploy models to full production simultaneously. Implement canary deployments that expose new models to small traffic percentages, monitor performance, then gradually increase traffic. Build infrastructure for A/B testing that compares new models against champions using statistically rigorous evaluation.
Regulated industries require complete transparency into model decisions. Implement approval workflows, document model limitations and intended use cases, and maintain immutable logs of all deployment actions. Every prediction in high-stakes applications should trace back to a specific model version with known characteristics.
Manual infrastructure configuration creates snowflake systems that cannot be reproduced. Define all ML infrastructure through code: training clusters, serving endpoints, monitoring dashboards, and data pipelines. This enables disaster recovery, multi-environment deployment, and eliminates configuration drift.
Bad data creates bad models. Implement schema validation, statistical checks, and anomaly detection on training data before model training begins. In production, validate input data against expected distributions and reject requests that fall outside acceptable ranges.
Black box models face adoption barriers in regulated industries and high-stakes decisions. Implement explainability techniques appropriate to your models: SHAP values, LIME, attention visualizations. Provide stakeholders with confidence scores and feature importance rankings they can understand.
ML workloads consume substantial compute resources. Implement autoscaling for training and inference, use spot instances for fault-tolerant workloads, and monitor resource utilization. Track cost per prediction and establish budgets with automated alerts for anomalies.
MLOps succeeds when data scientists, ML engineers, DevOps teams, and business stakeholders collaborate effectively. Establish shared responsibilities, common tools, and communication protocols. Create self-service platforms that let data scientists deploy models without requiring deep infrastructure expertise.
These practices deliver measurable outcomes. Organizations implementing comprehensive MLOps frameworks report dramatic improvements in deployment velocity, system reliability, and team productivity. The automation reduces manual toil, letting skilled practitioners focus on high-value model development rather than operational firefighting.
The competitive advantage compounds over time. While competitors struggle with seven-to-twelve month deployment cycles, organizations with mature MLOps practices iterate weekly or daily. This velocity enables rapid experimentation, faster response to market changes, and continuous improvement of AI-driven products.
Compliance becomes manageable rather than prohibitive. Automated audit trails, governance workflows, and monitoring satisfy regulatory requirements without creating bottlenecks. Enterprises can confidently deploy AI in regulated contexts, opening revenue opportunities that competitors cannot pursue.
Financial services firms use these practices to deploy fraud detection models that adapt to emerging attack patterns within hours rather than months. Complete audit trails satisfy regulators while A/B testing validates improvements before full deployment.
Healthcare organizations leverage MLOps to maintain diagnostic models that comply with HIPAA and FDA requirements. Automated monitoring detects when model performance degrades on new patient populations, triggering retraining before clinical accuracy suffers.
Retail companies implement recommendation systems that continuously optimize based on seasonal trends and inventory changes. Feature stores ensure promotional logic applies consistently across online and in-store experiences.
Start with assessment. Evaluate your current ML lifecycle: How long does deployment take? Do you have automated testing? Can you reproduce training runs? Can you explain model decisions to auditors?
Prioritize based on pain points. If compliance blocks deployment, focus on governance and audit trails. If models fail silently in production, implement monitoring first. If deployment takes months, automate CI/CD pipelines.
Adopt incrementally. 72% of enterprises are adopting automation tools, while 68% prioritize scalable model deployment in production environments. You don't need perfect MLOps on day one. Implement practices that address your most acute challenges, then expand systematically.
Invest in platforms over point solutions. Integrating dozens of specialized tools creates the complexity that 63% of organizations struggle with. Seek platforms that provide integrated MLOps capabilities with unified interfaces and consistent workflows.
Shakudo addresses the core challenge that derails most MLOps initiatives: integration complexity. Rather than assembling and maintaining dozens of open-source tools, Shakudo provides pre-integrated MLOps frameworks with automated CI/CD pipelines and enterprise-grade security. The platform deploys on-premises or in private clouds, ensuring regulated enterprises maintain complete control over sensitive training data while eliminating vendor lock-in concerns that complicate long-term strategy.
For organizations facing the seven-to-twelve month deployment timeline, Shakudo collapses this to days through standardized workflows and automation. Teams get production-ready infrastructure without building integration layers or managing tool compatibility.
The gap between ML experimentation and production operation separates successful AI initiatives from expensive failures. Over 85% of AI projects fail due to a lack of operational infrastructure. The technology exists to bridge this gap, but success requires deliberate implementation of MLOps practices that address the full model lifecycle.
Enterprises that invest in MLOps foundations today will capture the competitive advantages of AI while others struggle with deployment bottlenecks, compliance barriers, and operational chaos. The question isn't whether to implement MLOps, but how quickly you can transform experimental models into production systems delivering measurable business value.
Start by evaluating your current ML operations against these twelve practices. Identify gaps, prioritize improvements, and begin building the operational foundation your AI initiatives require. The market is moving rapidly, and deployment velocity increasingly determines who captures value from AI innovation.
87% of data science projects never make it to production. Despite billions invested in AI talent and infrastructure, most enterprise machine learning initiatives stall between experimentation and deployment. As the global MLOps market explodes from $3.13 billion in 2025 to a projected $89.18 billion by 2035, organizations that master ML operations will capture competitive advantages while others watch their AI investments evaporate.
The statistics paint a sobering picture. Moving a model from lab to full-scale production often takes seven to twelve months, according to Cisco's AI Readiness Index 2025. This delay stems from predictable yet persistent challenges: poor data quality, siloed information systems, and chronic shortages of skilled AI talent.
The operational chaos intensifies as ML initiatives scale. Manual model deployment processes, lack of visibility into model performance post-deployment, and no systematic retraining or lifecycle management create cascading failures. Models drift undetected, compliance requirements go unmet, and engineering teams spend more time firefighting than innovating.
For regulated industries, the challenges multiply. 59% of organizations face compliance barriers while 63% struggle with high integration complexities across existing systems. Without proper audit trails, governance frameworks, and automated compliance checks, enterprises in healthcare, finance, and government cannot safely deploy AI systems that handle sensitive data.
Traditional software CI/CD doesn't translate directly to machine learning. ML pipelines must handle not just code, but data versioning, model artifacts, hyperparameters, and computational environments. Implement automated testing that validates model performance against baseline metrics before deployment, catching regressions before they reach production.
Every model iteration requires complete lineage tracking. This means versioning code, training data, feature engineering logic, hyperparameters, and dependencies. When a model fails in production, teams must reproduce the exact training conditions to debug issues. Without versioning, troubleshooting becomes archaeological guesswork.
Inconsistent feature computation between training and serving environments causes silent failures. A centralized feature store ensures feature definitions remain consistent, enables feature reuse across teams, and provides the low-latency access production systems require. This single source of truth eliminates a major category of deployment bugs.
Production monitoring extends beyond infrastructure metrics. Track data drift, concept drift, prediction distributions, and business KPIs. Set automated alerts for anomalies in input data characteristics or model behavior. Companies implementing comprehensive MLOps best practices report 60% faster model deployment and 40% reduction in production incidents, largely due to proactive monitoring.
Model performance degrades over time as real-world patterns shift. Establish triggers based on performance thresholds, data drift metrics, or time intervals. Automated retraining pipelines should include data validation, training, evaluation, and conditional deployment based on improvement criteria.
Never deploy models to full production simultaneously. Implement canary deployments that expose new models to small traffic percentages, monitor performance, then gradually increase traffic. Build infrastructure for A/B testing that compares new models against champions using statistically rigorous evaluation.
Regulated industries require complete transparency into model decisions. Implement approval workflows, document model limitations and intended use cases, and maintain immutable logs of all deployment actions. Every prediction in high-stakes applications should trace back to a specific model version with known characteristics.
Manual infrastructure configuration creates snowflake systems that cannot be reproduced. Define all ML infrastructure through code: training clusters, serving endpoints, monitoring dashboards, and data pipelines. This enables disaster recovery, multi-environment deployment, and eliminates configuration drift.
Bad data creates bad models. Implement schema validation, statistical checks, and anomaly detection on training data before model training begins. In production, validate input data against expected distributions and reject requests that fall outside acceptable ranges.
Black box models face adoption barriers in regulated industries and high-stakes decisions. Implement explainability techniques appropriate to your models: SHAP values, LIME, attention visualizations. Provide stakeholders with confidence scores and feature importance rankings they can understand.
ML workloads consume substantial compute resources. Implement autoscaling for training and inference, use spot instances for fault-tolerant workloads, and monitor resource utilization. Track cost per prediction and establish budgets with automated alerts for anomalies.
MLOps succeeds when data scientists, ML engineers, DevOps teams, and business stakeholders collaborate effectively. Establish shared responsibilities, common tools, and communication protocols. Create self-service platforms that let data scientists deploy models without requiring deep infrastructure expertise.
These practices deliver measurable outcomes. Organizations implementing comprehensive MLOps frameworks report dramatic improvements in deployment velocity, system reliability, and team productivity. The automation reduces manual toil, letting skilled practitioners focus on high-value model development rather than operational firefighting.
The competitive advantage compounds over time. While competitors struggle with seven-to-twelve month deployment cycles, organizations with mature MLOps practices iterate weekly or daily. This velocity enables rapid experimentation, faster response to market changes, and continuous improvement of AI-driven products.
Compliance becomes manageable rather than prohibitive. Automated audit trails, governance workflows, and monitoring satisfy regulatory requirements without creating bottlenecks. Enterprises can confidently deploy AI in regulated contexts, opening revenue opportunities that competitors cannot pursue.
Financial services firms use these practices to deploy fraud detection models that adapt to emerging attack patterns within hours rather than months. Complete audit trails satisfy regulators while A/B testing validates improvements before full deployment.
Healthcare organizations leverage MLOps to maintain diagnostic models that comply with HIPAA and FDA requirements. Automated monitoring detects when model performance degrades on new patient populations, triggering retraining before clinical accuracy suffers.
Retail companies implement recommendation systems that continuously optimize based on seasonal trends and inventory changes. Feature stores ensure promotional logic applies consistently across online and in-store experiences.
Start with assessment. Evaluate your current ML lifecycle: How long does deployment take? Do you have automated testing? Can you reproduce training runs? Can you explain model decisions to auditors?
Prioritize based on pain points. If compliance blocks deployment, focus on governance and audit trails. If models fail silently in production, implement monitoring first. If deployment takes months, automate CI/CD pipelines.
Adopt incrementally. 72% of enterprises are adopting automation tools, while 68% prioritize scalable model deployment in production environments. You don't need perfect MLOps on day one. Implement practices that address your most acute challenges, then expand systematically.
Invest in platforms over point solutions. Integrating dozens of specialized tools creates the complexity that 63% of organizations struggle with. Seek platforms that provide integrated MLOps capabilities with unified interfaces and consistent workflows.
Shakudo addresses the core challenge that derails most MLOps initiatives: integration complexity. Rather than assembling and maintaining dozens of open-source tools, Shakudo provides pre-integrated MLOps frameworks with automated CI/CD pipelines and enterprise-grade security. The platform deploys on-premises or in private clouds, ensuring regulated enterprises maintain complete control over sensitive training data while eliminating vendor lock-in concerns that complicate long-term strategy.
For organizations facing the seven-to-twelve month deployment timeline, Shakudo collapses this to days through standardized workflows and automation. Teams get production-ready infrastructure without building integration layers or managing tool compatibility.
The gap between ML experimentation and production operation separates successful AI initiatives from expensive failures. Over 85% of AI projects fail due to a lack of operational infrastructure. The technology exists to bridge this gap, but success requires deliberate implementation of MLOps practices that address the full model lifecycle.
Enterprises that invest in MLOps foundations today will capture the competitive advantages of AI while others struggle with deployment bottlenecks, compliance barriers, and operational chaos. The question isn't whether to implement MLOps, but how quickly you can transform experimental models into production systems delivering measurable business value.
Start by evaluating your current ML operations against these twelve practices. Identify gaps, prioritize improvements, and begin building the operational foundation your AI initiatives require. The market is moving rapidly, and deployment velocity increasingly determines who captures value from AI innovation.




%20(1).avif)



