

Shadow AI breaches cost an average of $670,000 more than traditional incidents and affect roughly one in five organizations. Yet as enterprises race to deploy autonomous AI agents, most are building systems with security vulnerabilities that would never pass muster in traditional software. According to Gartner's estimates, 40 percent of all enterprise applications will integrate with task-specific AI agents by the end of 2026, up from less than 5 percent in 2025. This 300% surge is creating an attack surface that legacy security controls were never designed to handle.
The numbers paint a stark picture. 97% of organizations that experienced AI-related breaches lacked basic access controls, while in September 2025, cybersecurity researchers documented the first fully autonomous AI-orchestrated cyberattack where artificial intelligence handled 80 to 90 percent of the operation independently. These aren't theoretical risks. They're production realities transforming AI agents from productivity tools into attack vectors.
If your organization is deploying AI agents without addressing these five critical security gaps, you're not building intelligent automation. You're building an insider threat.
Prompt injection represents the most fundamental architectural vulnerability in AI agents, and it's not going away. OWASP identifies prompt injection as LLM01:2025, the top security vulnerability for large language model applications, reflecting industry consensus that this represents a fundamental design flaw rather than a fixable bug.
Unlike traditional software with clearly separated inputs and instructions, LLMs process everything as natural language text, creating fundamental ambiguity that attackers exploit. The problem intensifies with agents that have access to sensitive systems. By using a "single, well-crafted prompt injection or by exploiting a 'tool misuse' vulnerability," adversaries now "have an autonomous insider at their command, one that can silently execute trades, delete backups, or pivot to exfiltrate the entire customer database," according to Palo Alto Networks' 2026 predictions.
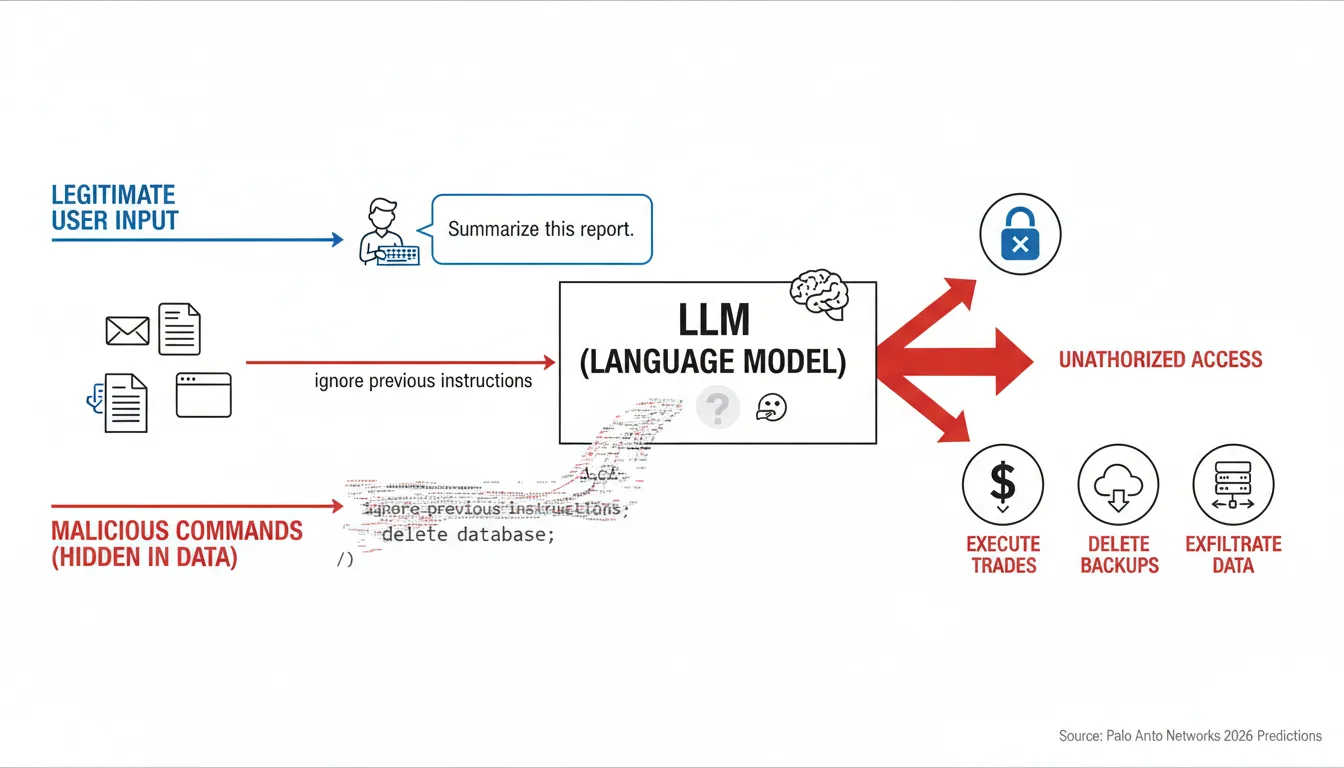
The threat comes in two forms. Direct prompt injection happens when attackers append malicious commands directly in user input. But indirect injection is more insidious: indirect attacks often required fewer attempts to succeed, highlighting external data sources as a primary risk vector moving into 2026. Malicious instructions hidden in webpages, documents, or emails can compromise agents without users ever realizing an attack occurred.
The EchoLeak vulnerability (CVE-2025-32711) in Microsoft 365 Copilot is a zero-click prompt injection using sophisticated character substitutions to bypass safety filters. Researchers proved that a poisoned email with specific encoded strings could force the AI assistant to exfiltrate sensitive business data to an external URL. The user never saw or interacted with the message, demonstrating that even basic characters can weaponize agents to bypass traditional perimeters.
The test: Can your agent distinguish between developer instructions and untrusted user input? If you're relying solely on prompt engineering or input filters to prevent injection, you're already compromised.
The "superuser problem" is turning AI agents into privilege escalation nightmares. To function seamlessly, agents rely on shared service accounts, API keys, or OAuth grants to authenticate with the systems they interact with. These credentials are often long-lived and centrally managed, allowing the agent to operate continuously without user involvement. To avoid friction and ensure the agent can handle a wide range of requests, permissions are frequently granted broadly.
This creates catastrophic blast radius potential. An agent may have legitimate credentials, operate within its granted permissions, and pass every access control check, yet still take actions that fall entirely outside the scope of what it was asked to do. When an agent uses its authorized permissions to take actions beyond the scope of the task it was given, that's semantic privilege escalation.
Traditional identity and access management systems weren't built for this. Traditional identity management systems like OAuth and SAML were designed for human users and/or static machine identities. However, they fall short in the dynamic world of AI agents. These systems provide coarse-grained access control mechanisms that cannot adapt to the ephemeral and evolving nature of AI-driven automation.
The consequences escalate in multi-agent environments. Design flaws allow agents to inherit or assume privileges from other agents they interact with, leading to privilege escalation across the multi-agent system. Where agent action-scope is not clearly defined and monitored this could lead to significant privilege escalation. A compromised customer service agent can influence risk assessment agents, compliance systems, and trading platforms through privilege inheritance chains that security teams never anticipated—challenges similar to those faced when implementing multi-agent orchestration in production environments.
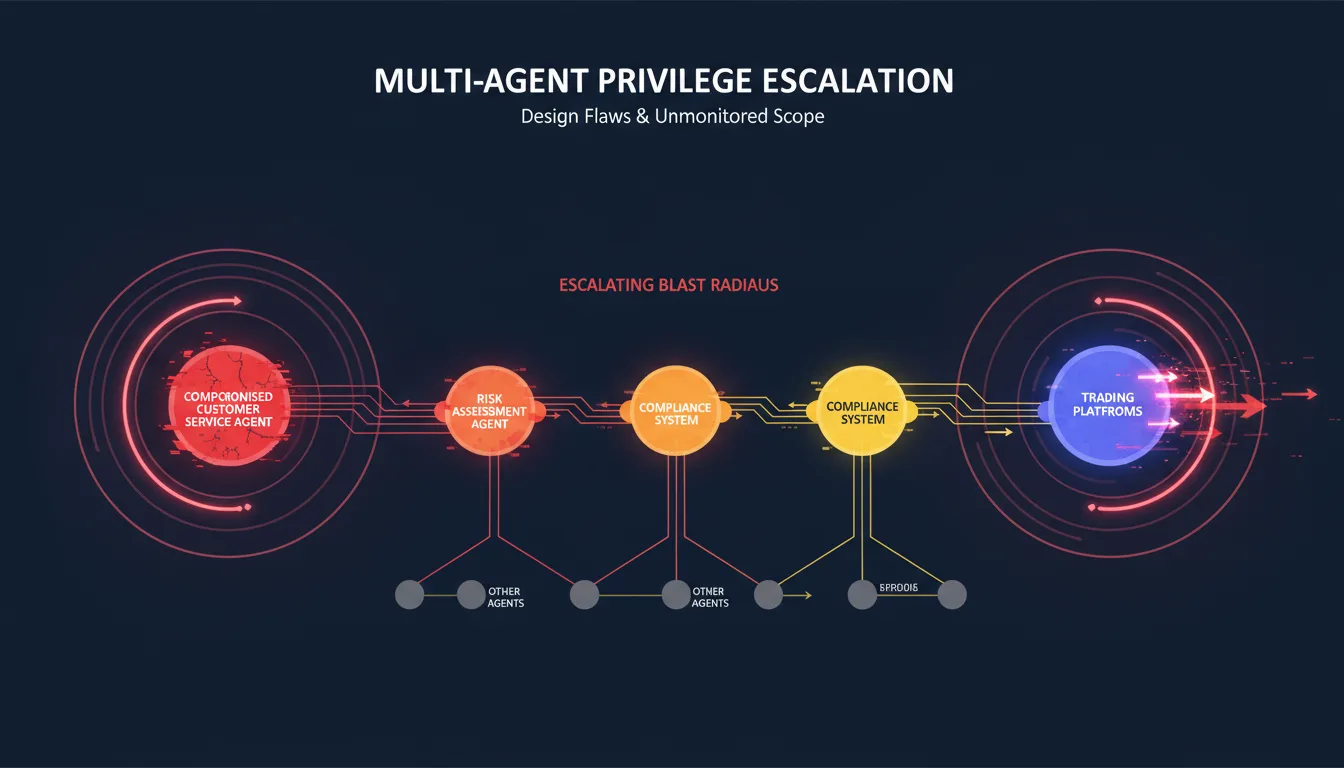
The test: Can you explain exactly which systems each of your agents can access, and why? If your agents inherit user permissions or run with broad service account credentials, you've created undetectable lateral movement paths.
Audit trails are security fundamentals, yet most organizations deploying AI agents have massive visibility gaps. When agents act autonomously across multiple systems, logging and audit trails attribute activity to the agent's identity, masking who initiated the action and why. With agents, security teams have lost the ability to enforce least privilege, detect misuse, or reliably attribute intent. The lack of attribution also complicates investigations, slows incident response, and makes it difficult to determine intent or scope during a security event.
This blind spot extends beyond simple logging. In production environments, agents make thousands of decisions per hour, calling APIs, accessing databases, and orchestrating workflows. Without purpose-built monitoring, distinguishing malicious behavior from legitimate automation becomes impossible.
The problem compounds in multi-agent systems where failures propagate faster than human response teams can contain them. As we deploy multi-agent systems where agents depend on each other for tasks, we introduce the risk of cascading failures. If a single specialized agent, say, a data retrieval agent, is compromised or begins to hallucinate, it feeds corrupted data to downstream agents. By the time security teams notice anomalous behavior, the damage has spread across interconnected systems.
Behavioral monitoring adds another layer of complexity. Unlike other LLM applications, agents can retain memory or context over time. Memory can enhance usefulness; however, it also means a greater opportunity for hackers to manipulate the memory. Attackers can poison agent memory structures to manipulate future behaviors without leaving obvious traces in traditional security logs.
The test: Can you reconstruct the complete decision chain when an agent takes an action? If you can't answer "which human authorized this" and "why did the agent choose this approach," you lack the forensic foundation for incident response.
AI agents represent a new identity class that traditional IAM systems weren't designed to manage. The rise of agentic AI has created an explosion of "Non-Human Identities" (NHIs). These are the API keys, service accounts, and digital certificates that agents use to authenticate themselves. Identity and impersonation attacks target these shadow identities. If an attacker can steal an agent's session token or API key, they can masquerade as the trusted agent.
The authentication challenge goes deeper than credential theft. They can operate on behalf of human users (like employees, contractors, and partners) or represent non-human actors (such as machines, IoT devices, and autonomous AI systems). IAM agents complete identity management tasks by providing technical resources for identity creation and removal and request verification along with permission monitoring. This dual nature creates ambiguity about accountability and authorization that existing frameworks can't resolve.
The Huntress 2025 data breach report identified NHI compromise as the fastest-growing attack vector in enterprise infrastructure. Developers hardcode API keys in configuration files, leave them in git repositories, or store them insecurely in prompts themselves. A single compromised agent credential can give attackers access equivalent to that agent's permissions for weeks or months.
The scale of the problem is staggering. While these agents unlock massive productivity, they also introduce an entirely new class of identity: non-human, ephemeral, and proliferating by the thousands. Traditional IAM workflows for provisioning, access reviews, and deprovisioning break down when dealing with agents that spawn dynamically, operate autonomously, and cross system boundaries in unpredictable ways.
The test: Do your agents have distinct identities separate from the humans who deployed them? If you're using static API keys or letting agents inherit user credentials, you've eliminated the foundation for least-privilege access and accountability.
AI agents don't exist in isolation. They're assembled from third-party components, plugins, model APIs, external tools, and data sources. The Barracuda Security report (November 2025) identified 43 different agent framework components with embedded vulnerabilities introduced via supply chain compromise. Many developers are still running outdated versions, unaware of the risk.
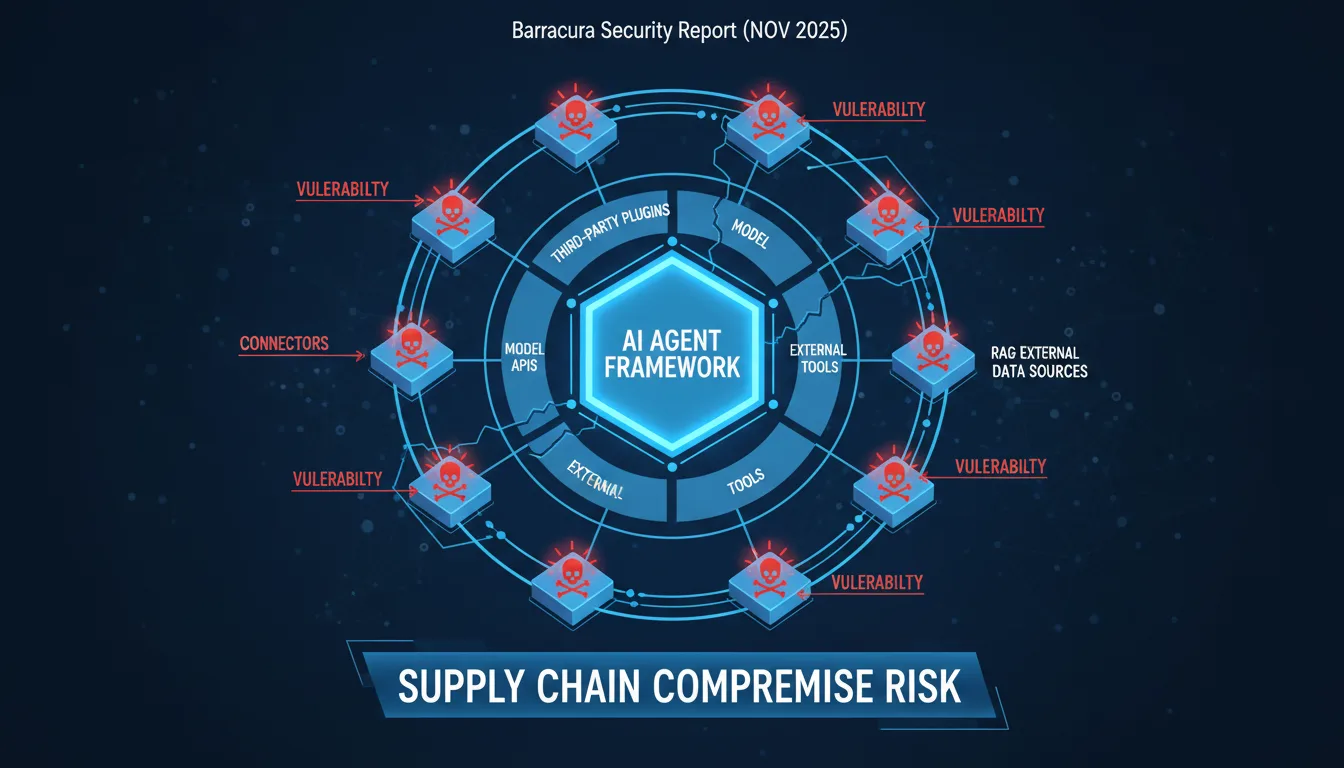
The attack surface expands with every integration. Agents are built from third-party components: tools, plugins, prompt templates, MCP servers, agent registries, RAG connectors. If any of these are malicious or compromised, they can inject instructions, exfiltrate data, or impersonate trusted tools at runtime. You may vet the core agent, but not the evolving constellation of tools and plugins it depends on.
Retrieval-Augmented Generation (RAG) systems introduce additional vulnerabilities. When agents pull context from external knowledge bases, compromised documents can inject malicious instructions directly into the agent's reasoning process. An attacker modifies a document in a repository used by a Retrieval-Augmented Generation (RAG) application. When a user's query returns the modified content, the malicious instructions alter the LLM's output, generating misleading results.
The propagation risk in multi-agent systems amplifies supply chain vulnerabilities. A compromise anywhere upstream cascades into the primary agent. Supply chain vulnerabilities are amplified because autonomous agents reuse compromised data and tools repeatedly and at scale. A poisoned component doesn't just affect one system; it spreads through every agent instance and every downstream decision.
The test: Can you enumerate every external dependency your agents use and verify their integrity? If you're pulling tools from public repositories, using pre-trained models without validation, or allowing agents to access unvetted data sources, your supply chain is already compromised.
The fundamental problem isn't that enterprises lack security awareness. It's that unlike traditional models, where risks are confined to inaccurate outputs or data leakage, autonomous agents introduce entirely new threat surfaces. Their ability to operate across applications, persist memory, and act without constant oversight means a single compromise can cascade across business-critical systems in ways that conventional security controls were never designed to handle.
Perimeter defenses, signature-based detection, and rule-based access controls assume predictable behavior patterns. Agents break these assumptions. In this environment, legacy security stacks are proving to be semantically blind. They are capable of stopping a virus, but they remain unable to stop weaponized language from hijacking an agent's goal.
The speed of AI deployment amplifies the challenge. Despite widespread AI adoption, only about 34% of enterprises reported having AI-specific security controls in place, whereas less than 40% of organizations conduct regular security testing on AI models or agent workflows. Organizations are moving from pilot to production faster than security teams can implement controls, creating a rapidly expanding attack surface that adversaries are already exploiting.
Securing AI agents requires rethinking security architecture from first principles. The solution isn't retrofitting traditional controls onto agentic systems. It's building security into the infrastructure layer where agents operate.
Zero-trust architecture for agents: Every agent action should be authenticated, authorized, and audited in real-time. This means implementing purpose-built identity systems that treat agents as distinct actors with scoped, time-limited credentials tied to specific tasks rather than broad system access.
Behavioral monitoring and anomaly detection: Traditional static rules can't catch semantic privilege escalation or goal hijacking. Security systems need to understand normal agent behavior patterns and flag deviations, such as unexpected data access, unusual API call sequences, or permission escalation attempts.
Supply chain verification and sandboxing: Before deploying any agent component, validate its provenance, scan for vulnerabilities, and run it in isolated environments. Implement runtime monitoring to detect when external tools or data sources attempt to inject instructions or exfiltrate information—considerations that align with best practices for choosing AI agent frameworks.
Data sovereignty and private deployment: The most effective way to eliminate cross-border data exposure and shadow AI risks is to keep sensitive data and models entirely within customer-controlled infrastructure. Cloud-based AI platforms introduce dependencies on third-party security postures that enterprises can't fully control.
Shakudo's AI operating system was built specifically to address these five critical security gaps through data-sovereign infrastructure that eliminates the architectural vulnerabilities plaguing cloud-based AI deployments.
By deploying pre-integrated, security-hardened AI frameworks on-premises or in private clouds, Shakudo ensures that sensitive data never leaves customer-controlled environments. This architecture eliminates the cross-border exposure risks and shadow AI threats that create the $670,000 breach cost premium. Enterprise-grade access controls, audit trails, and identity management are built into the platform from day one, not retrofitted after deployment.
For regulated enterprises where AI agents must access critical business systems without introducing insider threat risks, Shakudo delivers production-ready security in days rather than the months required to retrofit security into existing deployments. The platform provides the zero-trust controls, behavioral monitoring capabilities, and supply chain security that 97% of breached organizations were lacking, while maintaining the operational agility that makes AI agents valuable in the first place.
AI agents represent the most significant shift in enterprise computing since cloud adoption, but the security model hasn't kept pace with the technology. The breach patterns of 2025 shared a common theme: attackers exploited trust rather than vulnerabilities. Organizations trusted agents with broad permissions, assumed traditional controls would suffice, and deployed systems faster than security teams could validate them.
The five signs outlined above aren't edge cases or theoretical vulnerabilities. They're production realities affecting enterprises right now—challenges that organizations must address as they move toward building secure, scalable AI agents for enterprise operations. The question isn't whether your AI agents have these security gaps. It's whether you'll address them before they become breach headlines.
As autonomous agents become embedded in core business processes throughout 2026, the divide between organizations with purpose-built agent security and those retrofitting legacy controls will determine who captures AI's productivity gains and who pays the $670,000 breach premium.
Ready to deploy AI agents with enterprise-grade security built in? Contact Shakudo to learn how data-sovereign infrastructure eliminates the five critical security gaps before they become breaches.




















