

When generative AI first became popular, many companies looked for a single, powerful "master model" that could handle every task. However, this "one-model-fits-all" approach doesn't work for building serious, enterprise-level applications. The reality for today's technology leaders is a complex and growing ecosystem, not a single solution. A modern AI setup includes multiple large language models (LLMs)—from proprietary APIs and fine-tuned open-source versions to specialized in-house models—along with a wide range of data sources like vector databases, SQL databases, and external APIs.
Moving from a single model to a flexible, multi-component AI system is a strategic necessity. It's driven by the need to balance several competing factors: the cost of running models, the speed of responses for users, the quality and accuracy of the output, and the specific knowledge required for valuable tasks. A single, general-purpose model is rarely the most efficient choice for every query. Simple questions don't justify the cost of a premium model, while complex reasoning requires more power than a lightweight model can offer.
To make this complex web of specialized parts work together, you need a smart orchestration and routing layer. This layer acts as the central nervous system for your AI stack. It intelligently analyzes incoming user queries and directs them to the right combination of models, data sources, and tools to produce the best possible response. This isn't just a technical tool for managing traffic; it's a strategic control center for building AI capabilities that are efficient, scalable, and give you a competitive edge.
For technology leaders, designing this system raises critical questions. How do you prevent the runaway costs that come from using expensive models for every query? How do you ensure the fast performance needed for real-time applications? How can you securely connect user queries to sensitive company data without exposing it? And most importantly, how do you build a flexible system that avoids getting locked into a single vendor's ecosystem? The answers lie in how you design and manage your intelligent routing layer.
Moving from strategy to implementation requires understanding the main architectural patterns for an intelligent routing layer. To route AI model requests across multiple backends efficiently, you need a system that can intelligently analyze incoming queries and direct them to the most suitable model, data source, or tool. This is not just about load balancing; it's about making a strategic decision for every single request to optimize for factors like cost, speed, and accuracy.
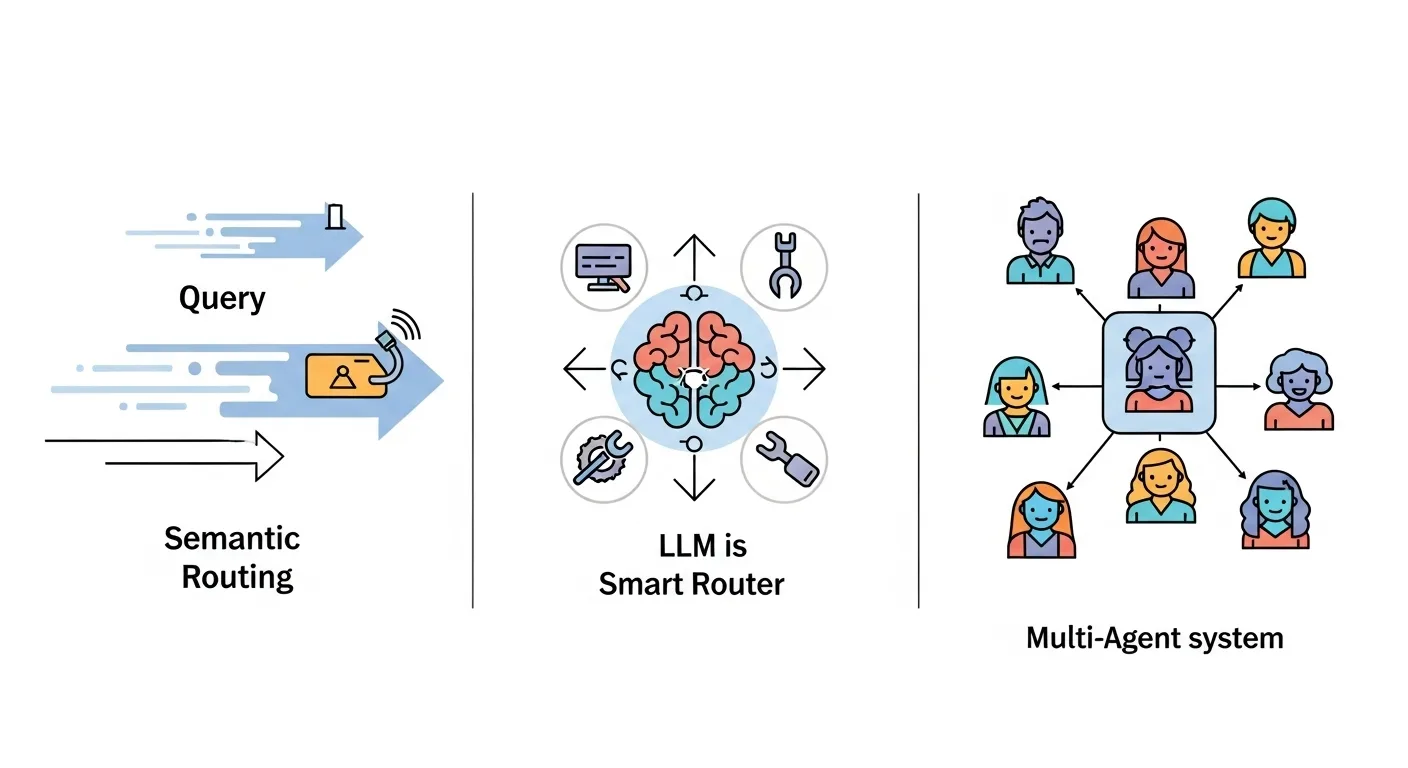
The first and often fastest method for routing queries is semantic routing. This approach works by quickly comparing the meaning of a user's query to predefined categories using math, not a full AI model.
The system converts a user's query into a numerical vector (an "embedding") that captures its meaning. This query embedding is then compared against a set of pre-defined "route" embeddings stored in a vector database. Each route represents a specific category, task, or data source—for example, "billing questions," "technical support," or "product documentation". The system calculates the similarity between the query and all the routes and sends the query to the agent, model, or Retrieval-Augmented Generation (RAG) workflows managed by Kaji.
Open-source libraries like semantic-router provide a clear way to implement this. You start by defining a series of Route objects, each with a name and example phrases that match the user's intent. An encoder model (from providers like OpenAI, Cohere, or a local Hugging Face model) is used to create a
RouteLayer that handles the decisions. This layer uses a fast vector store like Pinecone, Qdrant, or Milvus to perform the similarity search with very low latency.
Semantic routing is the first line of defense in a sophisticated routing system. Its main advantages are its incredible speed and low computational cost. Because it doesn't require a full LLM call to make a routing decision, it can handle a high volume of traffic with minimal delay, making it perfect for initial triage in applications like customer service bots or internal knowledge bases. Its primary job is to quickly and efficiently send a query to the right data source or specialized agent before more expensive resources are used.
This method is also good for when there are data-sensitive queries as theyare not sent off to a LLM provider.
The speed of semantic routing comes at the cost of deep understanding. It can struggle with complex, ambiguous, or multi-part queries that require real reasoning. For example, a query like "My bill is wrong because a feature I was promised isn't working" touches on both "billing" and "technical support." A simple similarity search might miss this nuance. Additionally, the system's effectiveness depends entirely on how well the pre-defined routes are designed. If a user's query doesn't fit neatly into an existing route, it may be misclassified.
While semantic routing focuses on speed, using an LLM as a router prioritizes accuracy and contextual understanding. This approach uses the reasoning power of an LLM to act as an intelligent dispatcher.
To set up smart routing that sends quick questions to a smaller LLM and complex ones to a powerful model like GPT-4 without users noticing, you can use a dedicated LLM as a router. In this setup, a dedicated LLM—often a smaller, faster, and cheaper model—is assigned the role of router. The user's query is sent to this router LLM along with a carefully designed prompt. This prompt includes a list of available "tools" or "functions," which are detailed descriptions of the downstream models, agents, or data APIs that can be used. The router LLM analyzes the query's intent and complexity to select the best tool. For instance, it can be prompted to identify whether a query is a "simple factual lookup" suitable for a lightweight model or a "complex reasoning task" that requires the power of GPT-4. It then generates a structured JSON output with the name of the chosen tool and the exact arguments needed to run it.
The success of this method depends on good prompt engineering. The system prompt must clearly tell the LLM its job is to route queries, and the descriptions for each tool must be clear and detailed to guide its decisions. This is where you define the routing logic to auto-select the cheapest or fastest model. For example, one tool might be summarize_financial_report, best for long financial documents and handled by a model with a large context window. Its description can include parameters like "high-quality, high-cost." Another might be simple_faq_retrieval, for quick factual questions, routed to a cheaper, faster model, with a description like "low-cost, high-speed." The router LLM can then use these descriptions to make a strategic decision based on the query's nature and the desired outcome (e.g., speed for a customer support bot vs. accuracy for a financial report). This allows the system to make smart choices, like sending a complex coding question to GPT-4 while sending a simple summarization request to a model like Claude or Llama.
An LLM-as-a-Router provides a high level of accuracy and contextual awareness that semantic methods can't match. It allows for sophisticated routing based on subtle factors like query complexity, user subscription level, or specific task requirements. This architecture is also highly flexible; new capabilities can be added simply by defining a new tool and describing it to the router LLM, without needing to retrain an embedding model.
The main downsides are the extra latency and cost from making an additional LLM call for every query. Using a smaller router model can help, but it's still slower and more expensive than a vector search. This makes the pattern less ideal for applications where instant responses are critical, but it's invaluable for workflows where the accuracy of the routing decision has a big impact on cost or quality.
The most advanced architectural pattern treats routing not as a single decision but as an ongoing process of coordinating a team of specialized AI agents. This approach models the AI system like a collaborative organization.
In a multi-agent system, a "supervisor" or "router" agent receives the initial query. This agent's job is to analyze the query's overall goal, break it down into smaller sub-tasks, and delegate each sub-task to the right specialist agent. For example, for the query "Analyze our Q3 sales data, compare it to our top three competitors' public earnings reports, and generate a draft presentation," the supervisor might first send a "research agent" to query internal databases and search the web. The results would then go to an "analyst agent" for comparison. Finally, a "writer agent" would take the analysis and create the presentation.
These systems can be designed in several ways, including hierarchies with a clear chain of command or networks where agents communicate freely. Frameworks like LangGraph, CrewAI, and AutoGen are designed to help manage these complex, stateful workflows managed by Kaji, where the routing logic determines the entire sequence of collaboration. The system must be able to manage state, handle handoffs between agents, and recover from errors.
This leads to a key question: how does automatic model routing work in these marketplaces when one model starts under-performing? A robust routing system continuously monitors the performance of each model and provider, tracking metrics like latency, error rates, and response quality. If a model begins to under-perform, the routing layer can dynamically deprioritize it and send traffic to other, more reliable alternatives. This is often handled through a combination of health checks, a service mesh, or by integrating real-time performance data into the routing logic itself, ensuring that your system remains resilient and high-performing even when individual components fail.
This pattern offers the highest degree of modularity and specialization. It allows companies to tackle complex, multi-step business processes that are beyond the scope of a single LLM. By breaking down a problem and assigning parts to specialized agents—each potentially powered by a different model fine-tuned for its task—the system can achieve a level of performance that mirrors a team of human experts.
The power of multi-agent systems, such as those orchestrated by Kaji, comes with significant architectural and operational complexity. Managing communication between agents, maintaining state across long-running tasks, and diagnosing failures are major engineering challenges. Furthermore, because a single user query can trigger multiple LLM calls among the agents, this pattern can lead to high latency and cost if not managed carefully.
A mature enterprise AI system rarely relies on just one routing method. Instead, it uses a hybrid strategy that combines the strengths of each. A query might first go through a high-speed semantic router for initial sorting. From there, it could be sent to a more nuanced LLM-as-a-Router, which might then decide to use a single powerful model or kick off a complex multi-agent workflow. This "funnel" approach creates a system that is optimized for cost, latency, and capability. This evolution from a single model to a routed system of specialized components is similar to the history of software architecture, particularly the shift from monolithic applications to microservices. This parallel provides a useful mental model for technology leaders, allowing them to apply their experience in building modular and scalable systems to the new world of AI.
| Routing Method | How It Works | Ideal Use Cases | Pros & Cons |
|---|---|---|---|
| Semantic Routing | Vector Similarity Search | High-volume, domain-specific sorting; routing to the correct RAG data source. | Low Cost, Low Latency. Less effective for complex or multi-part queries. Depends on the quality of route definitions. |
| LLM-as-a-Router | Function/Tool Calling | Nuanced, context-aware decisions; selecting models based on query complexity or user tier. | High Accuracy. Adds extra cost and latency per query. Requires careful prompt engineering. |
| Multi-Agent Systems | Agent Orchestration & Task Decomposition | Complex, multi-step workflows requiring specialized skills (e.g., research -> analysis -> code generation). | Maximum Capability & Modularity. High architectural complexity, higher potential cost, and latency from multiple LLM calls. |
Understanding the architectural patterns is the first step, but turning a design into a scalable, production-ready system is filled with operational challenges. These hurdles are often strategic and organizational, not just technical. Overcoming them requires a holistic approach that addresses the risks of fragmentation, data security, and the gap between pilot projects and real-world value.
To route traffic from several microservices through a single LLM marketplace endpoint without choking your office routers, you need an intelligent orchestration layer that acts as a central hub. Instead of each microservice making direct, uncoordinated calls, they all send requests to this single, smart routing layer. This layer can then manage the outbound traffic, apply dynamic policies, and even handle retries and load balancing across different models.
As different teams adopt AI, they often do so without coordination, leading to "AI sprawl"—a chaotic mix of tools and models across the organization. This fragmentation creates inefficiency, inconsistent security, and rising costs. Relying too heavily on a single proprietary vendor can also lead to "vendor lock-in," making it difficult and expensive to switch to better alternatives in the future. A successful strategy requires a plan to manage this complexity and maintain architectural independence.
The most valuable AI applications are built on a company's own proprietary data, which often includes sensitive customer or financial information. Sending this data to third-party SaaS AI services creates significant security and compliance risks, as it moves outside your direct control. For any data-sensitive application, it is critical to have a clear strategy for how data is handled, processed, and secured to meet regulatory requirements like GDPR, CCPA, and HIPAA. Implementing security scanners like Trivy for vulnerabilities and Falco for threat detection within the platform is a crucial part of this strategy.
Industry data shows that a high percentage of AI projects—up to 95% by some estimates—never make it out of the pilot phase or fail to deliver a return on investment. The technology often works well in a controlled test, but the real barriers are operational. Integrating with legacy systems, preparing enterprise data, and managing organizational change are complex challenges that can prevent promising AI initiatives from delivering real business value.
The path to enterprise AI success is not about finding the single "best" model. It's a strategic effort focused on building a resilient, secure, and adaptable infrastructure—a robust central nervous system for your organization's entire AI stack. The ultimate goal is to achieve strategic control and independence in the age of AI.
This is a concrete objective defined by full ownership and control over the three core pillars of a successful AI program:
Achieving this state requires a deliberate strategy based on three principles that directly address the critical operational challenges:
For technology leaders, the path forward is clear. When evaluating AI platforms and partners, you must look beyond short-term feature comparisons and focus on these foundational principles. The right architectural and partnership decisions will turn your intelligent routing layer from a simple cost-saving tool into a powerful strategic asset. It becomes the control center through which your organization can build proprietary, defensible, and high-ROI AI capabilities, securing a lasting competitive advantage in an increasingly intelligent world.
Building an intelligent and cost-effective AI routing strategy is a complex but critical task. If you're ready to move from theory to practice, book a meeting with a Shakudo expert to design a routing solution tailored to your specific needs.




















