

Large language models (LLMs) are remarkable tools that aid in tackling various tasks and allow for speedy AI products development. However, they aren't perfect. Their proficiency tends to diminish when dealing with extensive context lengths. In other words, they function optimally when the provided context is high quality and concise.
This is where vector databases and vector similarity search come into play. These powerful tools help in streamlining and optimizing the context for LLMs by ensuring that only the most relevant information is input. The end result? A more efficient and effective usage of language models, primed for various applications.
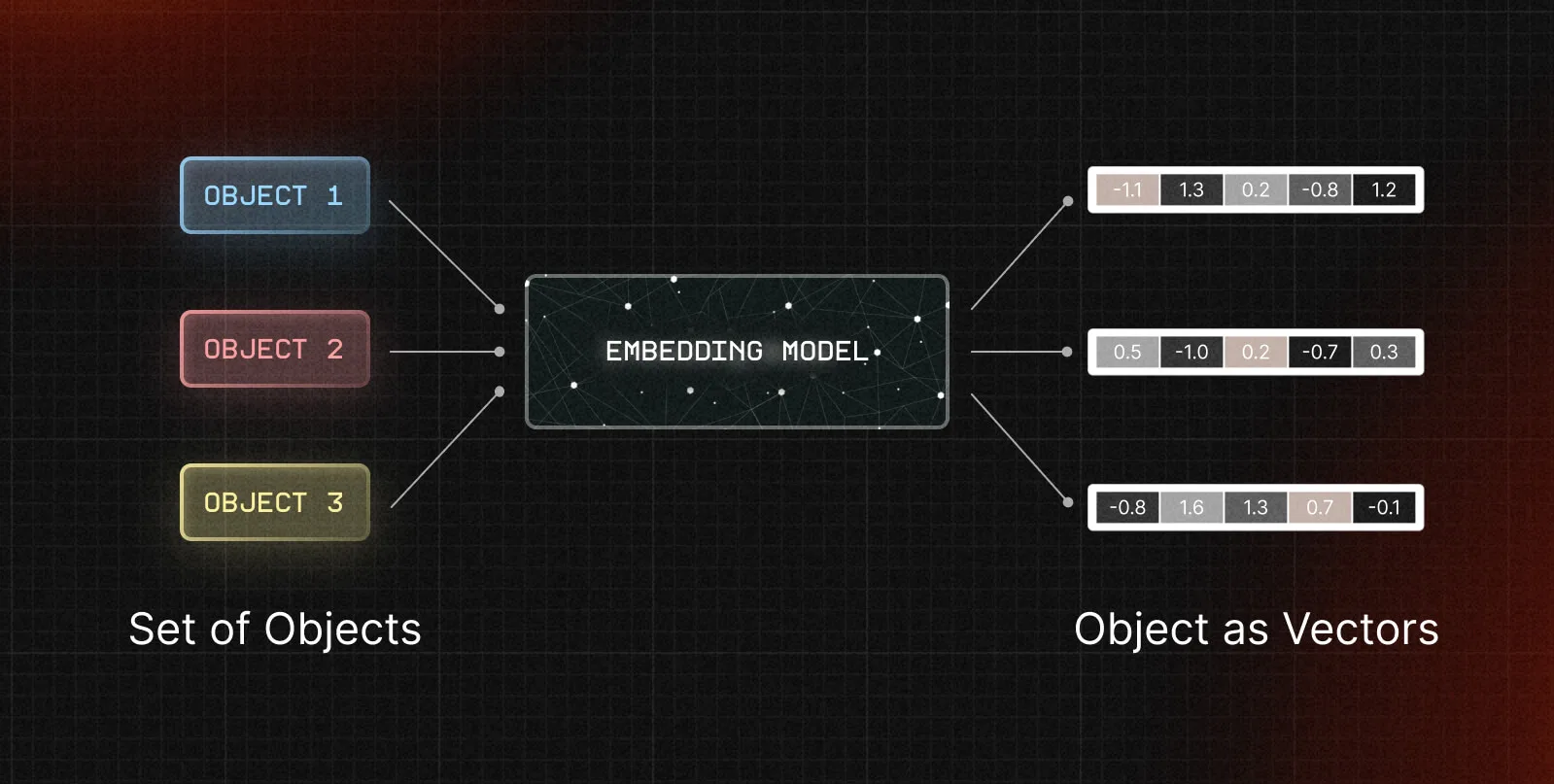
Vector embeddings are essentially a mathematical translation of unstructured data such as text, images, or audio into a lower-dimensional space using a series of numbers, or vectors. In the context of text or sentences, these embeddings encapsulate the semantic content. This means that sentences with similar meanings will be represented by closely positioned vectors in the embedding space.
Various embedding models, each with their unique characteristics, are utilized to derive these vector embeddings. There are many open source and proprietary embedding models to choose from.
The most well-known and widely-used embedding models include Facebook's FastText, renowned for its speed and efficacy, making it a good option for rapid prototyping, and the Sentence BERT models, which are simple to use BERT and RoBERTA-based models.
Among the proprietary models, one popular choice is OpenAI's text-ada-002. This model is made available as an API service by OpenAI, thereby alleviating the need for users to host the model on their own infrastructure. However, using open source models often gives you more control and better safety for your data. Learn more about the benefits of using open source llms.
As of August 3, according to the Massive Text Embedding Benchmark (MTEB)-LeaderBoard presented by Hugging Face, the General Text Embedding (GTE) models, particularly the gte-large variant is currently ranked one on an average benchmark. An accompanying ArXiv paper detailing their methodology and findings is slated to be published in approximately a week. Interestingly, open source models rank better than the text-ada-002 OpenAI API model on this leaderboard.
One key point to consider when assessing embedding models is that while most open source models can handle text embedding for text lengths up to 512 tokens, OpenAI's text-ada-002 API outperforms them by supporting text embedding for text lengths as large as 8192 tokens.
Vector Similarity Search refers to the process of identifying sentences that bear the closest resemblance to a given query sentence. This task is simplified within the context of the vector embedding space. The process involves identifying nearest neighbors via a normalized dot product, also known as cosine similarity. This metric allows us to compare the similarity between two vectors, with a high cosine similarity suggesting a greater degree of likeness.
Conceptualized further, imagine you have a sentence that you want to match to the most similar sentences within a given set or list. Once all these sentences, including your query, are transformed into their vector embeddings, the Vector Similarity Search commences. By evaluating the cosine similarity, you can identify and rank the sentences that bear the most resemblance to your query in terms of their semantic content.
A vector database is a specialized storage system designed to handle these vector embeddings. This type of database not only supports the usual functions like creating, reading, updating, and deleting data entries (CRUD operations), but also has additional capabilities optimized for vector similarity searches.
The real power of a vector database lies in its use of sophisticated indexing methods that make these similarity searches quicker and more efficient. This makes vector databases a valuable tool for managing and querying large volumes of complex, high-dimensional data, such as those commonly found in fields like natural language processing and computer vision.
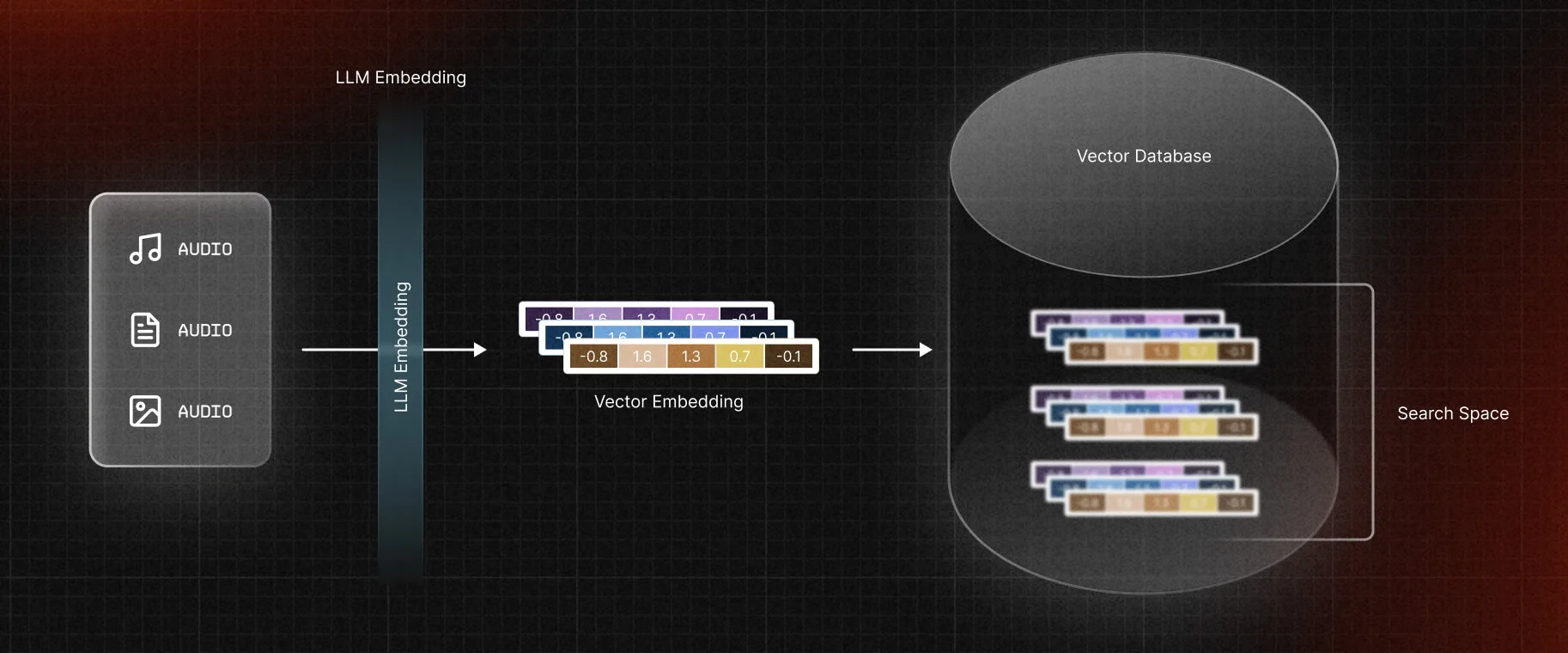
Vector databases primarily operate through a variety of indexing strategies. These strategies create divisions within the data, allowing for a reduction in search space when you query with an embedding to find similar ones. This speeds up the retrieval process. However, since this method may skip over some embeddings located in other divisions, it is considered an approximate method. Hence, this approach is called Approximate Nearest Neighbours (ANN), which approximates the K-Nearest Neighbors algorithm (KNN).
There are several different types of KNN and ANN indices that vector databases can employ:
Flat Indexing: This is essentially the standard KNN algorithm, with no approximation involved. It compares the query vector with every vector in the dataset, which is straightforward but can be computationally expensive for large datasets.
Locality Sensitive Hashing (LSH): LSH introduces a hash function to group similar embeddings into buckets with high probability. It then searches relevant buckets during a query, minimizing the search space.
Facebook AI Similarity Search (FAISS): FAISS employs quantization and indexing for efficient retrieval, supporting both GPU and CPU. Quantization reduces memory usage, optimizing performance.
Hierarchical Navigable Small Worlds (HNSW): HNSW is based on the "small world" phenomenon, where each node can be reached from any other node in a small number of steps. It builds a hierarchical structure of small world graphs, progressively navigating towards the target, which results in faster retrieval.
Scalable Nearest Neighbors (ScaNN): ScaNN uses anisotropic vector quantization to ensure that the quantized vector retains the same cosine similarity as the original vector. It offers an excellent balance between recall and latency tradeoffs.
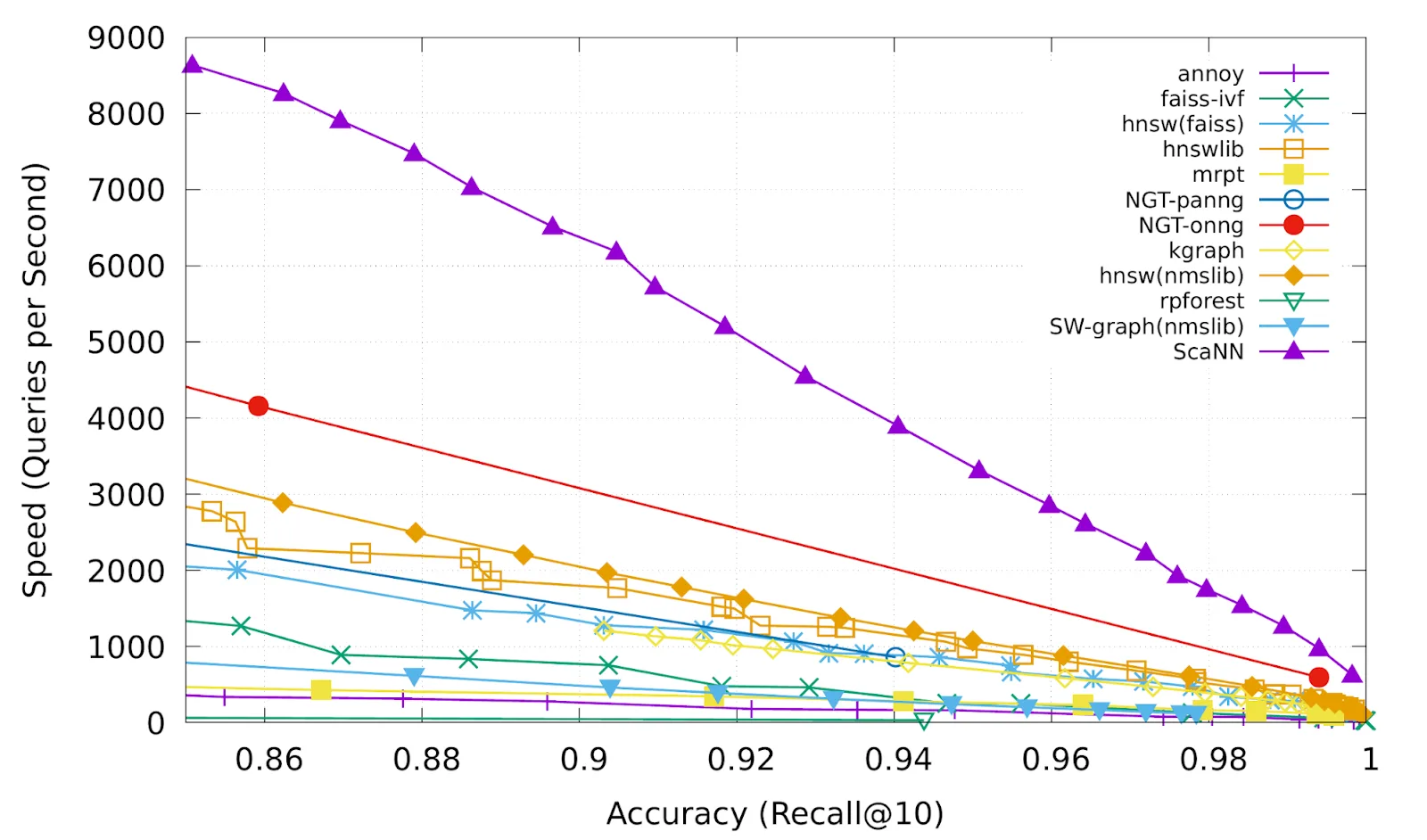
Check out more ANN algorithms and their comparison at ann-benchmarks.com.
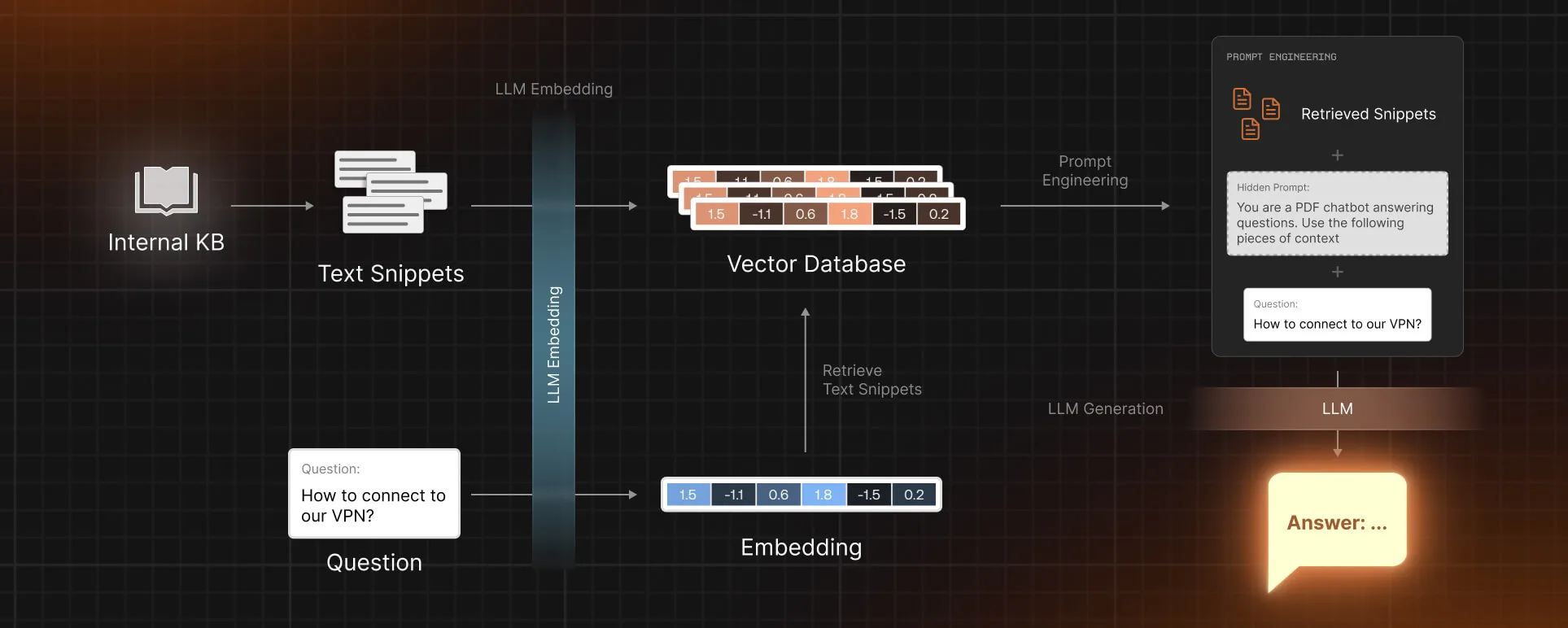
Vector databases play a crucial role in supporting language models (LMs) by serving as knowledge bases. In this application, unstructured data is organized into smaller text snippets, which are converted into embeddings and stored in the vector database. When a user submits a query, it also undergoes the embedding process, allowing efficient similarity search in the vector database to identify relevant text snippets. These retrieved snippets provide optimal context for the language model to generate accurate responses to user questions. To learn more about creating a Chatbot using open source models or OpenAI API, check out our step-by-step tutorials Building a PDF Knowledge Bot With Open Source LLMs and Building a Confluence Q&A App with LangChain and ChatGPT
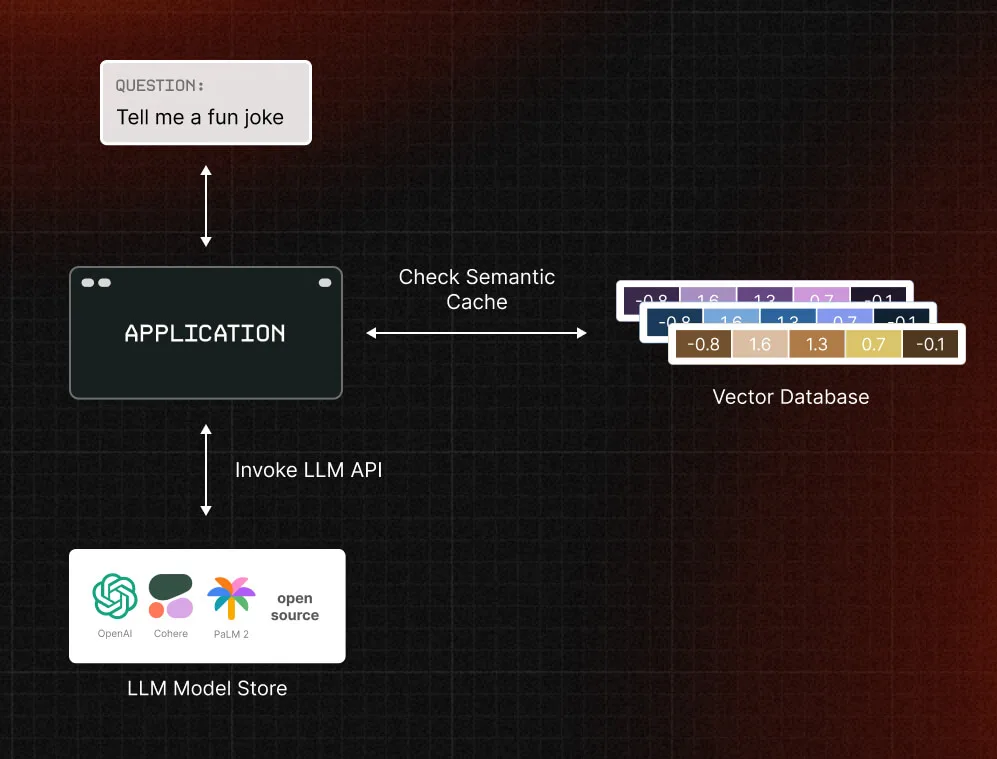
Another practical use of vector databases is semantic caching. Here, the vector database is regularly updated with historical queries. When a new query arrives, the system searches the vector database to find similar queries and determine if a suitable response already exists. This approach significantly reduces application costs by reusing cached responses and minimizing redundant computations. For paid language models, we also cut costs by reducing the number of requests made, which can save a lot of money, especially with larger models like GPT4.
Vector databases are highly effective for enabling natural language search engines. By embedding natural language queries and retrieving textual objects from the vector database, search engines can quickly and accurately match user queries to relevant content. For example, Spotify utilizes Vespa Vector Database to power its natural language search feature for podcast episodes, allowing users to find relevant content easily.
PgVector is an open source vector database that extends PostgreSQL, specifically addressing vector similarity search. Supporting exact and approximate nearest neighbor search, PgVector excels with its comprehensive support for L2 distance, inner product, and cosine distance. By extending PostgreSQL, users can capitalize on database features they're possibly used to, allowing similarity computations to fit right into existing data workflows within a familiar environment.
Elasticsearch's vector database is a powerful and versatile solution for managing vector embeddings at scale. It combines text and vector search for improved relevance and accuracy. The database supports various functionalities, multiple data types, and features like ingest tools, security, and observability. It is an essential tool for vector-related applications.

Milvus is a vector database system designed to handle complex data effectively. It is known for its high speed, performance, scalability, and functions for similarity search, anomaly detection, and natural language processing. Key features of Milvus include fast data retrieval and analysis, management of large datasets, support for various vector data formats, and real-time updates.

Weaviate is a database designed for storing and searching high-dimensional vectors. Its features include semantic search, real-time updates, a flexible schema that can adapt to different data types, and open source visibility. It can provide personalized suggestions, create knowledge graphs, integrate with deep learning frameworks, and perform time series analysis.

Pinecone is a database known for its speed, scalability, and support for complex data. It can quickly locate and retrieve vectors, manage large amounts of vector data, perform real-time updates, and work effectively with text and other complex data types. Pinecone also has automatic indexing and similarity search functions, and can identify unusual behavior in time-series data.
Vespa is a versatile search engine that supports traditional information retrieval and modern vector embedding techniques. It allows hybrid solutions, combining full-text search, approximate nearest neighbor search, structured metadata matching, and various relevance features. With linear scalability and support for high-volume and real-time writes, Vespa offers a powerful solution for building efficient and dynamic search applications.

ChromaDB is a lightweight vector database solution that can handle diverse data structures due to its schema-less design. Key features include high performance, the ability to manage large amounts of data, compatibility with AI applications, scalability, and real-time updates.
Redis focuses on vector data and efficient data processing. It can handle large volumes of vector data, such as tensors, matrices, and numerical arrays, and provides fast query response times due to its in-memory data store. Redis also includes built-in indexing and search capabilities.

Qdrant, a highly efficient vector database, is specialized for similarity search operations and designed to manage complex high-dimensional data. Its architecture improves the speed and accuracy of nearest-neighbor search. Qdrant features support for billions of vectors, excellent recall, and minimal latency, making it an essential tool for applications that demand precise and swift data retrieval, such as search or machine learning applications.
In this blog, we've explored the fundamentals of Vector Databases, from embeddings to indexing methods, and highlighted their significance in various applications. In the next blog, we'll compare different vector databases based on indexing methods, memory usage, and hosting considerations, offering valuable insights for deploying them effectively in your applications. Stay tuned for an in-depth analysis.
Shakudo provides seamless integrations with Milvus, Elasticsearch, PgVector, Redis, and ChromaDB. By leveraging the Shakudo platform, you can effortlessly incorporate vector databases into your workflow, without the hassle of managing individual stacks. Learn more.
References:




















