

In this tutorial, we will create a personalized Q&A app that can extract information from PDF documents using your selected open-source Large Language Models (LLMs). We will cover the benefits of using open-source LLMs, look at some of the best ones available, and demonstrate how to develop open-source LLM-powered applications using Shakudo.
If you want to skip directly to code, we’ve made it available on GitHub!
Let's start by understanding why developers increasingly prefer open-source LLMs over commercial offerings, like OpenAI's APIs.
Open-source LLMs are highly adaptable. They allow users to modify and optimize the models to cater to their needs. This flexibility enables the LLMs to understand and process unique data effectively. Ecosystems of hugging face, LangChain and Pytorch make open-source models easy to infer and finetune for specific use cases.
Adopting open-source LLMs significantly reduces dependency on large AI providers, giving you the freedom to select your preferred technology stack. This autonomy minimizes issues related to vendor lock-in and fosters an environment of collaboration within the developer community.
Cost efficiency is another vital benefit of employing open-source LLMs. For small-scale use (thousands of requests/day), the OpenAI's ChatGPT API is relatively cost-effective at around $1.30/day. For large-scale use (millions of requests/day), it can quickly rise to $1,300/day. In contrast, open-source LLMs on an NVIDIA A100 cost approximately $4/hour or $96/day.
Open-source LLMs provide better data privacy and security. Unlike third-party AI services, these models allow you to maintain complete control over your data, which minimizes the risk of data breaches. OpenAI offers an enterprise license that allows businesses to use and fine-tune their LLMs. This can help businesses address data privacy concerns by allowing them to train the models on their data. However, the enterprise license is expensive and requires a significant amount of technical expertise to use.
Fine-tuning can be time-consuming and expensive. It can also be difficult to ensure that the model is not biased or harmful. Open-source LLMs still offer the best data privacy and security, allowing businesses to completely control their data and training process.
For applications where real-time user interaction is crucial, the high latency of GPT-4 can be a significant drawback. When optimized and deployed efficiently, open-source models can offer much lower latencies, which makes them more suitable for user interfacing applications.
Open-source LLMs enable companies and developers to contribute to the future of AI. The freedom to control the model's architecture, training data, and training process promotes experimentation with novel techniques and strategies. It allows you to stay updated with the latest developments in AI research and contribute to the AI community by sharing your models and techniques.
When it comes to open-source LLMs, there's a variety to choose from, including top ones like Falcon-40B-Instruct and Guanaco-65b. OpenLLM Leaderboard compares text-generative LLMs on different benchmarks.
MTEB leaderboard similarly compares text-embedding models on different tasks.
if (modelName === “e5-large-v2 (0.3B)”) { return “https://huggingface.co/intfloat/e5-large-v2”; } else if (modelName === “instructor-xl (1.3B)”) { return “https://huggingface.co/hkunlp/instructor-xl”; } else if (modelName === “instructor-large”) { return “https://huggingface.co/hkunlp/instructor-large”; } else if (modelName === “sentence-Bert (0.1B)”) { return “https://huggingface.co/sentence-transformers/all-mpnet-base-v2”; }
return ""; }, target: “_blank” } }, { title: “MTEB Average Score”, resizable: false, field: “MTEB Average Score”, hozAlign: “center”, minWidth: 100 }, { title: “Developer”, field: “Developer”, resizable: false, hozAlign: “left”, formatter: “link”, formatterParams: { labelField: “Developer”, url: function(cell) { var modelName = cell.getValue();
if (modelName === “NLP Group of The University of Hong Kong”) { return “https://huggingface.co/hkunlp”; } else if (modelName === “Microsoft”) { return “https://huggingface.co/intfloat”; } else if (modelName === “NLP Group of The University of Hong Kong”) { return “https://huggingface.co/hkunlp”; } else if (modelName === “Nils Reimers and team”) { return “https://huggingface.co/sentence-transformers”; }
return ""; }, target: “_blank” } }, { title: “License”, field: “License”, hozAlign: “left”, resizable: false, minWidth: 150 }, { title: “Commercial usability”, field: “Commercial usability”, hozAlign: “center”, resizable: false, minWidth: 100 }, ], });
For any textual knowledge base (in our case, PDFs), we first need to extract text snippets from the knowledge base and use an embedding model to create a vector store representing the semantic content of the snippets. When a question is asked, we estimate its embedding and find relevant snippets using an efficient similarity search from vector stores. After extracting the snippets, we engineer a prompt and generate an answer using the LLM generation model. The prompt can be tuned based on the specific LLM used.
Experimentation and development are crucial elements in the field of data science. Shakudo’s session facilitates the selection of the appropriate computing resources. It provides the flexibility to choose from Jupyter Notebooks, VS Code Server (provided by the platform) or connecting via SSH to use a preferred local editor.
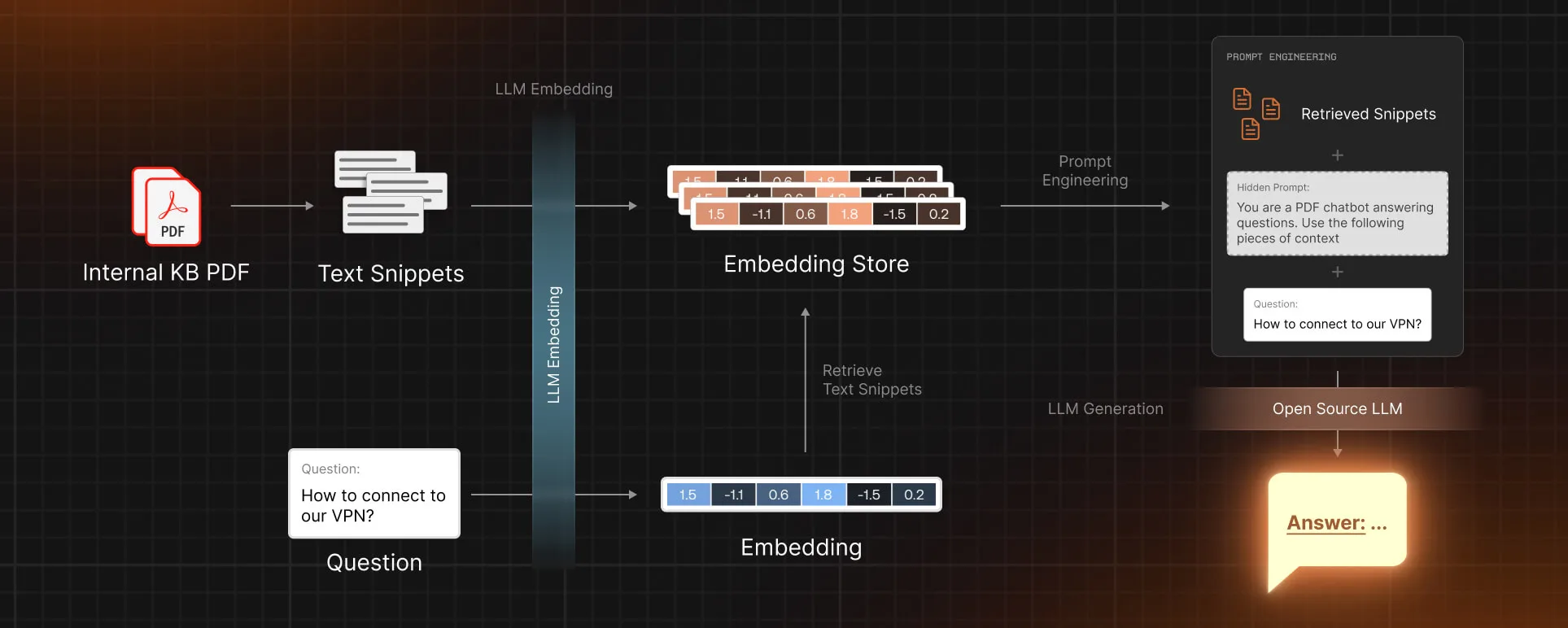
We begin by setting up the models and embeddings that the knowledge bot will use, which are critical in interpreting and processing the text data within the PDFs.
We use the following Open Source models in the codebase:
Hugging faces MTEB leaderboard compares embedding models on different tasks. Instructor XL ranks very highly on this list, even better than OpenAI’s ADA.
EMB_INSTRUCTOR_XL = “hkunlp/instructor-xl”
EMB_SBERT_MPNET_BASE = “sentence-transformers/all-mpnet-base-v2”Open source models used in the codebase are

There are other high-performing open-source models (MPT-7B, StableLM, RedPajama, Guanaco) in the OpenLLM Leaderboard, which can be easily integrated with hugging face pipelines.
LLM_FLAN_T5_XXL = “google/flan-t5-xxl”
LLM_FLAN_T5_XL = “google/flan-t5-xl”
LLM_FASTCHAT_T5_XL = “lmsys/fastchat-t5-3b-v1.0”
LLM_FLAN_T5_SMALL = “google/flan-t5-small”
LLM_FLAN_T5_BASE = “google/flan-t5-base”
LLM_FLAN_T5_LARGE = “google/flan-t5-large”
LLM_FALCON_SMALL = “tiiuae/falcon-7b-instruct”Let’s go ahead and first set up SBERT for the embedding model and FLANT5-Base for the generation model. We chose these models because they can run on an 8 core CPU. FastChat-T5 and Flacon-Instruct-7B require GPU. Loading them is similar and is shown in Codebase:
config = {“persist_directory”:None,
“load_in_8bit”:False,
“embedding” : EMB_SBERT_MPNET_BASE,
“llm”:LLM_FLAN_T5_BASE,
}To employ these models, we use Hugging Face pipelines, which simplify the process of loading the models and using them for inference.
The creation of the models is governed by the configuration settings and is handled by the create_sbert_mpnet() and create_flan_t5_base() functions, respectively.
def create_sbert_mpnet(): device = “cuda” if torch.cuda.is_available() else “cpu” return HuggingFaceEmbeddings(model_name=EMB_SBERT_MPNET_BASE, model_kwargs={“device”: device})def create_flan_t5_base(load_in_8bit=False): # Wrap it in HF pipeline for use with LangChain model=“google/flan-t5-base” tokenizer = AutoTokenizer.from_pretrained(model) return pipeline( task=“text2text-generation”, model=model, tokenizer = tokenizer, max_new_tokens=100, model_kwargs={“device_map”: “auto”, “load_in_8bit”: load_in_8bit, “max_length”: 512, “temperature”: 0.} )
if config[“embedding”] == EMB_SBERT_MPNET_BASE: embedding = create_sbert_mpnet() load_in_8bit = config[“load_in_8bit”] if config[“llm”] == LLM_FLAN_T5_BASE: llm = create_flan_t5_base(load_in_8bit=load_in_8bit)
If we want to load Falcon, the pipeline would be as below and its task is ”text-generation” as Falcon is a decoder-only model. We need to allow remote code execution because the code comes from the Falcon author’s repository and not from hugging face.
def create_falcon_instruct_small(load_in_8bit=False): model = “tiiuae/falcon-7b-instruct”
tokenizer = AutoTokenizer.from_pretrained(model) hf_pipeline = pipeline( task=“text-generation”, model = model, tokenizer = tokenizer, trust_remote_code = True, max_new_tokens=100, model_kwargs={ “device_map”: “auto”, “load_in_8bit”: load_in_8bit, “max_length”: 512, “temperature”: 0.01, “torch_dtype”:torch.bfloat16, } ) return hf_pipeline
This setup forms the foundation of the knowledge bot’s capability to understand and generate responses to textual input.
In this step, let’s load our PDF and split it into manageable text snippets.
# Load the pdf pdf_path = “wiki_data_short.pdf” loader = PDFPlumberLoader(pdf_path) documents = loader.load()Split documents and create text snippets
text_splitter = CharacterTextSplitter(chunk_size=100, chunk_overlap=0) texts = text_splitter.split_documents(documents) text_splitter = TokenTextSplitter(chunk_size=1000, chunk_overlap=10, encoding_name=“cl100k_base”) # This the encoding for text-embedding-ada-002 texts = text_splitter.split_documents(texts)
persist_directory = config[“persist_directory”] vectordb = Chroma.from_documents(documents=texts, embedding=embedding, persist_directory=persist_directory
Now, we retrieve relevant snippets based on question embeddings and then construct a prompt to query the LLM.
hf_llm = HuggingFacePipeline(pipeline=llm) retriever = vectordb.as_retriever(search_kwargs={“k”:4}) qa = RetrievalQA.from_chain_type(llm=hf_llm, chain_type=“stuff”,retriever=retriever)Defining a default prompt for flan models
if config[“llm”] == LLM_FLAN_T5_SMALL or config[“llm”] == LLM_FLAN_T5_BASE or config[“llm”] == LLM_FLAN_T5_LARGE: question_t5_template = """ context: {context} question: {question} answer: """ QUESTION_T5_PROMPT = PromptTemplate( template=question_t5_template, input_variables=[“context”, “question”] ) qa.combine_documents_chain.llm_chain.prompt = QUESTION_T5_PROMPT
Finally, we query the LLM using our question. The PDF knowledge bot will return the relevant information extracted from the PDF.
question = “what’s the reason for financial crisis?”
qa.combine_documents_chain.verbose = True
qa.return_source_documents = True
qa({“query”:question,})To make the code more organized, we can encapsulate all functionalities into a class.
class PdfQA: def init(self,config:dict = {}): self.config = config self.embedding = None self.vectordb = None self.llm = None self.qa = None self.retriever = None…
Check out the full script on the Github link on the intro
We can now initialize and run the PdfQA class with the following code:
# Configuration for PdfQAconfig = {“persist_directory”:None, “load_in_8bit”:False, “embedding” : EMB_SBERT_MPNET_BASE, “llm”:LLM_FLAN_T5_BASE, “pdf_path”:“wiki_data_short.pdf” }
Initialize PdfQA
pdfqa = PdfQA(config=config) pdfqa.init_embeddings() pdfqa.init_models()
Create Vector DB
pdfqa.vector_db_pdf()
Set up Retrieval QA Chain
pdfqa.retreival_qa_chain()
Query the model
question = “what the reason for financial crisis?” pdfqa.answer_query(question)
Shakudo integrates with various tools you can choose to build your front end. For this app, let’s wrap our web application around our PdfQA class with Streamlit, a Python library that simplifies app creation.
Below is the code breakdown:
We start by importing the necessary modules
import streamlit as st
from pdf_qa import PdfQA
from pathlib import Path
from tempfile import NamedTemporaryFile
import time
import shutil
from constants import * ## constants.py file can be found in codeNow, let’s set the page configuration and have a session state of the class to avoid instantiating the class multiple times in the same session.
# Streamlit app code st.set_page_config( page_title=‘Q&A Bot for PDF’, page_icon=’🔖’, layout=‘wide’, initial_sidebar_state=‘auto’, )
if “pdf_qa_model” not in st.session_state: st.session_state[“pdf_qa_model”]:PdfQA = PdfQA() ## Intialisation
To load the model and embedding on the GPU or CPU only once across all the client sessions, we cache the LLM and embedding pipelines.
## To cache resource across multiple session @st.cache_resource def load_llm(llm,load_in_8bit):if llm == LLM_OPENAI_GPT35: pass elif llm == LLM_FLAN_T5_SMALL: return PdfQA.create_flan_t5_small(load_in_8bit) elif llm == LLM_FLAN_T5_BASE: return PdfQA.create_flan_t5_base(load_in_8bit) elif llm == LLM_FLAN_T5_LARGE: return PdfQA.create_flan_t5_large(load_in_8bit) elif llm == LLM_FASTCHAT_T5_XL: return PdfQA.create_fastchat_t5_xl(load_in_8bit) elif llm == LLM_FALCON_SMALL: return PdfQA.create_falcon_instruct_small(load_in_8bit) else: raise ValueError(“Invalid LLM setting”)
To cache resource across multiple session
@st.cache_resource def load_emb(emb): if emb == EMB_INSTRUCTOR_XL: return PdfQA.create_instructor_xl() elif emb == EMB_SBERT_MPNET_BASE: return PdfQA.create_sbert_mpnet() elif emb == EMB_SBERT_MINILM: pass ##ChromaDB takes care else: raise ValueError(“Invalid embedding setting”)
Create our Steamlit app sidebar to include radio buttons for model selection and a file uploader. Once the file is submitted, It triggers the model loading and PDF ingestion to create a vector store.
with st.sidebar: emb = st.radio(“Select Embedding Model”, [EMB_INSTRUCTOR_XL, EMB_SBERT_MPNET_BASE,EMB_SBERT_MINILM],index=1) llm = st.radio(“Select LLM Model”, [LLM_FASTCHAT_T5_XL, LLM_FLAN_T5_SMALL,LLM_FLAN_T5_BASE,LLM_FLAN_T5_LARGE,LLM_FLAN_T5_XL,LLM_FALCON_SMALL],index=2) load_in_8bit = st.radio(“Load 8 bit”, [True, False],index=1) pdf_file = st.file_uploader(“Upload PDF”, type=“pdf”)
if st.button(“Submit”) and pdf_file is not None: with st.spinner(text=“Uploading PDF and Generating Embeddings..”): with NamedTemporaryFile(delete=False, suffix=’.pdf’) as tmp: shutil.copyfileobj(pdf_file, tmp) tmp_path = Path(tmp.name) st.session_state[“pdf_qa_model”].config = { “pdf_path”: str(tmp_path), “embedding”: emb, “llm”: llm, “load_in_8bit”: load_in_8bit } st.session_state[“pdf_qa_model”].embedding = load_emb(emb) st.session_state[“pdf_qa_model”].llm = load_llm(llm,load_in_8bit) st.session_state[“pdf_qa_model”].init_embeddings() st.session_state[“pdf_qa_model”].init_models() st.session_state[“pdf_qa_model”].vector_db_pdf() st.sidebar.success(“PDF uploaded successfully”)
Add a text input box for the question. Once we submit the question, it triggers the retrieval of relevant text snippets from the vector store and queries the LLM with an appropriate prompt.
question = st.text_input(‘Ask a question’, ‘What is this document?’)
if st.button(“Answer”): try: st.session_state[“pdf_qa_model”].retreival_qa_chain() answer = st.session_state[“pdf_qa_model”].answer_query(question) st.write(f”{answer}”) except Exception as e: st.error(f”Error answering the question: {str(e)}“)
This user interface allows the user to upload a PDF file, choose the model to use and ask a question.
Finally, our app is ready, and we can deploy it as a service on Shakudo. The platform makes the deployment process easier, allowing you to put your application online quickly.
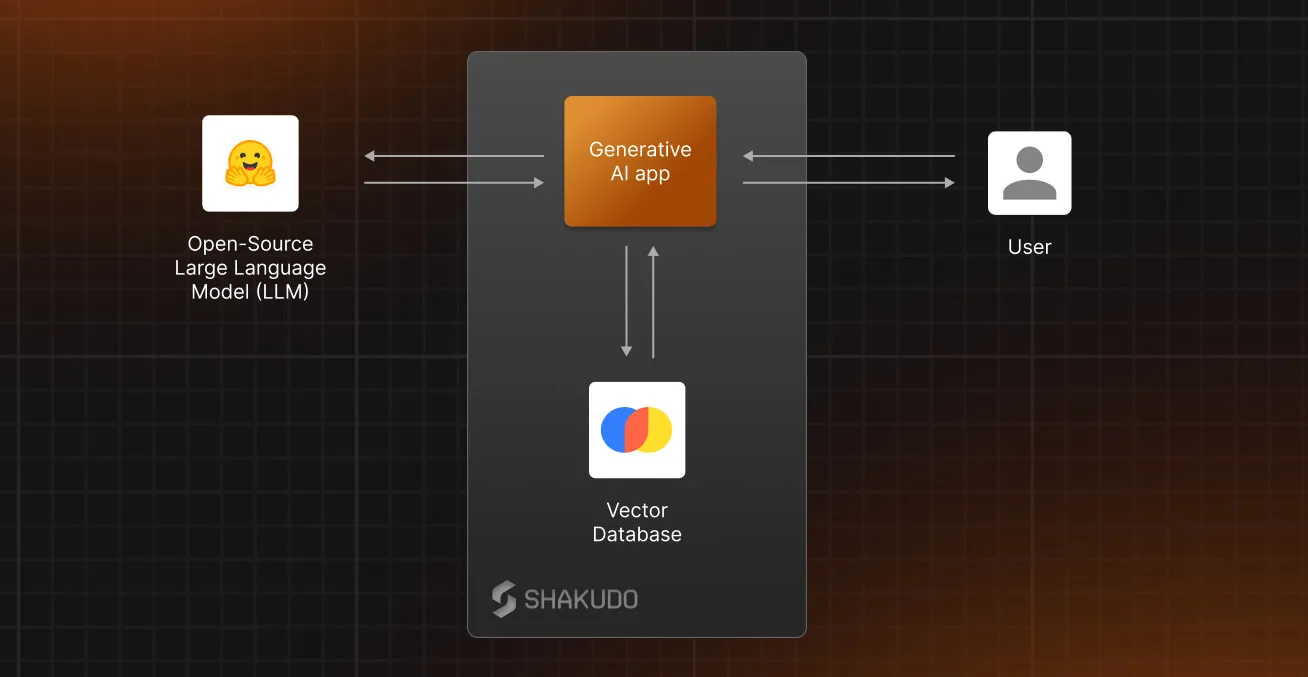
Finally, our app is ready, and we can deploy it as a service on Shakudo. The platform makes the deployment process easier, allowing you to put your application online quickly.
Deploying applications on Shakudo offers enhanced security and control. Unlike many other deployments, Shakudo locks your application behind the SSO or your organization. The services and the self-hosted models run entirely within your cloud tenancy and on your dedicated Shakudo cluster, providing you with the flexibility to avoid vendor lock-in and enabling you to retain control over your applications running in the cloud
To deploy your app on Shakudo, we need two key files: pipeline.yaml, which describes our deployment pipeline, and run.sh, a bash script to set up and run our application. Here’s what these files look like.
pipeline:
name: “QA demo”
tasks:
- name: “QA app”
type: “bash script”
port: 8787
bash_script_path: “LLM/QA_app/run_qa.sh”PROJECT_DIR=”$(cd -P ”$(dirname ”${BASH_SOURCE[0]}”)” && pwd)”cd “$PROJECT_DIR”
export PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python export STREAMLIT_RUNONSSAVE=True pip install -r requirements.txt
streamlit run streamlit_app_blog.py —server.port 8787 —browser.serverAddress localhost
In this script:
Now, our application is live! We can browse through the user interface to see how it works.
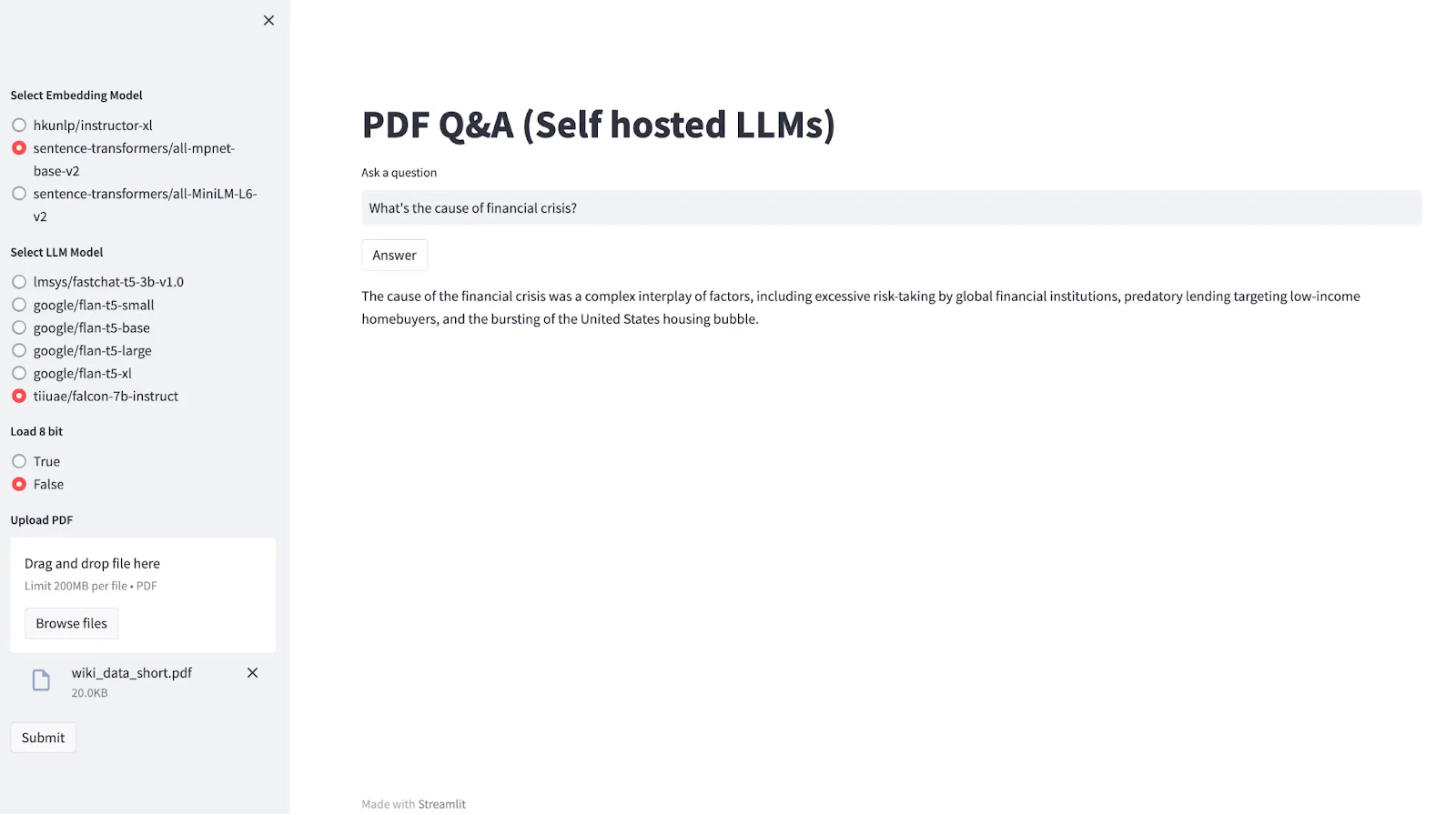
Shakudo Services not only simplifies the deployment of your applications but also has a robust approach to security. Deploying your models within your Virtual Private Cloud (VPC) is one of the most secure ways of hosting models, as it isolates them from the public internet and provides better control over your data.
In this tutorial, we described the advantages of using open-source LLMs over Commercial APIs. We showed how to integrate OSS LLMs Falcon, FastChat, and FlanT5 to query the internal Knowledge Base with the help of Hugging Face pipelines and LangChain.
Hosting and managing open-source LLMs can be a complex and challenging task. Shakudo simplifies LLM infrastructure, saving time, resources, and expertise. For a first-hand experience of our platform, we encourage you to reach out to our team and book a demo.
To understand about the practical applications with OpenAI APIs, we recommend reading our previous post about “Building a Confluence Q&A App with LangChain and ChatGPT” where we showcase a real-world use case, a chatbot to query your confluence directories. For further reading on LangChain, check out CommandBar’s in-depth guide.
* The code is adapted based on the work in LLM-WikipediaQA, where the author compares FastChat-T5, Flan-T5 with ChatGPT running a Q&A on Wikipedia Articles.




















