

The Large Language Model Powered Tools Market Report estimates that the global market for LLM-powered tools reached USD 1.43 billion in 2023, with a projected growth rate of 48.8% CAGR from 2024 to 2030. Yes—new LLM tools are entering the market at a rapid pace, making it increasingly challenging to select the right tool for different targeted use cases.
With such rapid growth in the diversity of options, a robust evaluation system that assesses the various strengths, weaknesses, and characteristics of these models is essential to ensure that users can make informed decisions and choose tools that align with their objectives and use cases.
Enter LLM Leaderboards. By definition, these leaderboards are a framework used to compare the performance of existing natural language models. They offer different perspectives on LLM performance, covering aspects like general knowledge, coding, medical expertise, and more.
To help you navigate this landscape, we’ve curated a list of the top 10 most popular and versatile leaderboards that we think are the most valuable in the current market for anyone looking to make informed decisions in model selection. Each of these leaderboards offers unique insights and metrics that can guide you in evaluating the performance of various language models, ensuring that you choose the right tool for your specific needs.
While leaderboards can use a range of evaluation metrics such as classification, accuracy, F1 score, and perplexity, these metrics are quite query-specific depending on the specific tasks the language models are being evaluated on.
Generally speaking, to be considered high-performing, a natural language model needs to excel in the following benchmarks:
Accuracy, while seemingly straightforward, is a fundamental metric in evaluating the performance of language models. It is typically defined as the ratio of correct predictions made by the model to the total number of predictions. In other words, accuracy measures how often the language model's outputs align with the expected or true outcomes.
In the context of LLMs, accuracy can be particularly crucial in tasks such as classification, where the model must categorize inputs correctly. For instance, in sentiment analysis, a model’s ability to accurately determine whether a piece of text expresses positive, negative, or neutral sentiment is a direct reflection of its accuracy.
F1-score refers to a specific metric used to evaluate the performance of language models on tasks that involve classification or information retrieval. The F1-score combines precision and recall into a single metric, providing a balance between the two.
The F1 score is calculated using the formula:
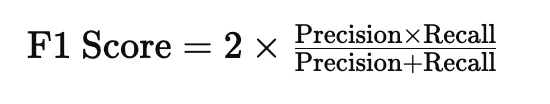
**Precision measures the proportion of true positive results among all positive predictions, indicating how many selected items are relevant.
**Recall measures the proportion of true positive results among all actual positive cases, indicating how many relevant items were selected.
An F1 score ranges from 0 to 1, where 1 indicates perfect precision and recall. In the context of LLM leaderboards, a higher F1 score signifies better model performance on tasks like sentiment analysis, named entity recognition, or other classification tasks, helping researchers compare different models effectively.
The BLEU (Bilingual Evaluation Understudy) evaluates the quality of machine-translated text against human translations. It compares machine-generated texts to reference texts and calculates the similarity based on phrase consistency and overall structure.
The BLEU score is calculated using this formula:
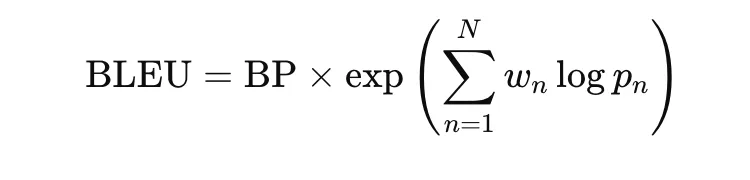
**w_n is the weight applied to the n-gram accuracy score. Weights are often set to 1/n, where n refers to the number of n-gram sizes utilized
**p_n represents the precision rating for the n-gram size
The BLEU scores range from 0 to 1, with 1 being a perfect match to the reference translation. In practice, scores of 0.6-0.7 are considered very good.
While more expensive and time-consuming, human reviewers can evaluate LLM outputs based on criteria like relevance, factuality, and fluency. This evaluation metric incorporates human judgment on factors like coherence and relevance.
Human evaluations can capture nuanced aspects of language and meaning that automated systems might overlook, making them invaluable for tasks requiring a deeper understanding of context and intent. However, the key to such evaluation often involves creating structured rubrics or guidelines to ensure consistency across different human evaluators.
Perplexity measures how well a language model predicts a sample of text. It's calculated as the inverse probability of the test set normalized by the number of words.
The perplexity score is calculated using the formula:
Perplexity = exp(-1/N * sum(log P(w_i)))
**N is the number of words
**P(w_i) is the probability assigned to each word by the model
A lower score indicates that the model is more certain about its predictions, which is generally associated with better model performance. This is because a lower perplexity means the model is assigning higher probabilities to the actual words in the text, suggesting it has a better understanding of the underlying patterns and structures of the language. Conversely, a higher perplexity score indicates greater uncertainty, meaning the model struggles to predict the next word effectively.
Now, let’s get to the heart of our discussion.
As of September 2024, several prominent LLM leaderboards are actively monitoring and evaluating the performance of large language models across a diverse range of benchmarks and tasks. These leaderboards provide invaluable insights into how different models stack up against each other, helping researchers and practitioners understand the strengths and weaknesses of various approaches.
Here are some of the top LLM leaderboards you should know about:
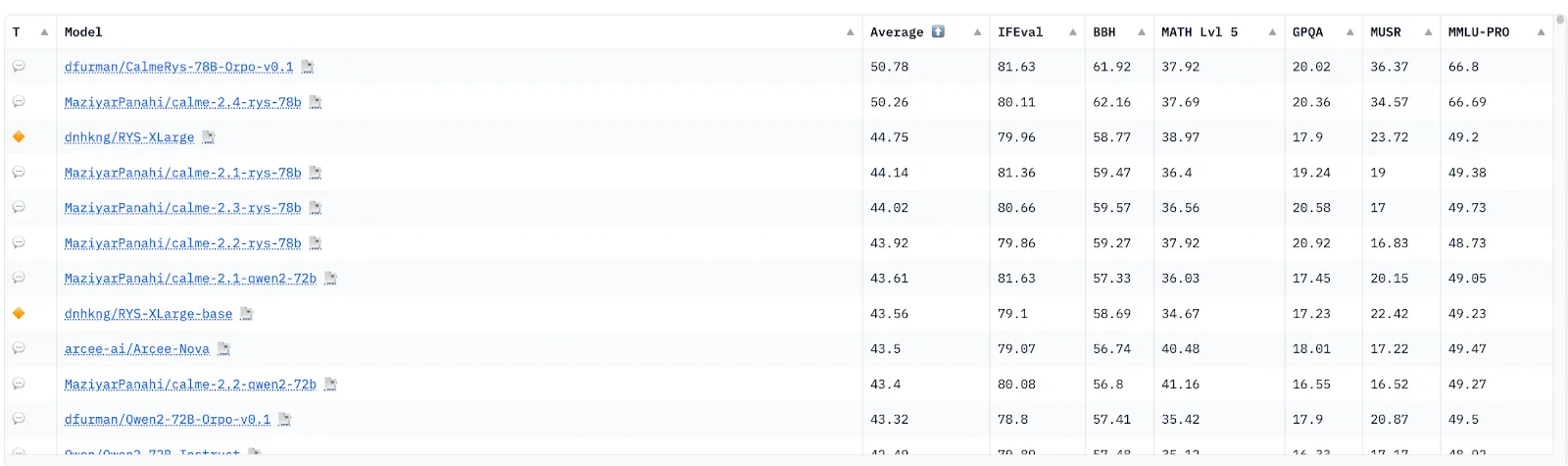
The Hugging Face Open LLM Leaderboard is an automated evaluation system that evaluates models across six tasks including reasoning and general knowledge. It uses the Eleuther AI Language Model Evaluation Harness as its backend for evaluating and benchmarking large language models, allowing any causal language model to be evaluated using the same inputs and codebase, ensuring comparability and reproducibility of results.
The leaderboard uses 6 main tasks to assess model performance, including:
ARC (AI2 Reasoning Challenge) evaluates a model's ability to answer grade-school level, multiple-choice science questions. It tests reasoning skills and basic scientific knowledge.
HellaSwag assesses common sense reasoning and situational understanding. Models must choose the most plausible ending to a given scenario from multiple options.
MMLU (Massive Multitask Language Understanding) is a comprehensive benchmark covering 57 subjects across fields like mathematics, history, law, and medicine. It tests both breadth and depth of knowledge.
TruthfulQA measures a model's ability to provide truthful answers to questions designed to elicit false or misleading responses. It assesses the model's resistance to generating misinformation.
Winogrande evaluates commonsense reasoning through pronoun resolution tasks. Models must correctly identify the antecedent of a pronoun in sentences with potential ambiguity.
GSM8K (Grade School Math 8K) tests mathematical problem-solving skills using grade school-level word problems. It assesses a model's ability to understand, reason about, and solve multi-step math problems.
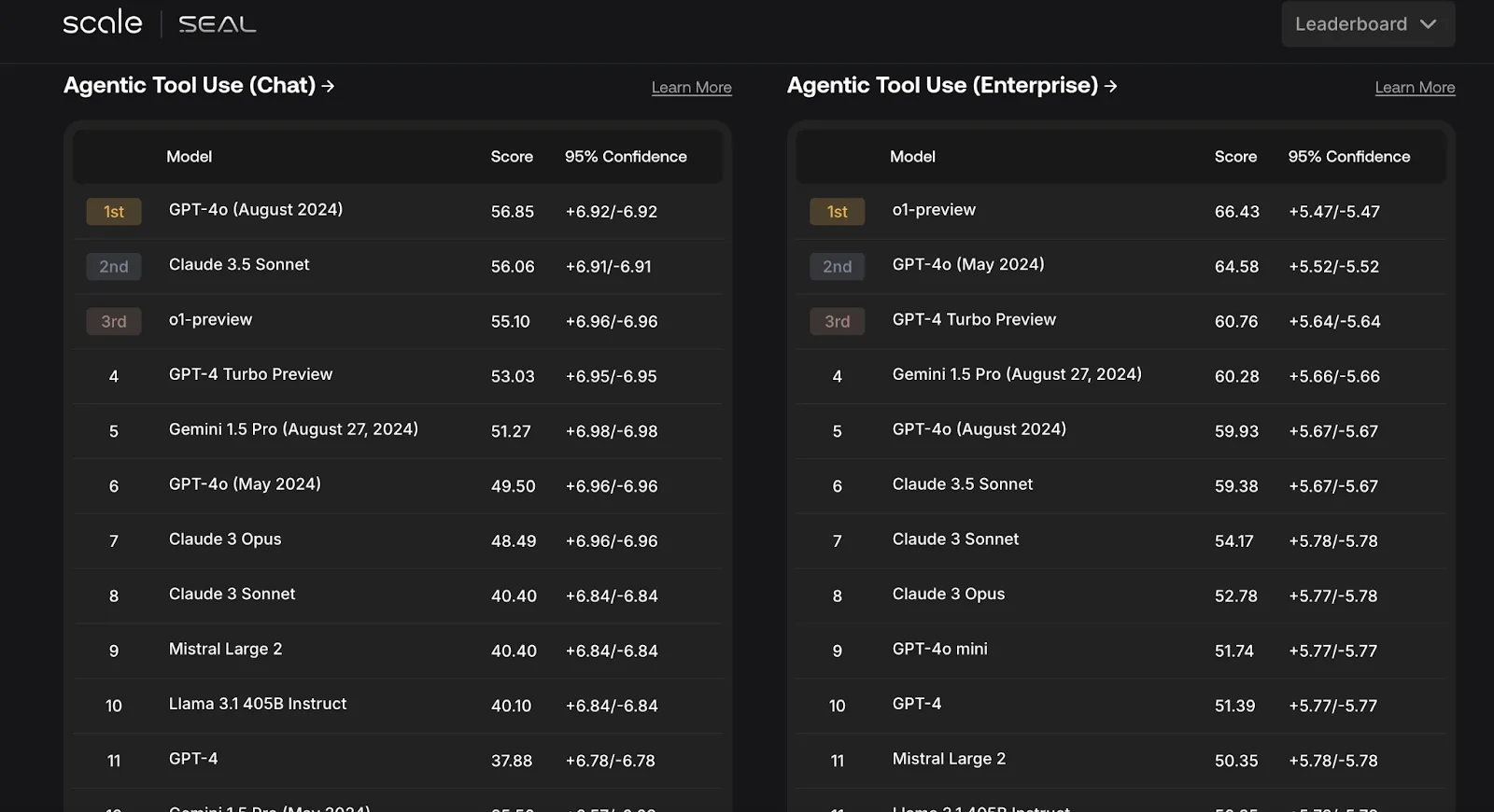
Scale AI created the SEAL (Safety, Evaluations, and Alignment Lab) to address common problems in LLM evaluation, like biased data and inconsistent reporting. It addresses a major hurdle in AI development: the race to the bottom caused by companies manipulating benchmarks to make their LLMs appear better. This often leads to contamination and overfitting, where models learn to perform well on specific tests but struggle in real-world applications.
These leaderboards utilize private datasets to guarantee fair and uncontaminated results, and cover areas like adversarial robustness and coding. Regular updates ensure the leaderboard reflects the latest in AI advancements, making it an essential resource for understanding the performance and safety of top LLMs.
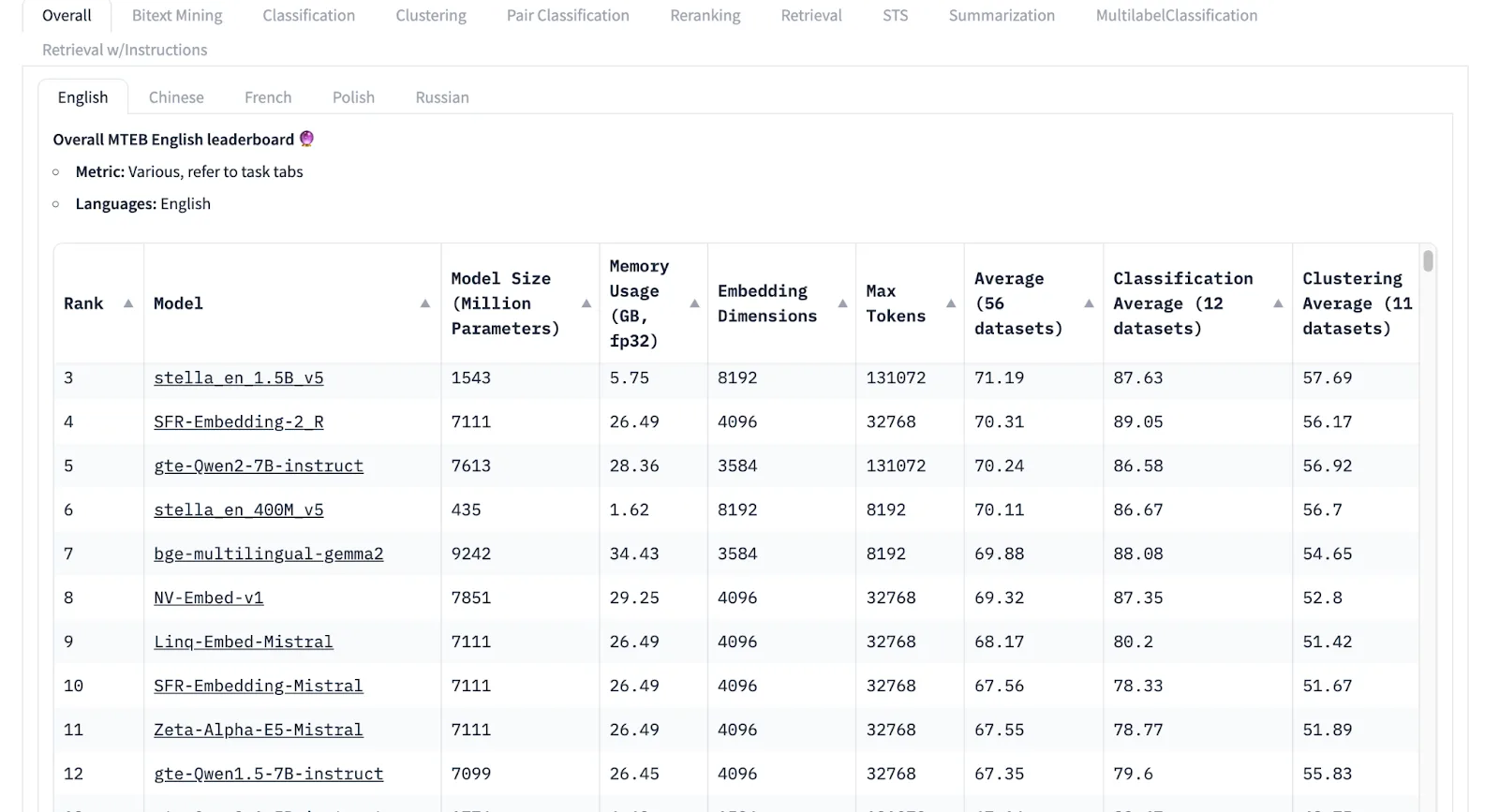
The MTEB (Massive Text Embedding Benchmark) Leaderboard is an automated evaluation system for comparing and ranking embedding models. It uses multiple tasks to assess model performance across various embedding-related tasks and focuses on text embeddings across 8 tasks and 58 datasets. As of September 2024, this leaderboard evaluates 33 models on 112 languages.
The MTEB leaderboard is commonly used to find state-of-the-art open-source embedding models and evaluate new work in embedding model development.
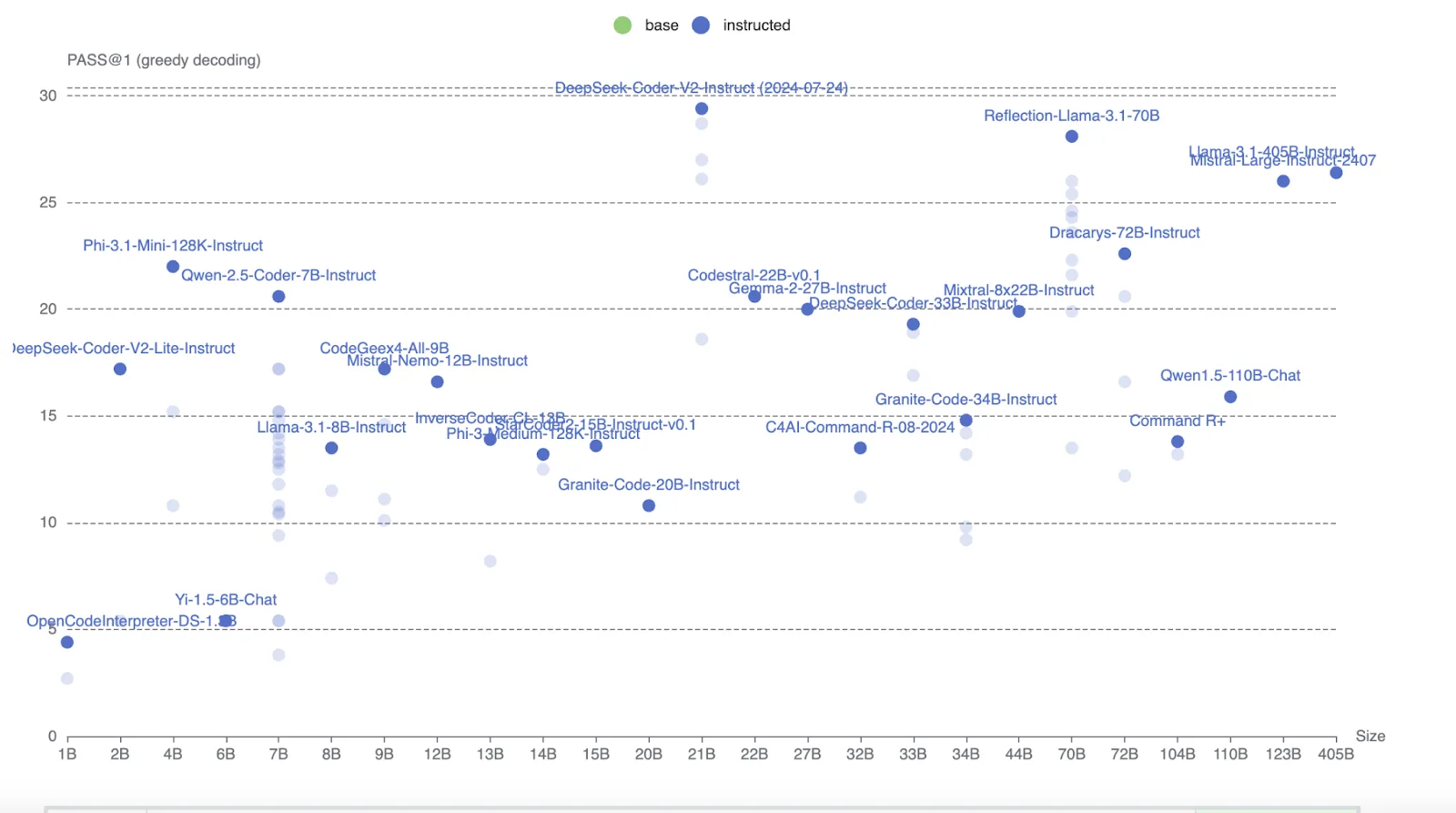
BigCodeBench is a new benchmark for evaluating LLMs on practical and challenging programming tasks; it includes 1,140 function-level tasks designed to challenge LLMs in following instructions and composing multiple function calls using tools from 139 libraries. To ensure a thorough evaluation, each programming task features an average of 5.6 test cases with a branch coverage of 99%.
The tasks use HumanEval and MultiPL-E benchmarks and are designed to mimic real-world scenarios, requiring complex reasoning and problem-solving skills. This makes the benchmark more relevant for assessing practical coding capabilities.
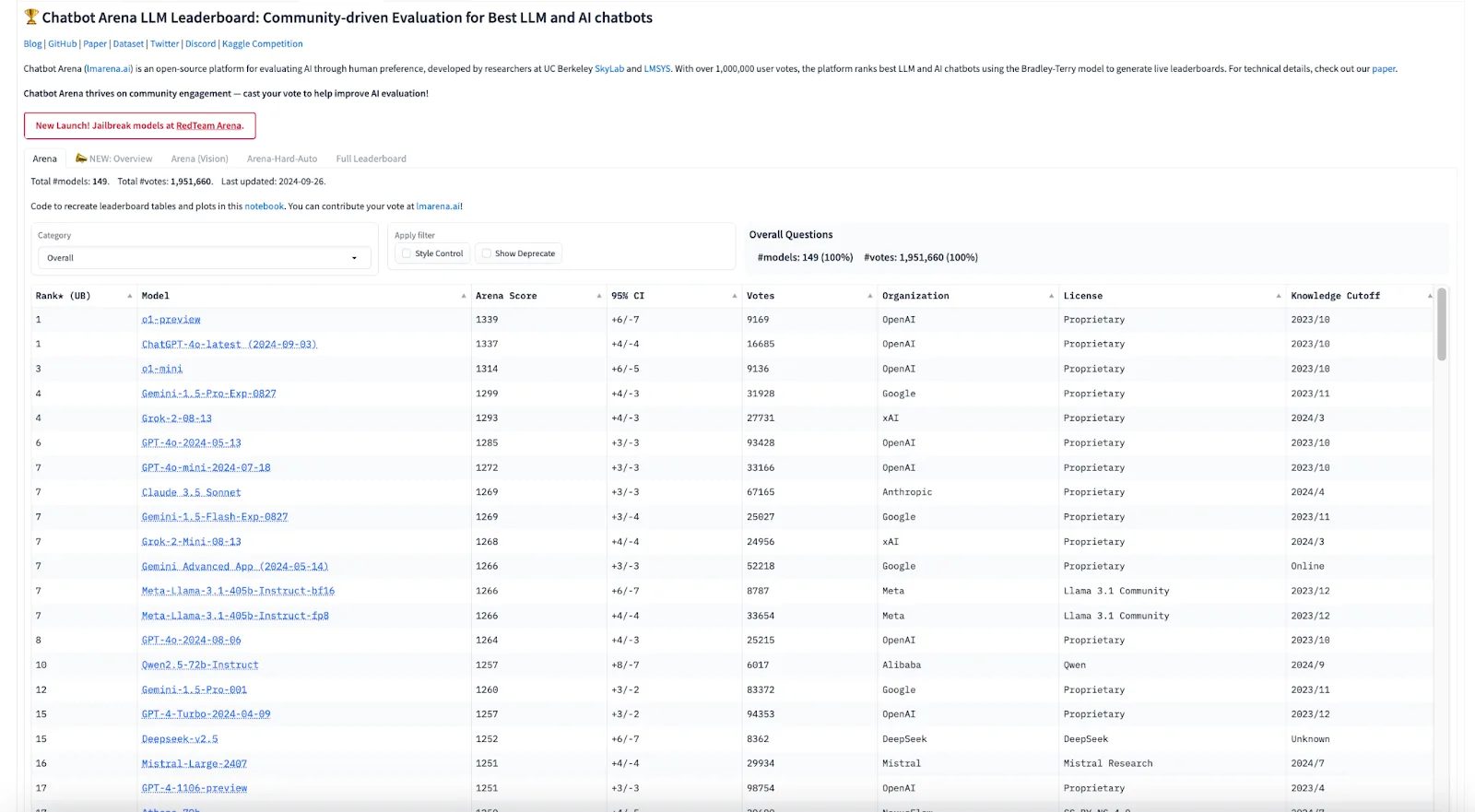
LMSYS is a benchmark platform for evaluating LLMs through crowdsourced, anonymous, randomized battles. It features a crowdsourced evaluation system where users can interact with two anonymous models side-by-side and vote on which one they believe performs better. This method leverages real-world user interactions to assess model performance effectively.
Utilizing the Elo rating system, commonly associated with chess, LMSYS ranks LLMs based on their results in these head-to-head comparisons. On the other hand, the Diverse Model Inclusion ensures that both open-source and closed-source models are represented, allowing for comprehensive evaluations across different types of LLMs.
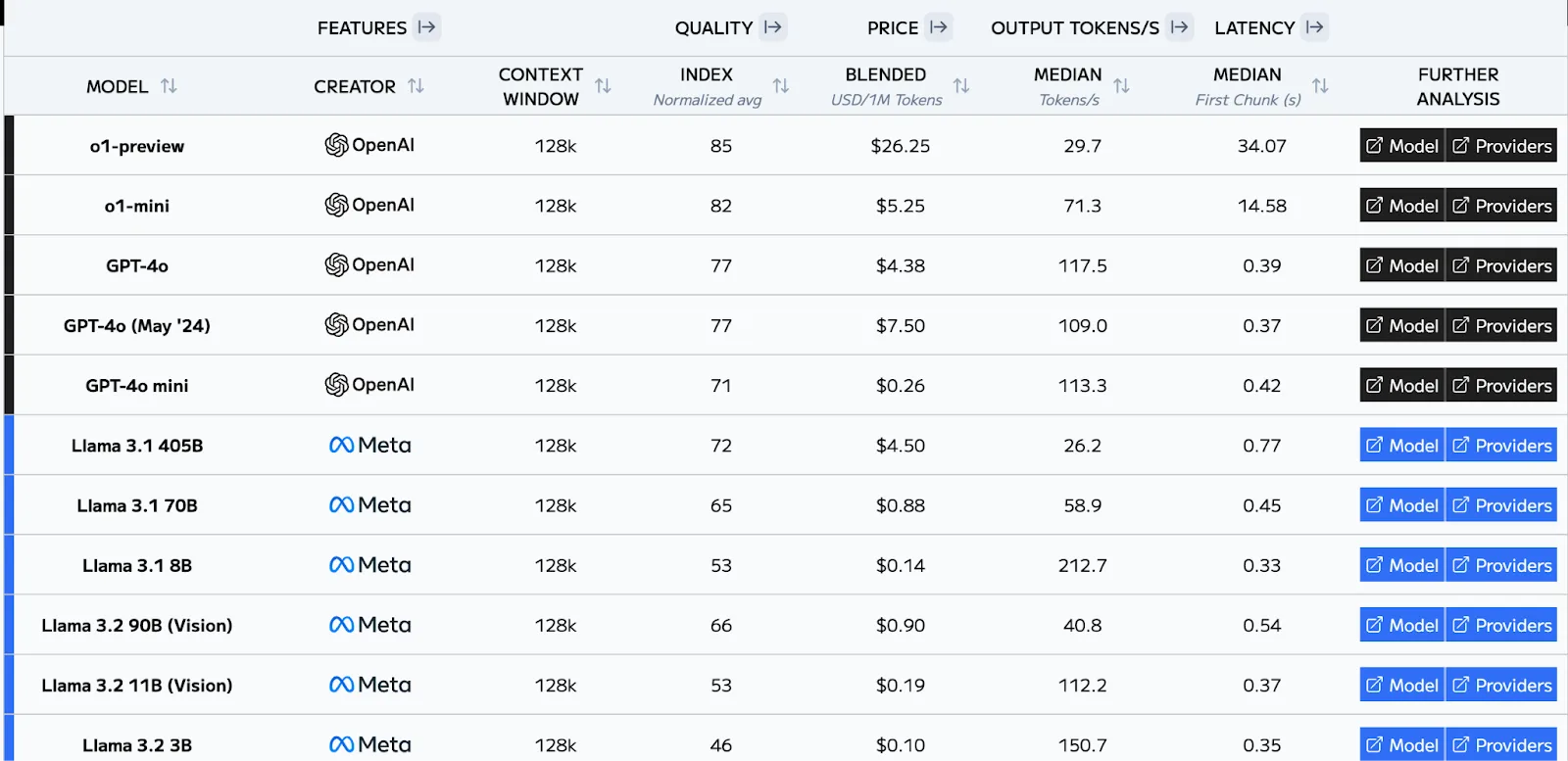
The Artificial Analysis LLM Performance Leaderboard is a comprehensive evaluation platform that provides a wide range of performance metrics, including quality, speed, latency, pricing, and context window size, allowing for a holistic assessment of LLM capabilities.
The leaderboard evaluates models under various conditions, including different prompt lengths (100, 1k, 10k tokens) and parallel query scenarios (1 and 10 queries). It benchmarks LLMs on serverless API endpoints and the data is refreshed frequently, with each API endpoint tested 8 times per day, ensuring the information remains current and relevant. This makes it a rather important resource for businesses looking to select the most appropriate LLM to improve customer insights.
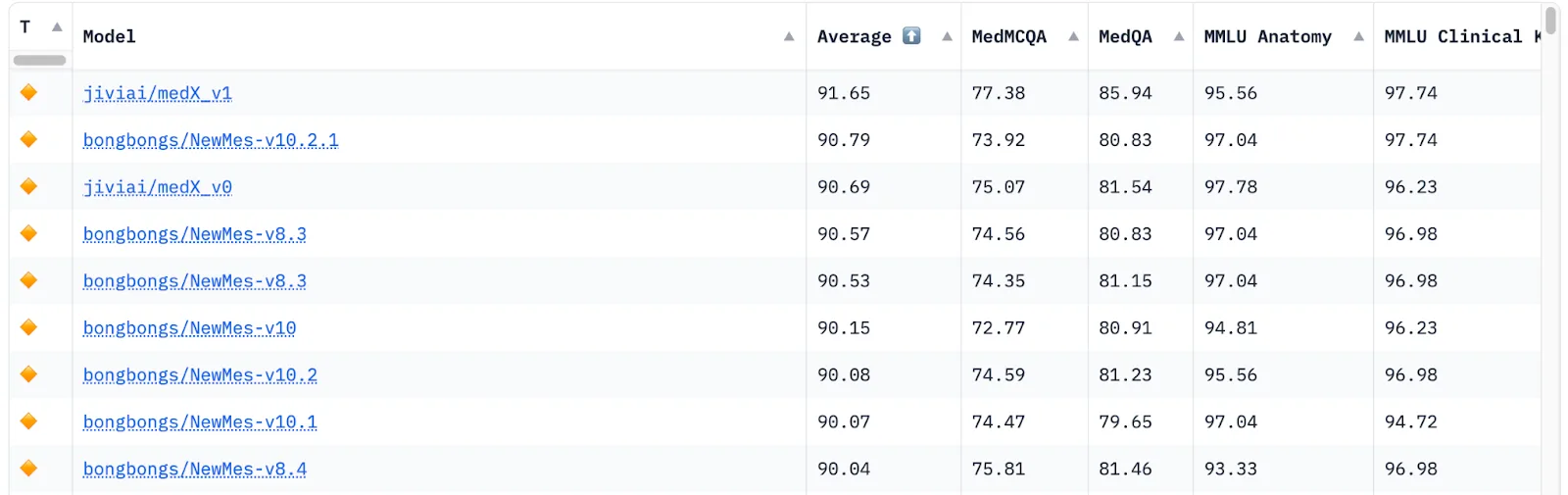
As you can see from its name, the Open Medical LLM Leaderboard evaluates language models specifically for medical applications, assessing their performance on relevant medical tasks.
Unlike other general-purpose LLM leaderboards, this one specifically targets medical knowledge, which is crucial for developing AI tools for healthcare applications.
The platform assesses LLMs across various medical datasets, including MedQA, PubMedQA, MedMCQA, and medicine-related subsets of MMLU, providing a broad evaluation of medical knowledge and reasoning capabilities.
The HHEM model series is designed to detect hallucinations in LLMs. These models are especially valuable for building retrieval-augmented generation (RAG) applications, where an LLM summarizes a set of facts. HHEM can then be used to assess how factually consistent this summary is with the original information.
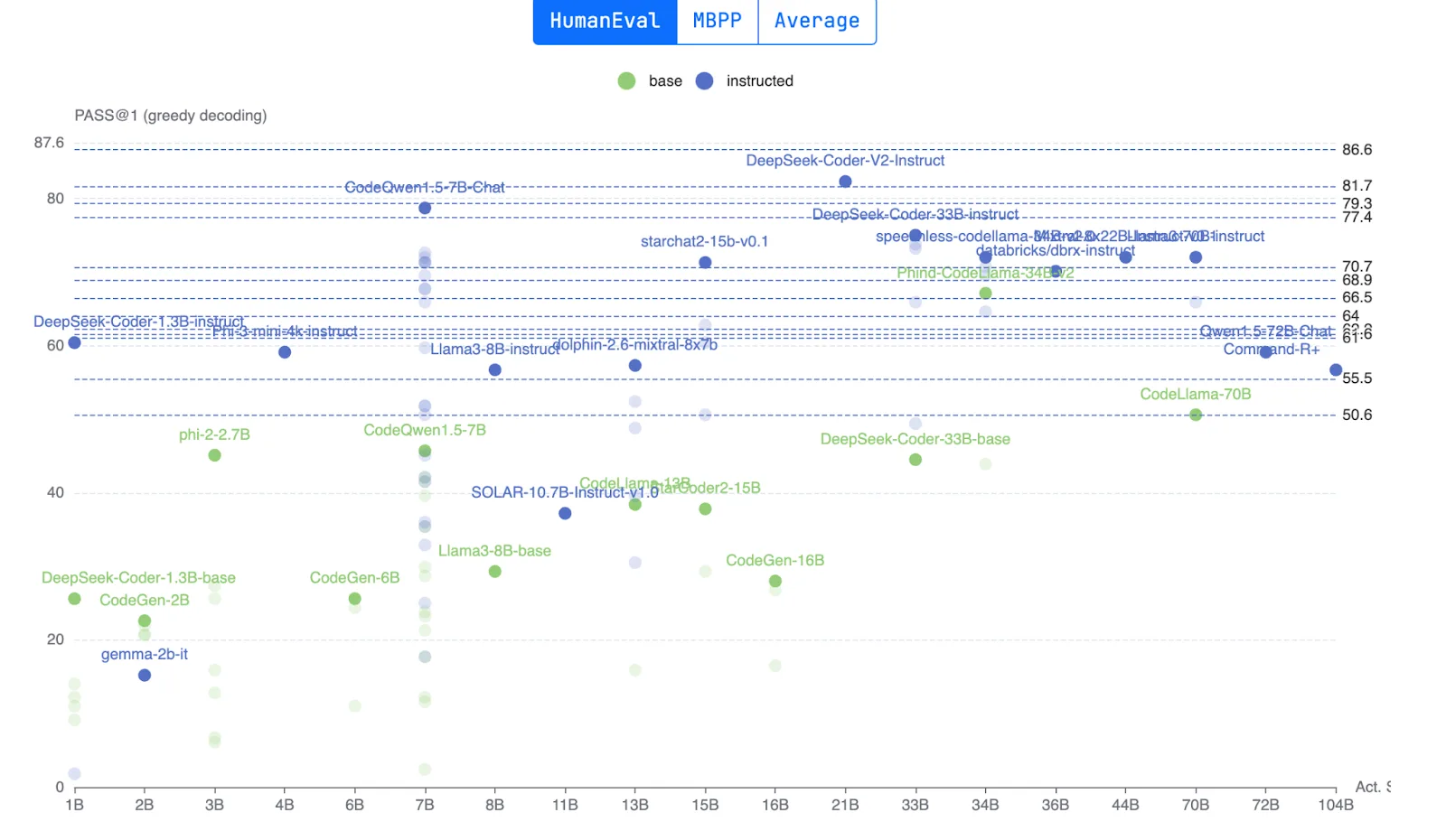
Here’s another pretty industry-specific leaderboard—EvaPlus focuses on coding and programming tasks and uses enhanced versions of existing benchmarks (HumanEval+ and MBPP+) to provide more thorough testing of code generation capabilities.
EvalPlus goes beyond just checking if the code compiles or has the correct syntax. It tests whether the code actually produces the correct output for a wide range of inputs, including edge cases, meaning unusual or extreme inputs that can reveal subtle bugs or limitations in the code.
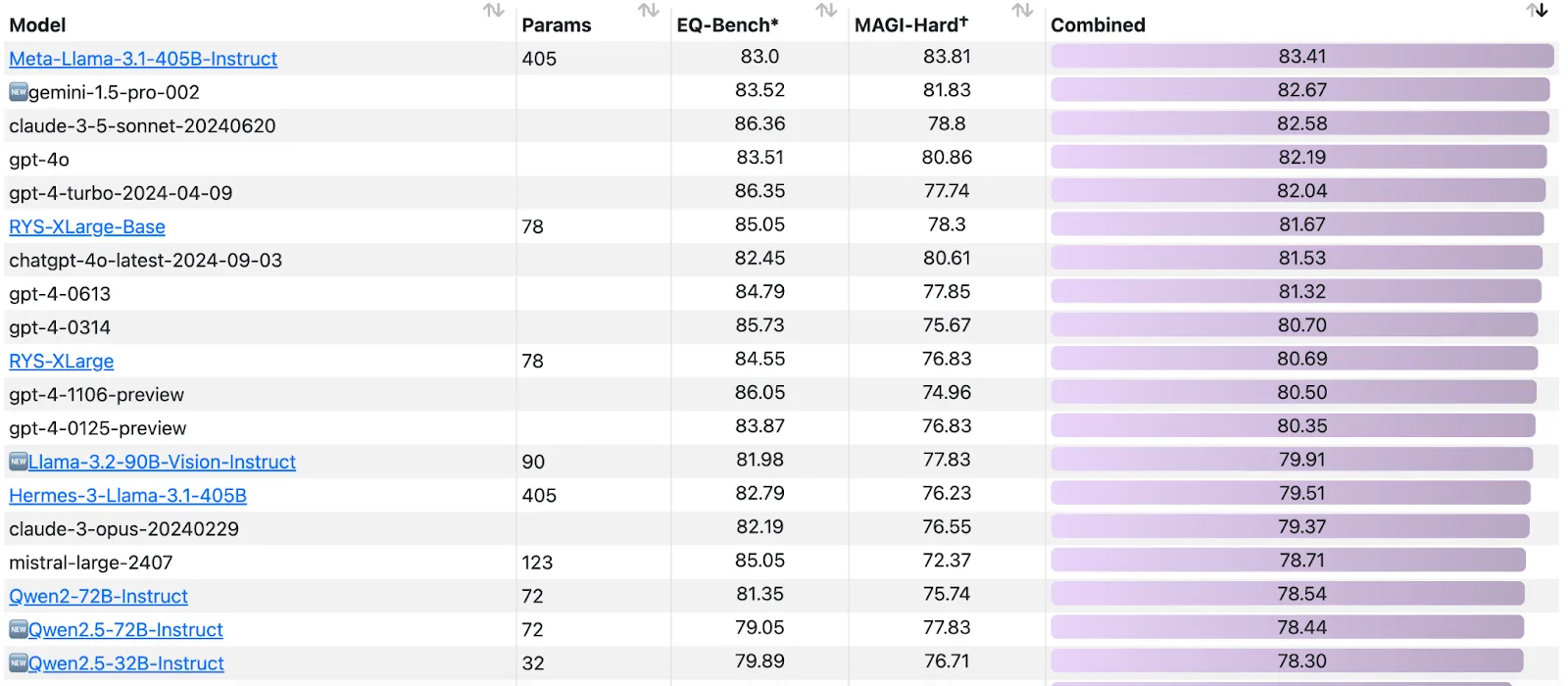
EQBench assesses LLMs' ability to understand complex emotions and social interactions in dialogues, specifically targeting the emotional intelligence of LLMs that is not commonly assessed by other platforms. Its scores correlate strongly with comprehensive multi-domain benchmarks like MMLU (r=0.97), suggesting it captures aspects of broad intelligence.
True, LLM leaderboards are invaluable for measuring and comparing the effectiveness of language models as they foster a dynamic environment for competition, setting standards that facilitate model development. However, these benchmarks are not perfect.
Multiple-choice tests for evaluating language models can be fragile, minor changes such as a difference in response order will lead to significant score variations. Data contamination, on the other hand, can occur when the models are trained on datasets that are already used by these benchmark models, resulting in varying model performance on different sites.
That is to say, if you’re looking for the best LLM tool to use, instead of relying on general leaderboards, create benchmarks tailored to your specific use case or application so that your results stay true to your specific needs.
To learn more about why you should explore the best LLM tools in the market and how to leverage them to accelerate your business growth, contact our Shakudo team. Our team is dedicated to providing you with valuable insights that help you make informed decisions and navigate the rapidly evolving landscape of AI technology. Let us guide you in discovering the most effective tools tailored to your specific needs!




















