

In this blog post, we're going to explore Apache Spark using Shakudo, a powerful combination for handling massive data sets and complex analytics tasks. We’ll cover everything from Spark's key features and architecture to using Ray on Spark and the benefits of dynamic clustering. By using the Shakudo platform, you get a fully managed and ready Apache Spark environment, a job scheduler, and an integration of various open-source tools to remove all DevOps from your data management.

Apache Spark is an open-source, distributed computing system optimized for speed, versatility, and scalability in processing vast datasets. Its design seeks to overcome traditional batch processing limitations, enabling more efficient large-scale data operations more swiftly and affordably.
It breaks down large data problems into manageable segments: code execution, hardware utilization, and data storage. Often, the result of these operations is a dataset far larger than what you started with, requiring significant storage and processing power.
Spark's solution stack comprises top-level libraries, such as Spark SQL and MLlib for machine learning tasks, all backed by the Spark core API. To deal with hardware limitations, Spark disperses the workload across multiple machines via frameworks like Kubernetes or EC2, effectively managing resources.
Shakudo enhances this by providing a fully managed Spark environment, taking care of resource allocation, scalability, and overall cluster management. This lets you focus more on solving problems and less on managing infrastructure. The result is a robust data pipeline, sharper predictions, and more value delivered to your organization.
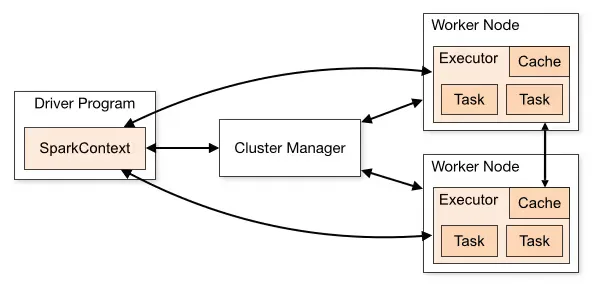
The diagram above illustrates the interactions and dependencies between the driver program, cluster manager, executor processes, and tasks within a distributed data processing environment. At its core, Apache Spark's architecture is composed of a driver program, executor processes, a cluster manager, and tasks, each serving unique roles to ensure seamless operation and efficient resource utilization.
To get started with Apache Spark, you can download the latest version from the official website or, for more complex applications, use a managed platform like Shakudo. Once you have Spark installed, you can start writing your first Spark application.
Here's a simple example of a Spark application written in Python, using the PySpark library:
In this example, we first import the necessary PySpark components and create a Spark session. Then, we load a CSV file into a DataFrame and perform a simple groupBy operation followed by a count. Finally, we display the top 10 results and stop the Spark session.
By combining the power of Apache Spark with the built-in functionalities of Shakudo, data engineers and data scientists can achieve unparalleled efficiency in processing, analyzing, and deriving insights from its data, without the need to create the underlying infrastructure. Let’s dive into two of the main Shakudo functionalities when it comes to Apache Spark and how to leverage the platform to handle complex data processing tasks.

Apache Spark is a powerful tool for large data processing. However, its capabilities can be amplified when paired with the right orchestration tool. Ray, an open-source project hailing from RISELab, is a tool that has made it remarkably easy to scale Python workloads that require heavy computation. It provides a unified interface for a wide range of applications, including machine learning and real-time systems. Its key feature is a dynamic task graph execution, enabling scheduling flexibility and high-level APIs. When combined with Spark through RayDP, it opens up a new world of performance, flexibility, and scalability.
RayDP brings together the immense data processing capabilities of Apache Spark and the high-performance distributed computing power of Ray. It ensures superior resource utilization by allowing Spark to share the same cluster resources with other Ray tasks. It also enhances productivity by enabling the writing of PySpark code and other Ray tasks in the same script, and improves interoperability with machine learning libraries like PyTorch and TensorFlow.
With one line of code, you can use Ray on Spark inside the Shakudo platform to experience a more simplified, efficient, and highly integrated approach to building end-to-end data analytics and AI pipelines. The following section will provide an overview of this functionality.
Dynamic clustering, or elastic/auto-scaling clustering, allows automatic adjustment of cluster size according to the workload, streamlining resource use and cost. In Apache Spark, this feature auto-scales executor instances, letting applications adapt to varying workloads without manual intervention.
Shakudo offers a fully managed Spark environment with built-in dynamic clustering. This not only scales executor instances as per processing requirements but it also enables the ability to spin up or shut down the cluster when processing halts, further optimizing resource utilization and cost savings.
The platform job scheduler assists in setting up recurring jobs, defining job dependencies, and monitoring applications. Shakudo also integrates with various modern open-source tools, making data application development simple and efficient
Increased Fault Tolerance: Dynamic clusters enhance resilience by auto-replacing failed executors, allowing continued processing despite node failures.

In this section, we’ll show a practical example of using Apache Spark to load, explore, and analyze Net Promoter Score (NPS) data to understand customer loyalty distribution using the Shakudo platform. We will demonstrate the benefits of harnessing the power of Spark in a fully managed environment, allowing you to focus on your data processing tasks while Shakudo takes care of cluster management and resource allocation.
In the Shakudo Platform, let’s navigate to the Sessions tab and click on Start a Session.
Choose the Ray Spark image from the list of available images.
Click Create to launch your new Ray Spark session.
Now that we have our Ray Spark session set up, we can create a new Spark application. In this example, we’ll use Python and the PySpark library to demonstrate a few steps to create a simple data processing task using the Shakudo platform.
For this code, we’ve collected the NPS data from various sources, and our primary aim is to understand the impact of each source on the NPS score. Essentially, we want to determine which sources generate the most promoters (high NPS scores) and which sources might need some improvement due to a lower NPS score.
To this end, we use this script to load the NPS data into a DataFrame for processing with PySpark. We chose PySpark for its scalability, making it ideal for handling potentially massive datasets in the future.
After importing the necessary libraries, we’ll need to import a function from the Shakudo library called hyperplane.ray_common to manage the Ray cluster and set the number of workers, CPU cores per worker, and RAM per worker for the Ray cluster. Click here to learn more about how to use Ray on Shakudo.
Now, let’s initialize our Spark session using RayDP with the specified configuration:
Now we have everything ready to start processing our dataset. The NPS score data is stored in a CSV file located at /root/data_nps_score_data_NPS.csv on our system. This file is then read into a PySpark DataFrame for further analysis:
After loading the data, we examine its structure, preview the content, and then proceed to grouping the data by using the ‘groupby(‘Source Type’).size()’ function. We essentially categorize the NPS scores according to their source, gaining insights into the number of responses from each. You can find the complete version of the code here.
After you’ve done your data processing, you can use this function to close your Ray cluster. This will release the resources back to the node pool and ensure that the distributed cluster is properly terminated.
Once the data processing notebook has been developed and tested, it can be scheduled to run automatically in a production setup by adding a pipeline.yaml file to build a pipeline. To learn more about pipeline YAML files, you can go to the create a pipeline job page.
To launch a pipeline job, we can go to the Shakudo Platform dashboard’s Jobs and fill the form with your project’s information. Here’s a quick tutorial on how to get started with jobs on Shakudo.
After successfully building your Apache Spark application on Shakudo, you can rely on the platform to handle all aspects of cluster management, resource allocation, and scaling, freeing you to concentrate on your data processing. Shakudo also effortlessly works alongside a variety of other open-source tools, giving you a versatile and compatible environment for your postmodern data needs.
Today we’ve highlighted how Spark’s strong features work hand-in-hand with Shakudo’s data management, rapidly turning large amounts of data into useful insights. When we bring Ray into this setup, we create a highly efficient system for building your data products. This combination works like a well-oiled machine, adapting to your needs, optimizing costs, and ensuring strong resilience when facing challenges.
But our journey doesn’t stop here. Shakudo offers a wide range of open-source tools, all ready to be used for your benefit. Therefore, it’s time to start your adventure with Shakudo! Whether you are an experienced data engineer or a new data scientist, Shakudo is ready to be your trusted partner. Try it out today, and let Shakudo handle the complex aspects of your big data tasks, freeing you to focus on finding the hidden insights in your data.




















